







3.1 基本形式

为啥叫做线性模型呢?因为这个很像是f(x)=ax+b的形式,在图形上看是一个直线,只是斜率和截距不一样而已。
3.2 线性回归
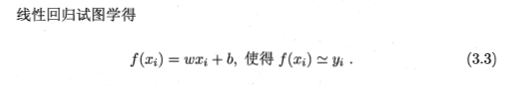
这个就有意思了,这里x是给的数值,f(x)是预测值,w,b是变量,那么变量的更新就是个大问题,其实神经网络在这里也是面临了这个问题,就是变量的更新。这里先是放置了一个w,b的更新的大致方向,就是使得预测和真实值接近嘛。然后化简一步利于后面的求导。基本的方法就是求导,然后更新参数。
在这里,我们是要找到 参数w,b的最优值,这样就需要一个衡量指标来说明w,b的寻找方向,如果没有方向随便找岂不是失去了意义。在这里就需要引入一个衡量的方法,在第二章里面讲过一种均方误差是回归任务中常用于性能度量,我们可以把寻找w。b的方向设置为使得均方误差最小。即:
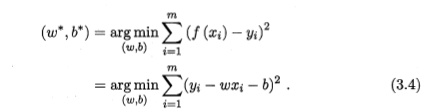
均方误差也被称为是欧氏距离,其实就是两点之间的距离。如果看成是平面两点,不就是横坐标差的平方和纵坐标差的平方嘛!
在寻找最优化的过程中,我们一直想找到一个方法,相信像我一样的高数学渣只有一个想法就是求导数为零的极值点。所以先求个导数:
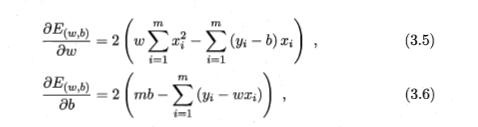
在这里,是把f(x)下yi-wx代入了,然后 刚才的最小二乘法的公司进行求导,然后令两个式子为零,然后可以化简出来w,b的最优解。

这里的输入如果样本有多个属性的时候,就被称为“多元线性回归”但是面临的计算就是矩阵计算,这个就是个问题了。

在这里,把wx+b的形式进行了转化,转换为了一个单纯的矩阵的运算,然后得到结果。
这里不得不说的是|AA^T| = |A| |A^T| = |A||A| = |A|^2 其实也是计算了一个欧氏距离,和上面的公式没矛盾,但是这里的w*实际上就是吧上面的w和b进行了拼合,这样的感觉就是好像更省事了,因为最后的一列元素恒为1,所以这里的b是b乘上系数1,并没有变化。这里换成矩阵,好像是符号更加花哨了,但是实际上还是原来的算式引入,延展的,并没有什么变化。
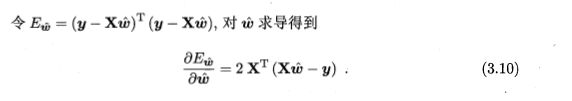
3.10就是对 3.9进行了一个线性变换得到的,然后解得:
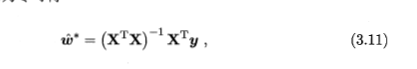
这样得到的回归模型是:
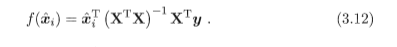
3.3 对数几率回归
当考虑到任务是二分类的问题的时候,常常会遇到的一个问题是预测出来的是个连续值,而我们要的是个离散值。
这个时候就用到了替代函数。
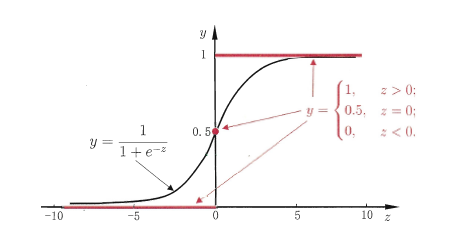
这个Sigmoid函数优点有:1,是个连续函数。2,能够快速的区分出来两个值。
此时的公式可以看为:
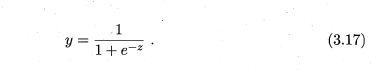
将我们的函数代入,可以得到:
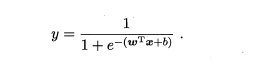
如果是对数据进行了ln变换,用来搞一个非线性映射的话那就是:
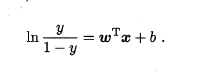
其实,在这里就是对公式左边取ln而已,不是两边同时取的,之前因为这个化简老半天,才发现是自己不仔细啊。
这里正好是对立事件y|1-y的概率之比,则公式又可以化简为:
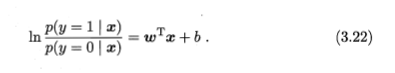
然后得到了下式:
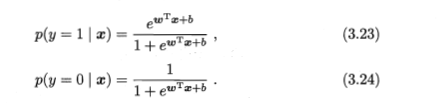
然后根据极大似然法对概率回归模型进行对数似然:
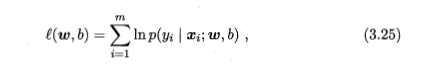
再将b合并进入参数矩阵。然后可以得到:
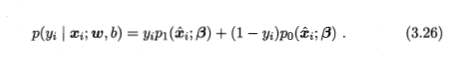
下面即将是一个大坑~~~:

嗯,这里貌似不好推导出来啊,然后无奈之下,上网找到了这个~:
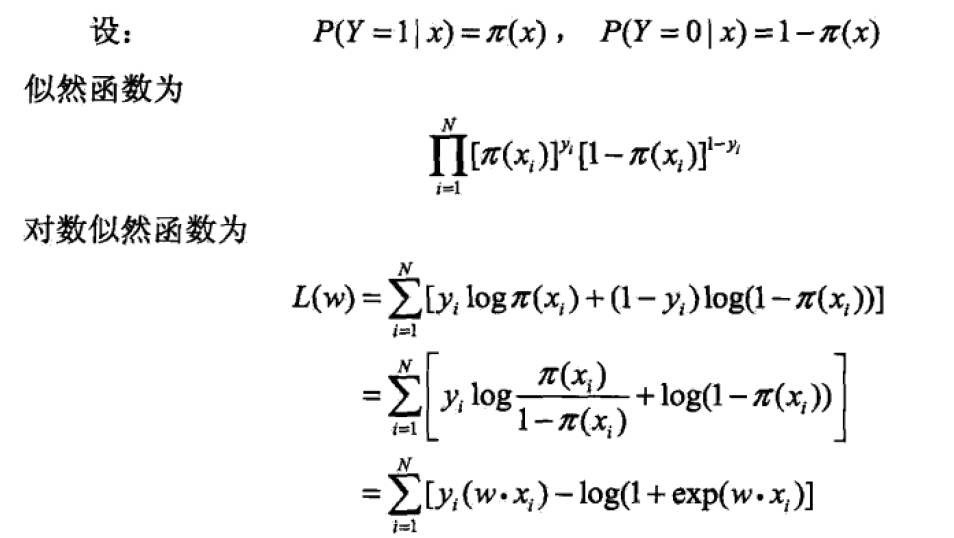
来源:http://www.cnblogs.com/zhusleep/p/5615874.html#3569825
迈过这个门槛就好多了
接下来无非就是迭代求导,更新嘛。






















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









