







文章目录
一、k近邻算法
- 定位:k近邻法, 英文为k-nearest neighbor, 简称k-NN,是一种基本分类与回归算法。
- 原理:k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。
- 基本要素:距离度量、k值的选择、分类决策规则
- 由来:1968年由Cover和Hart提出。
- 算法


二、k近邻模型
(一)模型==>距离度量+k值的选择+分类决策规则
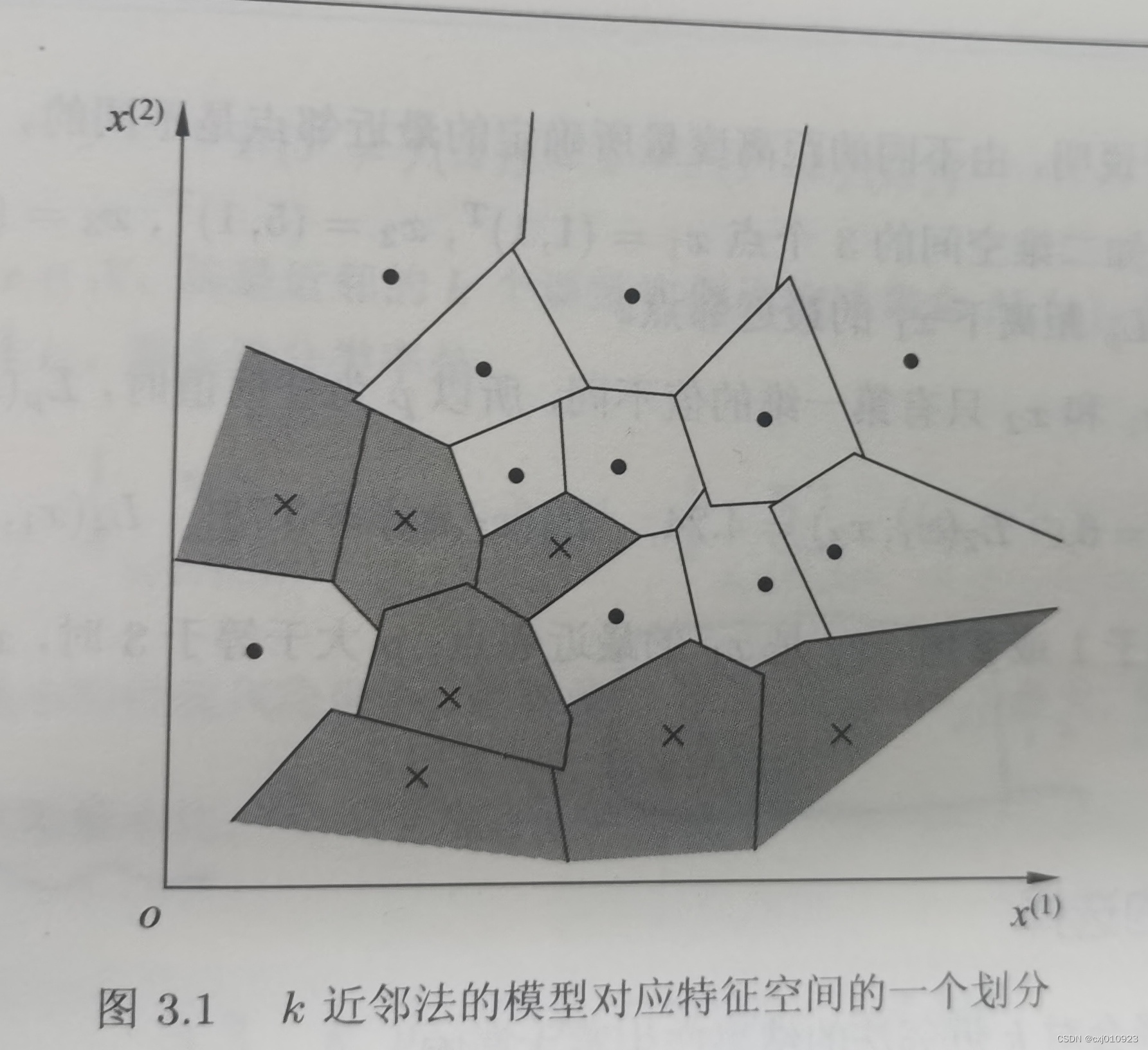
特征空间中,对每个训练实例点xi,距离该点比其他点更近的所有点组成一个区域,叫做单元cell。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。最近邻法将实例xi的类yi作为其单元中所有点的类标记class label。二维特征空间划分图如下:
(二)距离度量

