






随着 AI 大模型的普及,流式输出(SSE)已成为开发者的标配需求。传统的接口调试方式往往效率低下,难以实时呈现 AI 的响应过程。 Apifox 这次重大更新,进一步增强了 SSE 调试功能,对 AI 接口做了专门的优化。一个全新的解决方案,支持主流 AI 模型(OpenAI、Gemini、Claude)的流式响应,如 DeepSeek R1,Apifox 还能展示在生成答案前的思考过程。
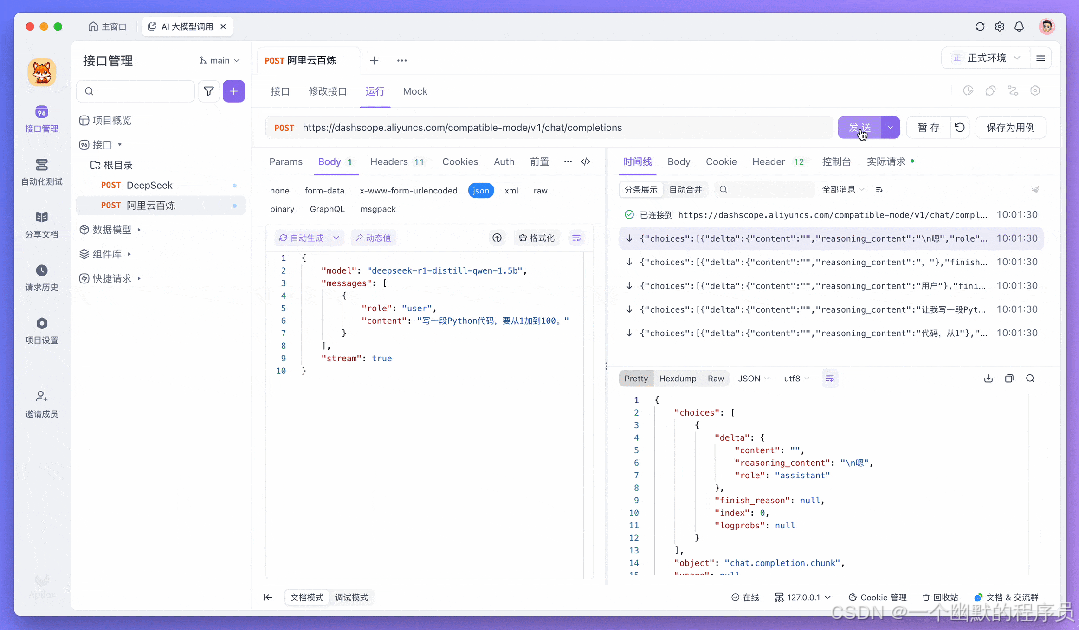
常见 AI 大模型的 API 都支持流式输出,以便让用户可以实时看到 AI 的回复,而无需长时间等待。AI 流式输出一般遵循 SSE(Server-Sent Events)格式。为 AI 模型调试提供了极大的便利。
下载最新版 Apifox,最新版体验一下 SSE!
如何调试 AI 接口?
简单的三步,只要你在 Apifox 中发起 HTTP 请求,调用常见的 AI 模型(deepseek、OpenAI、Gemini、Claude等)Apifox 就会自动合并为可读文本,实时以自然语言呈现响应。
