






MedMNIST是一个由10个预处理的医学开放数据集组成的集合,从覆盖主要数据模态的选定源(例如X射线、OCT、超声、CT),各种分类任务(二元/多类、有序回归和多标签)和数据规模(从100到100000)。MedMNIST被标准化为对轻量级的28×28图像执行分类任务,这不需要背景知识。它涵盖了医学图像分析中的主要数据模式,在数据规模(从100到100000)和任务(二元/多类、有序回归和多标签)上是多样化的。MedMNIST可用于教育目的、快速原型设计、多模式机器学习或医学图像分析中的AutoML。此外,MedMNIST Classification Decathlon旨在在所有10个数据集上对AutoML算法进行基准测试。

主要功能
教育性:我们的多模态数据来自具有知识共享(CC)许可证的多个开放医学图像数据集,易于用于教育目的。
标准化:数据被预先处理成相同的格式,这对用户来说不需要背景知识。
多样性:多模态数据集涵盖了不同的数据量表(从100到100000)和任务(二元/多类、有序回归和多标签)。
重量轻:28×28的小尺寸便于快速成型和试验多模式机器学习和AutoML算法。
dataset.py:PyTorch数据集和MedMNIST的数据加载器。
models.py:ResNet-18和ResNet-50型号。
evaluator.py:标准化评估功能。
info.py:MedMNIST的每个子集的数据集信息dict。
train.py:在论文中重现基线结果的训练和评估脚本。
getting_started.ipynb:使用jupyter笔记本探索MedMNIST数据集。它仅用于快速探索,即不提供完整的培训和评估功能(请参阅train.py)。
setup.py:将medmnist作为模块安装的脚本
PathMNIST基于之前的一项研究预测结直肠癌组织学切片的生存率,该研究
提供了一个由苏木精和伊红染色的100000个非重叠图像块组成的数据集(NCT-CRC-HE-100K)组织学图像和测试数据集(CRC-VAL-HE-7K)来自不同临床中心的7100个图像补丁。9种类型涉及的组织,从而产生多类分类任务我们将3×224×224的源图像调整为3×28×28,并将NCT-CRC-HE-100K拆分为训练和
以9:1的比例进行验证。
ChestNIST基于NIH-ChestXray14数据集,数据集包括112120个
30805例独特的患者用文本挖掘14种疾病图像标签,可以公式化为多标签二进制分类任务。我们使用官方数据分割,并调整将1×1024×1024的源图像转换为1×28×28。
DermaMNIST基于HAM10000常见色素性皮肤病变的多源皮肤镜图像采集。数据集由101015个组成皮肤镜图像标记为7个不同类别,作为多类分类任务。我们将图像分成训练集、验证集和测试集,比例为7:1:2。来源将3×600×450的图像调整为3×28×28。
OCTNIST基于109309的先前数据集视网膜的有效光学相干断层扫描(OCT)图像
疾病。涉及4种类型,导致多类分类任务。我们将源训练集按比例拆分的9:1转换为训练和验证集,并使用其来源验证集作为测试集。源图像为单通道,其大小为(384−1536)×(277−512);我们中心裁剪图像并将其调整为1×28×28。
PneumoniaMNIST基于先前的数据集5586张儿科胸部X光图像。任务是二进制类肺炎和正常的分类。我们分开了来源将比例为9:1的训练集纳入训练和验证集,并将其源验证集用作测试集。来源图像为单通道,其大小为(384−21916)×