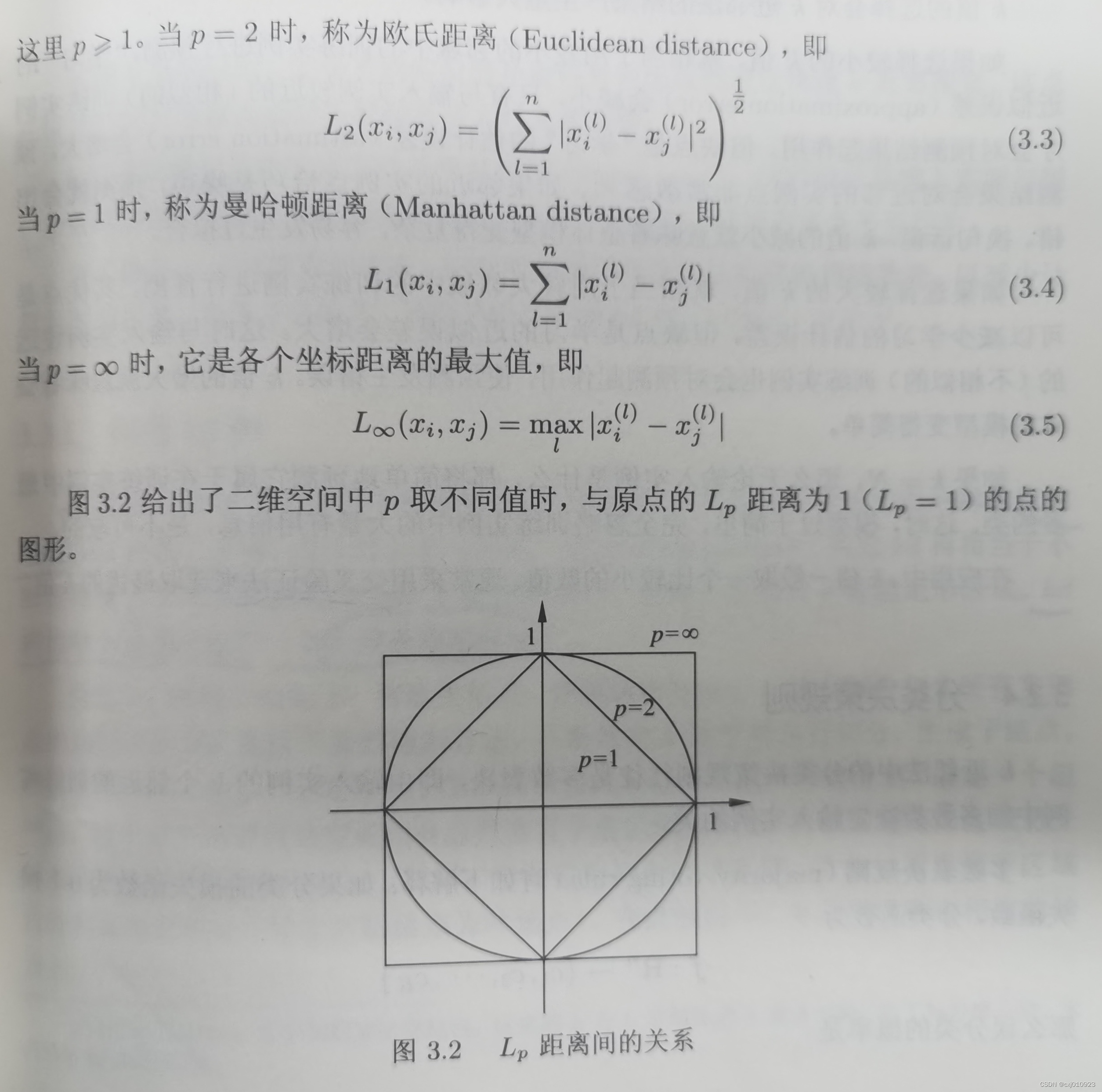
(三)k值的选择
- k值小,整体模型变得复杂,容易产生过拟合
- k值大,整体模型变得简单,容易产生欠拟合
- 在应用中,k值一般取一个比较小的值。通常采用交叉验证法来选取最优的k值。
(四)分类决策规则