1.新建接口
你可以填写任一 AI 模型的接口地址,并配置相应的 API Key。比如 DeepSeek 的 API,你可以将下面的 cURL 导入到 Apifox,注意stream字段的值需要为true:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer {{API_KEY}}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
{"role": "assistant", "content": "春风拂面柳丝长..."},
{"role": "user", "content": "请继续补充第二、三和四段"}
],
"stream": true }'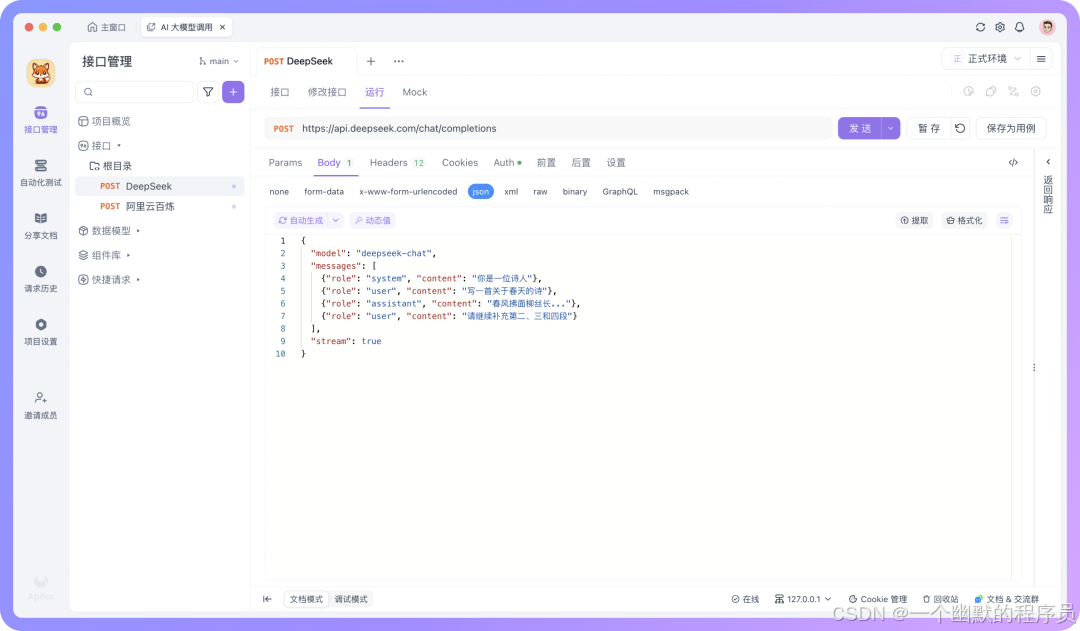
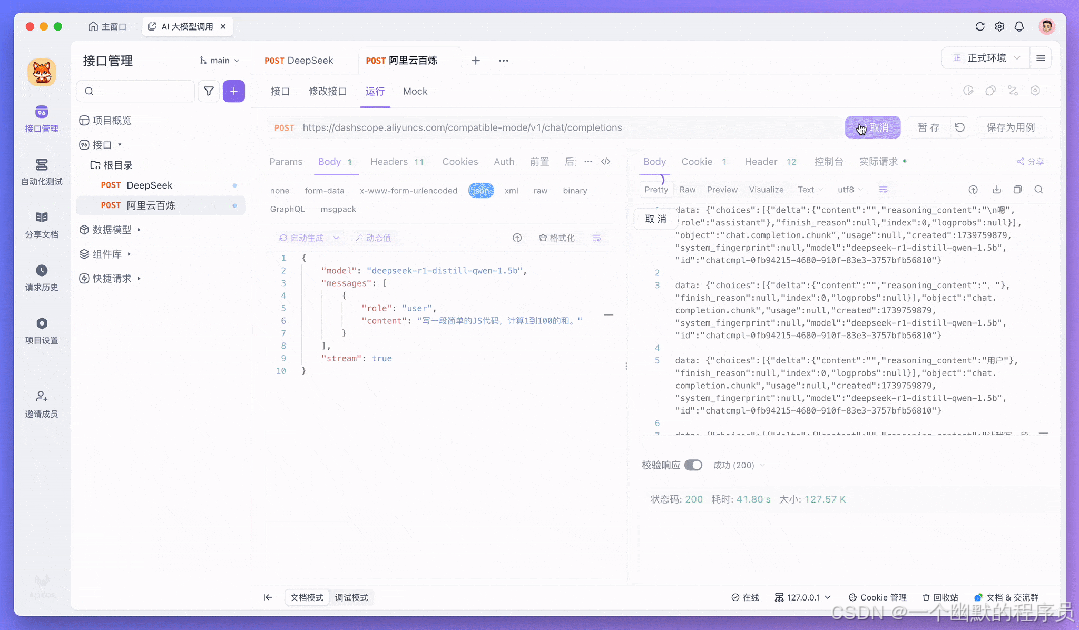
2.发送请求
发送请求后,Apifox 会自动识别接口返回的Content-Type是否包含text/event-stream。如果包含,系统会自动将响应解析为 SSE 事件并进行流式输出。
