







Zero-shot 和 Few-shot 是自然语言处理(NLP)和机器学习领域中两种重要的学习范式,主要用于描述模型在面对未见过的任务或数据时的表现。它们的区别和联系如下:
1. Zero-shot 学习
(1)定义
Zero-shot 学习指的是模型在没有针对特定任务进行任何训练的情况下,直接完成新任务的能力。换句话说,模型从未见过与目标任务相关的标注数据,但仍然能够通过其预训练的知识推断出答案。
(2)特点
无需任务特定数据:模型完全依赖于预训练阶段学到的通用知识。
任务泛化能力强:适用于跨领域、跨任务的应用场景。
典型例子:
给定一个任务“将英文翻译成法语”,即使模型在预训练阶段只学过其他语言对(如英语-西班牙语),它仍然可以通过语言理解能力完成翻译。
让模型回答问题:“什么是光合作用?”——即使它从未被专门训练过回答科学问题。
(3)优势
不需要额外的数据标注,节省时间和成本。
能够快速适应新任务,适合开放域应用场景。
局限性
性能通常不如经过专门训练的模型,尤其是在复杂任务上。
对模型的预训练质量和知识覆盖范围要求较高。
2. Few-shot 学习
(1)定义
Few-shot 学习指的是模型在仅提供少量标注数据(通常是几个到几十个样本)的情况下,快速适应新任务的能力。这种学习方式介于 Zero-shot 和传统监督学习之间。
(2)特点
少量标注数据:模型通过少量示例学习任务的模式。
上下文学习(In-context Learning):模型利用输入中的少量示例作为上下文,动态调整其行为。
典型例子:
给模型提供几个情感分类的例子:
输入:这部电影太棒了! -> 输出:正面
输入:我觉得很失望。 -> 输出:负面
输入:今天的天气真好! -> 输出:正面
然后让模型对新句子进行分类:“我讨厌这个产品。” -> 输出:负面。
(3)优势
在少量数据支持下,性能显著优于 Zero-shot。
更灵活,能够快速适应新任务。
对标注数据的需求远低于传统监督学习。
局限性
仍然需要少量标注数据,无法完全摆脱数据依赖。
性能可能受限于示例的质量和数量。
3. 区别
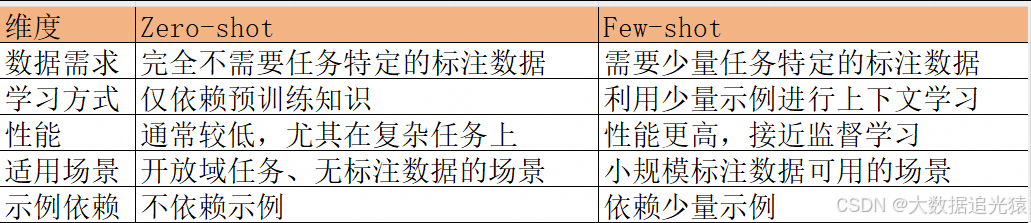
4. 联系
(1)共同点:
- 基于预训练模型:两者都依赖于大规模预训练模型(如 GPT、T5、BERT 等),这些模型在大量数据上进行了训练,具备一定的通用知识。
- 减少数据依赖:相比于传统监督学习,Zero-shot 和 Few-shot 都显著减少了对标注数据的需求。
- 任务泛化能力:两者都强调模型的泛化能力,能够在未见过的任务上表现良好。
(2)技术基础相同:
- 两者的核心机制都是通过预训练模型的参数化知识来完成任务。
- Few-shot 可以看作是 Zero-shot 的扩展:在 Zero-shot 的基础上,通过少量示例进一步引导模型的行为。
(3)应用场景互补:
- 如果完全没有标注数据,可以使用 Zero-shot。
- 如果有少量标注数据,可以使用 Few-shot 来提升性能。
5. 实际应用中的选择
选择 Zero-shot:
- 当任务数据完全不可得,或者任务种类繁多且标注成本过高时。
- 例如:跨语言翻译、开放域问答、文本生成等。
选择 Few-shot:
- 当有少量标注数据可用,并且希望在性能和成本之间取得平衡时。
- 例如:情感分析、文本分类、命名实体识别等。
6. 总结
- Zero-shot 强调模型的通用性和无数据依赖性,适合完全无标注数据的场景。
- Few-shot 强调模型在少量数据支持下的快速适应能力,适合有少量标注数据的场景。
- 两者的联系在于都依赖预训练模型的强大泛化能力,区别在于是否使用少量示例来引导模型行为。
在实际应用中,可以根据任务需求和数据可用性选择合适的学习范式,甚至结合两者的优势(如先用 Zero-shot 初始化,再用 Few-shot 微调)。


















 3026
3026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