(127−2713);我们居中裁剪图像并调整其大小×28。
RetinaMNIST基于DeepDRiD1600幅视网膜眼底图像。任务是有序回归
用于糖尿病视网膜病变严重程度的5级分级。我们分手了源训练集以9∶1的比例进行训练验证集,并将源验证集用作测试集。这个对3×1736×1824的源图像进行中心裁剪调整大小为3×28×28。
BreastMNIST基于780个乳房的数据集超声波图像。它分为三类:正常,良性和恶性。当我们使用低分辨率图像时结合法线将任务简化为二元分类和良性分类为阳性,并将其与恶性分类为消极的我们以7∶1∶2的比例分割源数据集进入培训、验证和测试集。的源图像1×500×500的大小调整为1×28×28
OrganMNIST{轴向、冠状、矢状}基于肝脏肿瘤的三维计算机断层扫描(CT)图像
细分基准(LiTS)。我们使用边界框另一项研究[17]对11个身体器官的注释,以获得器官标签。三维图像的Hounsfield单位(HU)被转换为具有腹窗的灰度;我们
然后在轴向/冠状/矢状视图(平面)中从3D绑定框的中心切片裁剪2D图像。这个
只有OrganMNIST的差异{轴位、冠状位、矢状位}是观点。图像的大小调整为1×28×28
AutoML方法
我们还在MedMNIST Classification Decathlon上选择了几种AutoML方法:auto sklearn作为典型统计机器学习的开源AutoML工具的代表,AutoKeras作为深度神经网络的开源AutoML工具的代表,
以及作为商业黑盒AutoML工具代表的Google AutoML Vision。
auto-sk-learn自动搜索scikit学习包中的算法和超参数。我们根据数据集的规模设置了搜索适当模型的时间限制。规模<10000的数据集的时间限制为2小时,[10000,5000]的数据集为4小时,>50000的数据集中为6小时。我们将28×28的图像展平为一维,并提供784的重塑一维数据和相应的标签,以供自动sklearn拟合。
基于Keras包的AutoKeras搜索深度神经网络和超参数。对于每个数据集,我们将最大试验设置为20,将历元设置为20。它尝试了20个不同的Keras模型,每个模型训练20个时期。我们根据验证集上的最高AUC分数来选择最佳模型。
Google AutoML Vision2是在Google Cloud上提供的一个商业AutoML工具。我们在Google AutoML Vision上训练Edge可导出模型,并将训练后的量化模型导出为TensorFlow Lite格式以进行离线推理。
我们根据数据规模设置每个数据集的节点小时数,规模在1000左右的数据集为1个节点小时,规模在10000左右为2个节点小时;规模在100000左右为3个节点小时
evaluation
ROC曲线下面积(AUC)和准确度(ACC)被用作评估指标。AUC是用于评估连续预测得分的无阈值度量,而ACC在给定阈值(orarg-max)的情况下评估离散预测标签。AUC对类别失衡的敏感性不如ACC。在我们的数据集上没有严重的类别失衡,因此ACC也可以作为一个很好的指标。尽管还有许多其他指标,但为了评估的简单性和标准化,我们只选择了AUC和ACC。我们在本文中报告了每个数据集的AUC和ACC,而
鼓励数据用户分析10个数据集的平均性能,以对他们的AutoML方法进行基准测试。
总体性能
