







 本文介绍了小样本学习(Few-shot Learning)的概念及其在图像领域的应用,探讨了注意力机制、LSTM在小样本学习中的作用。文章详细阐述了小样本学习的三种方法:基于度量的学习(包括孪生网络、匹配网络、原型网络)、基于模型的学习和基于优化的学习,并列举了相关论文和方法的优缺点。通过学习如何在少量样本中快速提取特征并进行分类,小样本学习旨在模仿人类的学习能力,解决机器学习模型在新类别上的泛化问题。
本文介绍了小样本学习(Few-shot Learning)的概念及其在图像领域的应用,探讨了注意力机制、LSTM在小样本学习中的作用。文章详细阐述了小样本学习的三种方法:基于度量的学习(包括孪生网络、匹配网络、原型网络)、基于模型的学习和基于优化的学习,并列举了相关论文和方法的优缺点。通过学习如何在少量样本中快速提取特征并进行分类,小样本学习旨在模仿人类的学习能力,解决机器学习模型在新类别上的泛化问题。
最近在做华为杯的竞赛,涉及小样本学习,总结一下相关的知识及论文
小样本学习(Few-shot Learning)在图像领域的研究现状
1.introduction
人类具有通过极少量样本识别一个新物体的能力,如小孩子只需要书中的个别图片,就可以认识什么是“苹果”,什么是“草莓”。研究人员希望机器学习模型在学习了一定类别的大量数据后,对于下游任务中遇到的新类别,只需要少量的样本就能快速学习,实现“小样本学习”。
传统的小样本学习考虑训练数据与测试数据均来自于同一个域。如果下游任务中包含了未知域, 则传统小样本学习方法效果不理想。这就是这次竞赛要解决的问题.
one-short learning : 待解决的问题只有少量的标注数据,先验知识很匮乏,迁移学习属于one-short learning的一种
zero-short learning: 这个种情况下完全没有标注数据,聚类算法等无监督学习属于zero-short learning的一种
小样本学习(Few-shot Learning) 是 元学习(Meta Learning) 在监督学习领域的应用。 Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。
训练过程中,每次训练(episode)都会采样得到不同 meta-task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 meta-task 中 task 相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。
Few-shot Learning 模型大致可分为三类:Mode Based,Metric Based 和 Optimization Based。

