






Chapter 5 神经网络-机器学习-周志华
5.1神经元模型
- 神经网络:具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
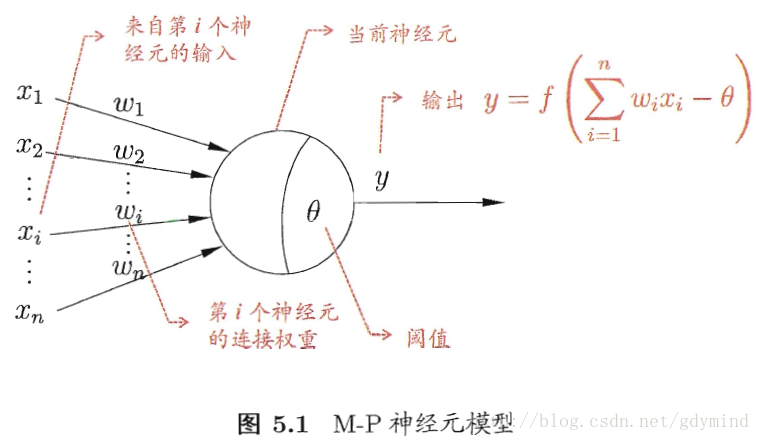
- 神经元模型:一个神经元收到的刺激超过阈值(threshold/bias),它就会被激活。概括为M-P神经元模型:n个带权输入
→
与threshold比较
→
激活函数处理产生输出。
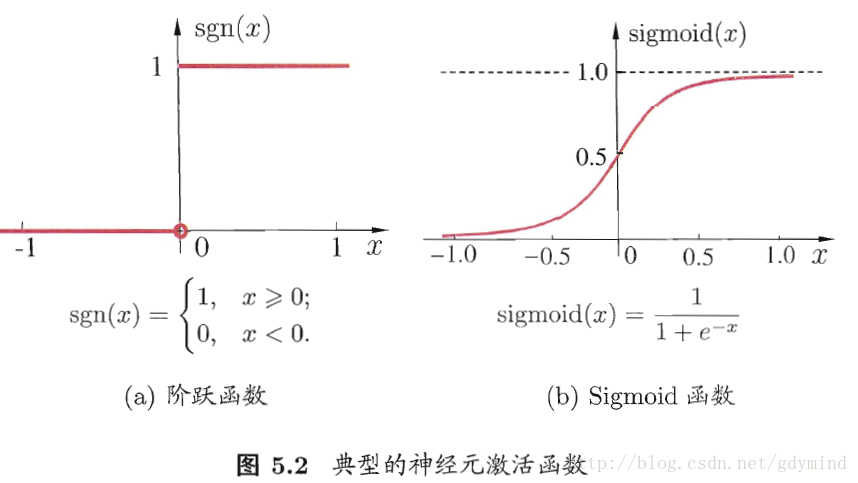
- 激活函数中1代表兴奋,0代表不兴奋。理想中激活函数位阶跃函数,为方便处理用连续的Sigmoid函数。
- 神经网络:神经元按一定层次结构连接。
- 神经网络可以视为包含了许多参数的数学模型,由若干函数(如 yj=f(∑iwixi−θj) )相互嵌套得到。
5.2 感知机与多层网络
感知机
- 感知机有两层神经网络,输出层为M-P神经单元——“阈值逻辑单元”。
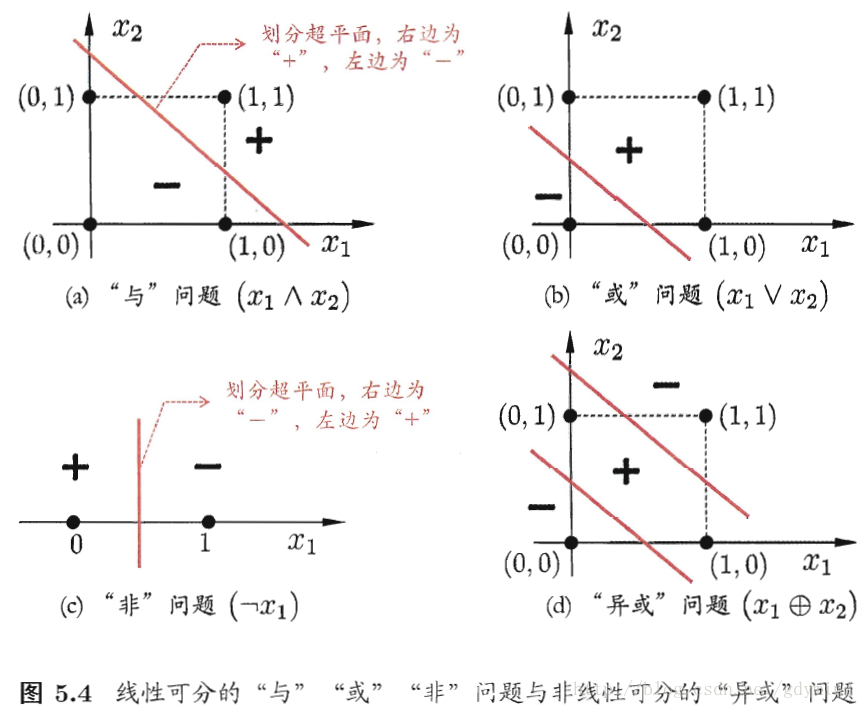
- 各神经元的 ω 和 θ 取适当的值,可以实现逻辑与、或、非运算。
- 给定训练集, ω 和 θ 可以通过学习得到。 θ 可视为固定输入为1的哑结点(dummy node)。
- 感知机的学习规则:
- 当前训练样例为(x,y),当前感知机输出位 y^ ,则权重调整为:
- ωi←ωi+Δωi , Δωi=η(y−y^)xi
- η 为学习率(learning rate)
- 感知机只有输出层神经元进行激活函数处理,即只有一层功能神经元(functional neuron)。
- 线性可分:存在线性超平面将两类模式分开。
- 若两类模式
- 线性可分(如与、或、非),感知机的学习过程会收敛(vonverge);