表2中报告了这些方法的总体性能。谷歌AutoML Vision总体表现良好,但即使与基准ResNet-18和ResNet-50相比,它也不可能总是获胜。auto-sklearn在大多数数据集上的性能都很差,这表明典型的统计机器学习算法在我们的医学图像数据集上不能很好地工作。AutoKeras在大规模数据集上表现良好,但在小规模数据集上相对较差。鉴于没有一种算法能够在所有10个数据集上很好地泛化,因此探索在不同的数据模式、任务和规模上很好泛化的AutoML算法可能是有趣和实用的。
数据分割的性能分析我们还分析了训练、验证和测试数据分割的过拟合/欠拟合问题。如图所示在图2中,算法倾向于以小规模覆盖数据集。Google AutoML Vision很好地控制了过拟合问题,并观察到自动sklearn存在严重的过拟合。我们可以推断,学习算法的适当还原偏差是至关重要的。MedMNIST上的正则化技术也值得探索,例如,数据增强、模型集成、优化算法。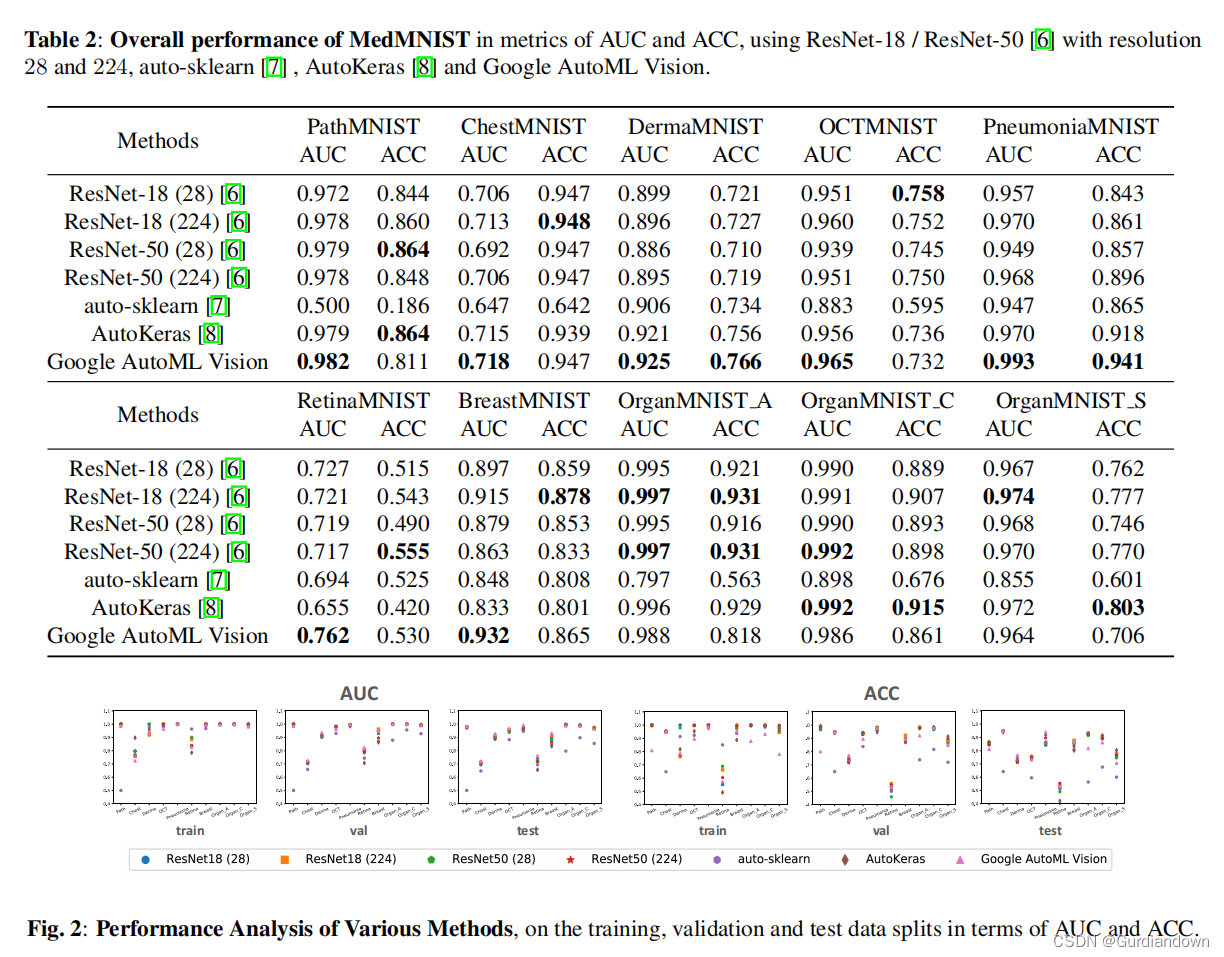
数据集
请通过Zenodo下载数据集。您也可以使用我们的代码自动下载。
建议使用我们的数据集代码来解析.npz文件;但是,您可以自由地使用自己的代码(包括但不限于Python)解析它们,因为它们只是标准的NumPy序列化文件。
数据集包含几个子集,每个子集(例如,pathmnist.npz)由6个键组成:train_images、train_labels、val_images,val_labels,test_images和test_labels。
train_images/val_images/test_images:N x 28 x 28 x 3用于RGB,N x 28×28用于灰度。N表示样本的数量。
train_labels/val_labels/test_labels:N x L。N表示样本的数量。L表示任务标签的数量;对于单标签(二进制/多类)分类,L=1,并且{1,2,3,4,5,…,C}表示类别标签(对于二进制,C=2);对于多标签分类L=1,例如,L=14为chestmnist.npz。
"pathmnist”:{
“说明”:“PathMNIST:一个基于先前研究的数据集,用于预测结直肠癌组织学切片的存活率,该数据集提供了一个数据集NCT-CRC-HE-100K,其中包含来自苏木精和伊红染色组织学图像的100000个非重叠图像补丁,以及一个测试数据集CRC-VAL-HE-7K,其中包括来自不同临床中心的7180个图像补丁。共涉及9种组织,由此产生了一个多类分类任务。我们将3 x 224 x 224的源图像调整为3 x 28 x 28,并将NCT-CRC-HE-100K按9:1的比例拆分为训练和验证集。”,
“url”:“https://zenodo.org/record/4269852/files/pathmnist.npz?download=1”,
“MD5”:“a8b06965200029087d5bd730944a56c1”,
“任务”:“多类”,
“标签”:{
“0”:“脂肪”,
“1”:“背景”,
“2”:“碎屑”,
“3”:“淋巴细胞”,
“4”:“粘液”,
“5”:“平滑肌”,
“6”:“正常结肠粘膜”,“7”:“癌相关基质”,“8”:“结肠腺癌上皮”}

















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