三、k近邻法的实现:kd树
- k近邻法主要考虑的问题是:如何对训练数据进行快速k近邻搜索。
- 实现方法(有很多,但书中只提及了两种)
- 线性扫描 linear scan(但当训练集很大时,计算非常耗时,不可行)
- kd树 kd tree (提高k近邻搜索的效率,减少计算距离的次数)
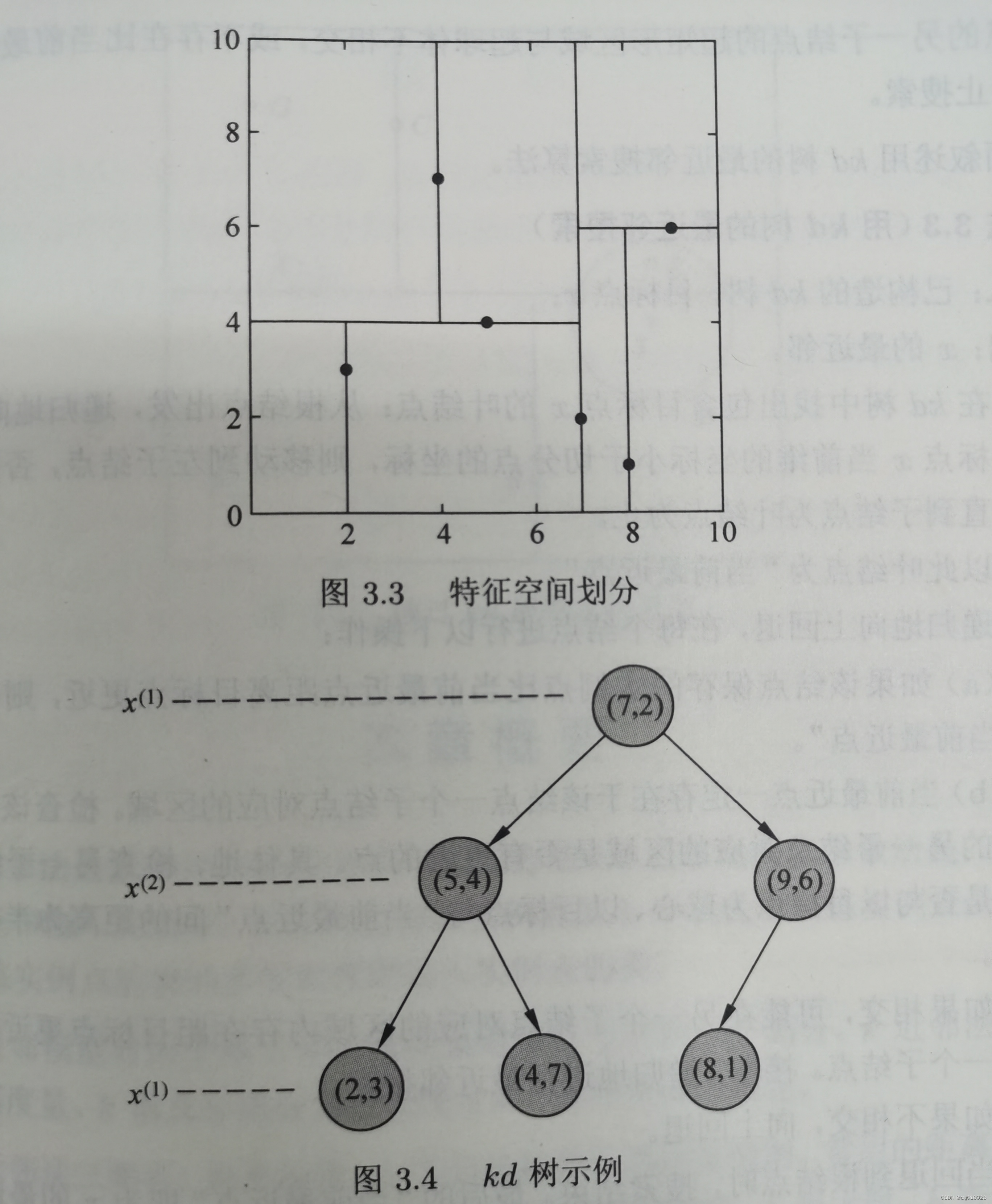
(一)构造kd树
- 定义
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构
kd树是二叉树,表示对k维空间的一个划分
kd树的每个结点对应于一个k维超矩形区域 - 构造方法
- 构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域
- 通过下面的递归方法,不断地对k维空间进行切分,生成子结点
- 递归方法如下:

- 算法

- 例题

(二)搜索kd树
- 算法

- 例题


四、书中关于k近邻法的参考文献

五、关于《统计学习方法》的作者

















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