- 若线性不可分(如异或),则会发生振荡(fluctuation),不能稳定。
多层网络
- 解决非线性可分问题要使用多层功能神经元。
- 隐层或隐含层(hidden layer):输出层与输入层之间的一层神经元。
- 隐含层和输出层都具有激活函数。
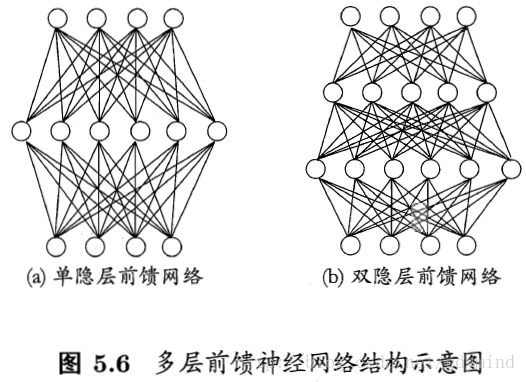
- 多层前馈神经网络(multi-layer feedforward neural networks):
- 每层神经元与下层完全互连
- 同层间无连接
- 无跨层连接
- 输入层神经元的唯一作用是接受输入,不进行函数处理
- 隐层和输出层包含功能神经元
- 神经网络的学习过程:根据训练数据调整神经元之间的“连接权”(connection weight),以及每个功能神经元的阈值。
5.6 深度学习
- 深度学习(deep learning)是很深层的神经网络。其提高容量的方法是增加隐层数目,这比增加隐层神经元数目更有效,这样不但增加了拥有激活函数的神经元数目,而且增加了激活函数嵌套的层数。
- 该模型太复杂,下面给出两种节省开销的训练方法:无监督逐层训练、权共享。
- 无监督逐层训练(unsupervised layer-wise training):
- 预训练(pre-training):每次训练一层,将上层作为输入,本层结果作为下层的输入。
- 微调训练(fine-training):预训练结束后的微调。
- 可视为将大量参数分组,每组先找到好的设置,基于局部较优进行全局寻优。
- 权共享(weight sharing):让一组神经元使用相同的连接权。这在卷积神经网络(Convolutional Neural Network,CNN)发挥了重要作用。















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