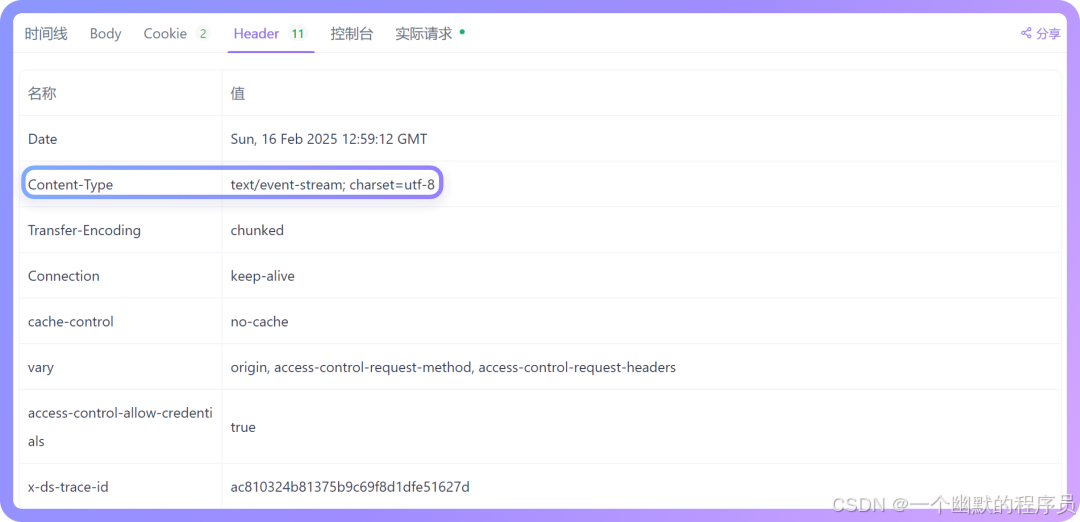
3.查看实时响应
在「时间线」视图中,你将看到实时滚动的流式响应内容。事件流会自动合并成可读文本,直观地呈现在响应面板中。
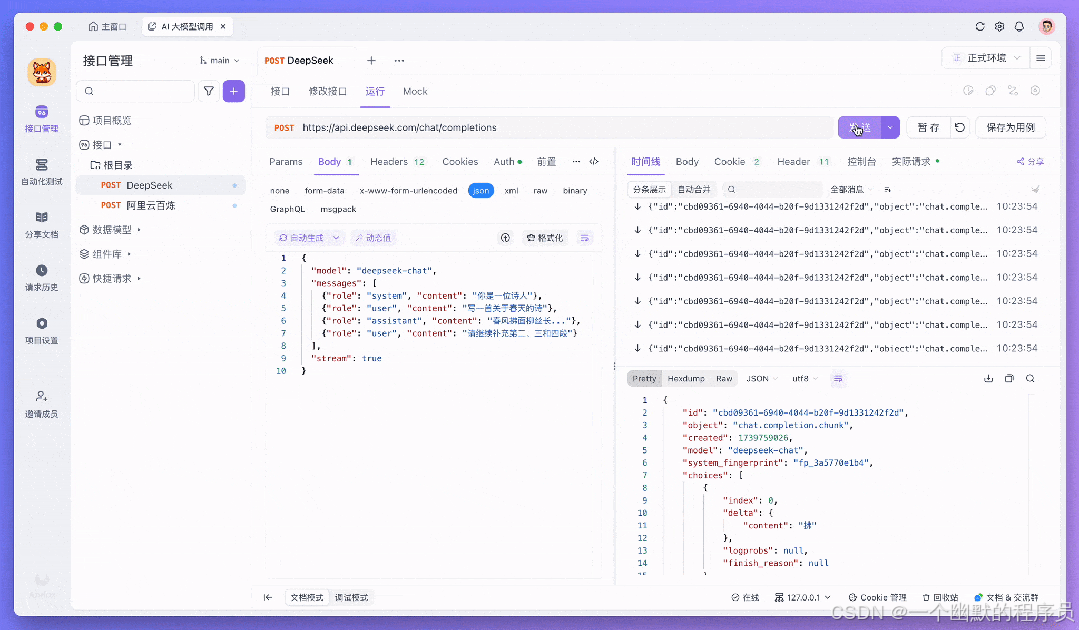
在 DeepSeek R1 等先进模型中,新增「时间线」功能,全方位展示 AI 推理过程。用户可实时追踪模型思考轨迹,大幅提升在调试 AI 接口时候可视化,更直观了解推理的过程。
总结
通过创新的流式响应自动合并技术,开发者可以实时可视化 AI 模型的推理过程。这不仅显著提升了 AI 接口调试的效率,更为开发者提供了前所未有的技术洞察。
SSE 流式调试,Apifox 让 AI 模型调试变得更加直观和高效。现在更新你的 Apifox,开启更智能的技术探索之旅。

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