1.1注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
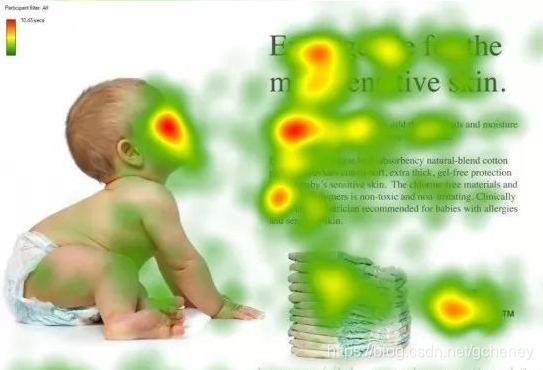
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
小样本学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
注意力机制的基本思想和实现原理
1.2 LSTM(Long short-term memory)
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示:
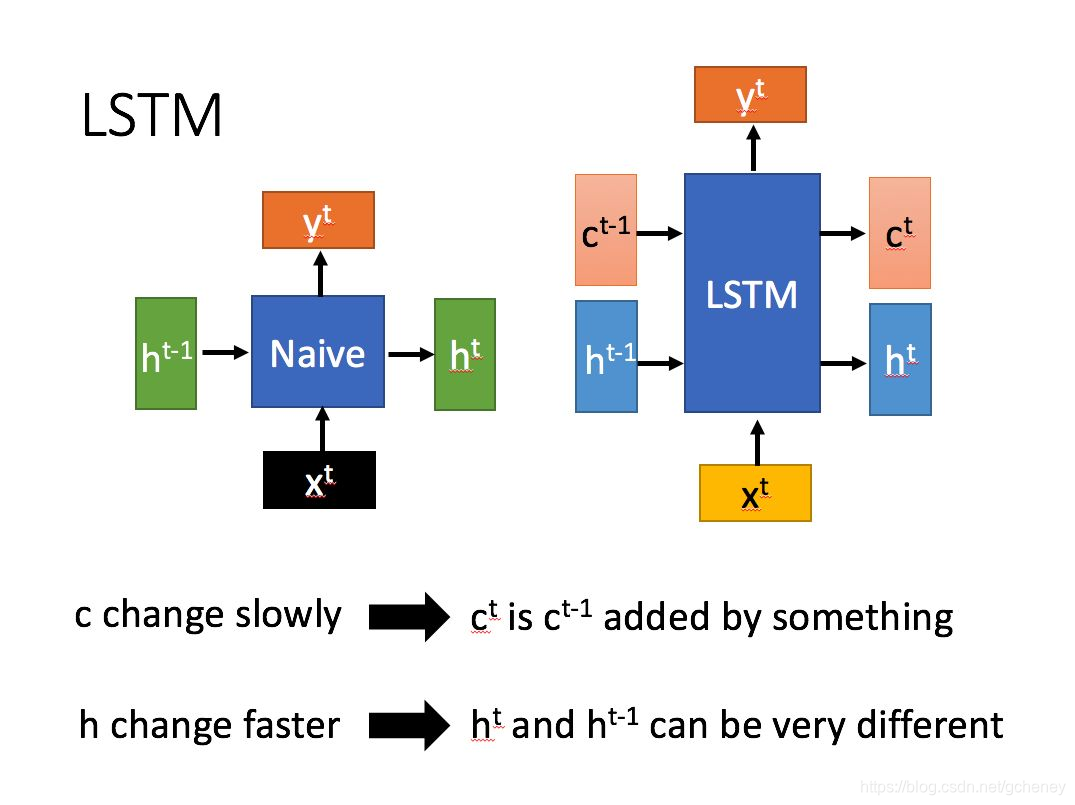
LSTM基本思想和实现原理
LSTM的内部结构,通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
2. 小样本学习(Few-shot Learning)
2.1基于度量的小样本学习(Metric Based)(主流方法)
Metric Based 方法通过度量 batch 集中的样本和 support 集中样本的距离,借助最近邻的思想完成分类。
2.1.1孪生网络(Siamese Network)
- 孪生 是指网络结构中的Network_1和Network_2
这两个网络的结构一般是相同的,并且参数是共享的 即参数是一致的。
还有一种网络叫伪孪生网络 直观理解就是左右两边的网络结构是不同的。 - 在图中的网络中 左右两个网络的作用是用于提取输入图片的特征。特征提取器
比如在人脸领域,输入两个人的人脸图片信息,两个网络分别提取这两个人脸图片中不同部分。
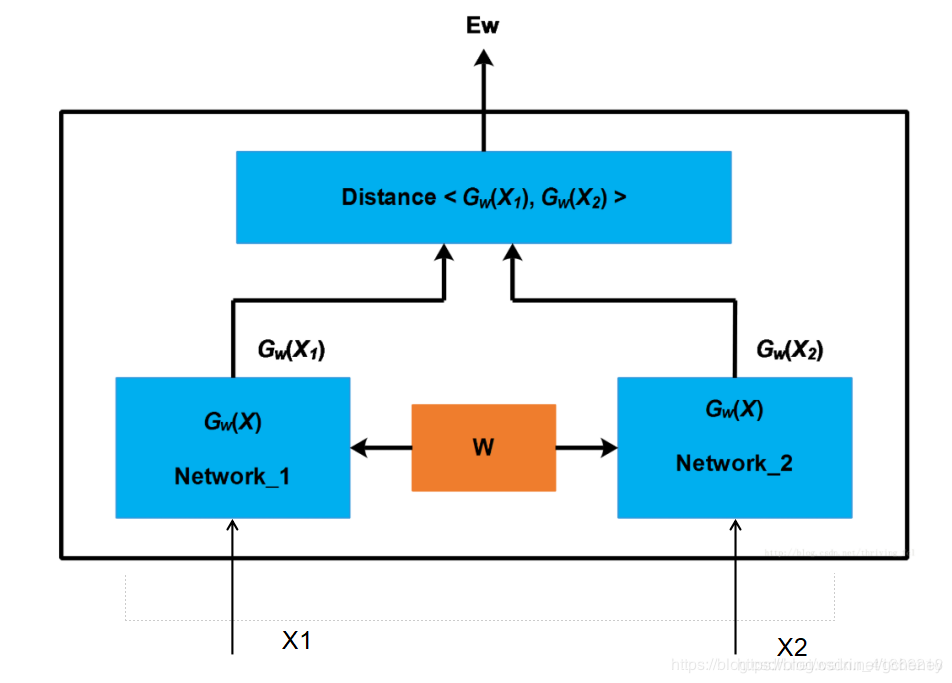
- 通过使用两个网络 提取出来了两个图片的特征 接下来计算特征之间的差距distance。之后返回网络的输出结果 :这两张图片是否属于同一人。
关于这个网络结构的损失函数 也可理解为 计算distance的地方设定为:
G w ( P T ) = G w ( X 1 , X 2 ) Gw(PT) = Gw(X1,X2) Gw(PT)=Gw(X1,X2)
指两个特征上属于同一个人的误差
G w ( P F ) = G w ( X 1 , X 2 ) Gw(PF) = Gw(X1,X2) Gw(PF)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7464
7464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









