







1:对逻辑回归的介绍:逻辑回归假设数据服从贝努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,达到将数据二分类的目的。
2:逻辑回归的基本假设:
任何模型都有自己的假设,在这个假设下模型才是适用的。逻辑回归的第一个基本假设是假设数据服从贝努利分布。贝努利分布有一个简单的抛硬币的例子,正面的概率为p,负面的概率为1-p,在逻辑回归这个模型里面假设h0(x)为样本为正的概率,1-h0(x)为样本为负的概率,那么整个模型可以描述为:

3:逻辑回归的损失函数是它的极大似然函数:
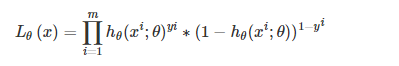
4:逻辑回归的求解方法:
由于极大似然函数无法直接求解,我们只能通过对该函数进行梯度下降不断逼近求最优解。而优化的方法主要有三种,随机梯度下降,批梯度下降,small batch梯度下降。那这三种梯度优化方式的优劣为:
批梯度下降:会获得全局最优解,缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且有很多的冗余计算,导致结果是当前数据量最大的时候,每个参数的更新都会很慢。
随机梯度下降是以高方差频繁更新,优点是使用sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加复杂。
小批量梯度下降结合sgd和batch gd的优点,每次更新的时候使用n个样本,减少参数更新的次数,可以达到更加稳定的收敛结果,一般在深度学习中我们采用这种方法。
其实除了以上常用的三种还有Adam和动量法等优化方法。
Adam:是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态的调整每个参数的学习率。Adam的优点主要在于经过偏置矫正后,每一次迭代学习率都有个确定的范围,是的参数更加平稳。
5:逻辑回归的目的:将数据进行二分类,提高准确率。
6:逻辑回归如何分类:
逻辑回归作为一个回归,如何应用到分类上去,y值确实是一个连续的变量。逻辑回归的做法是划定一个阈值,y值大于这个 阈值的是一类,y值小于阈值的是另一个类。阈值具体如何调整根据实际情况选择,一般会选择0.5作为阈值来划分。
7:逻辑回归的损失函数为什么使用极大似然函数作为损失函数?
损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对损失函数。将极大似然函数取对数以后等同于对数损失函数,在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的,至于原因















 1952
1952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









