







 本文总结了参加阿里天池大赛中的人工智能辅助糖尿病遗传风险预测项目,从数据初步分析到模型建立,探讨了特征处理、模型选择与优化,包括XGBoost、LightGBM及CatBoost的应用,强调了特征工程和数学理解的重要性。
本文总结了参加阿里天池大赛中的人工智能辅助糖尿病遗传风险预测项目,从数据初步分析到模型建立,探讨了特征处理、模型选择与优化,包括XGBoost、LightGBM及CatBoost的应用,强调了特征工程和数学理解的重要性。
题目以及数据介绍
Github 代码以及数据
Github
初始思想
1.从头开始,先看一下初始数据以及数据的简单分析吧
训练数据,最后一列是血糖:
A榜测试数据
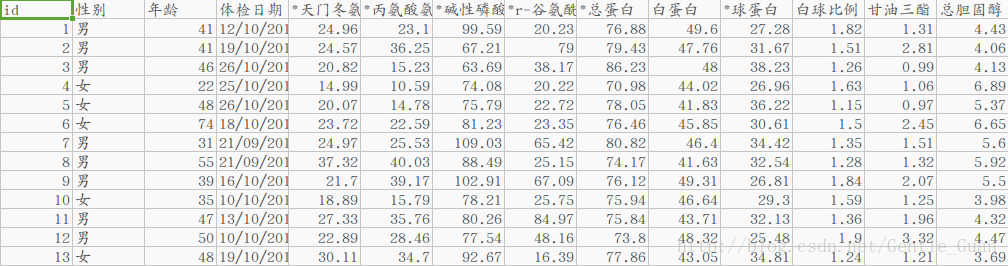
第九个特征与标签的关系分布
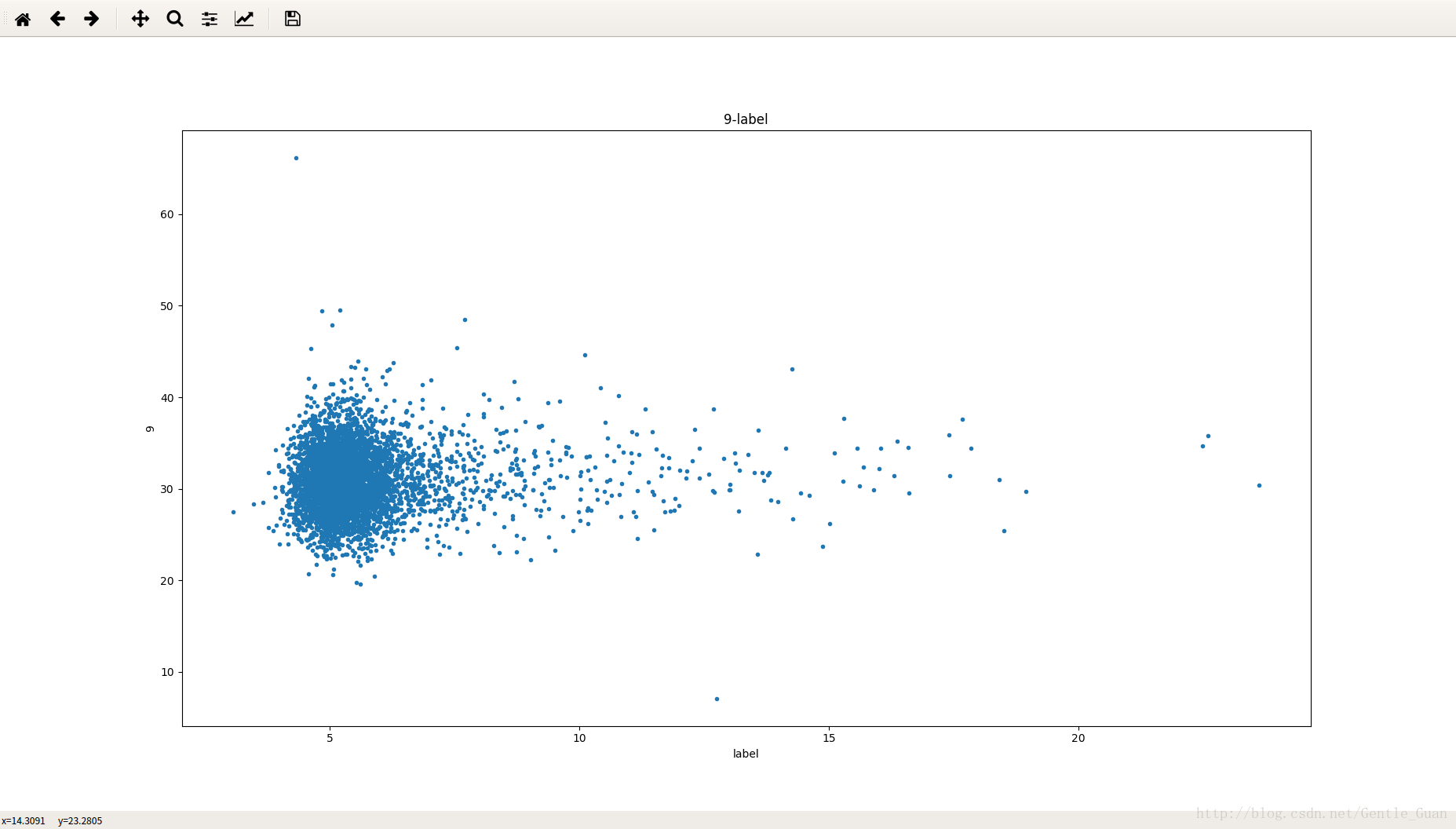
第三十八个
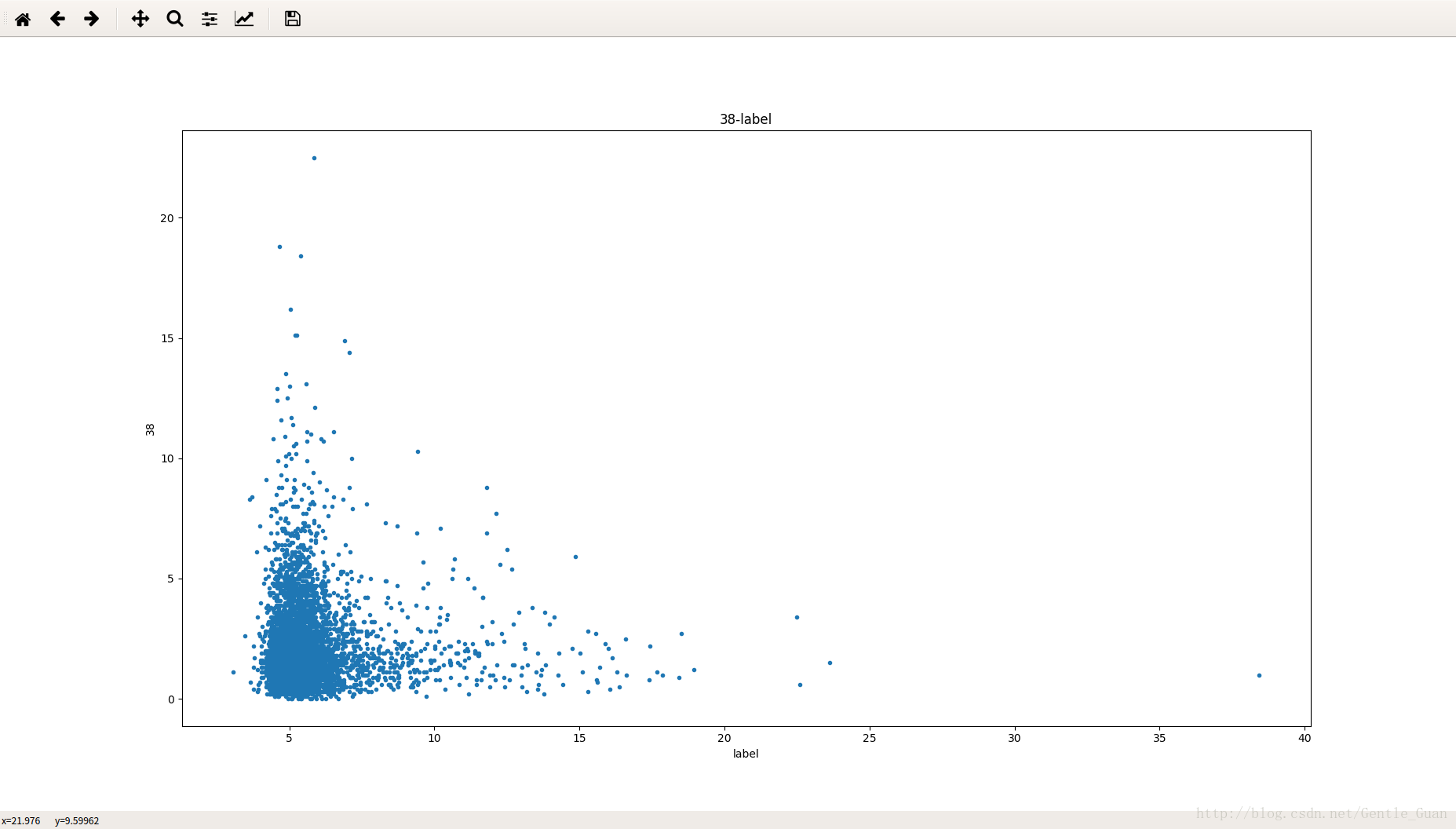
各个特征计数(有点糊)
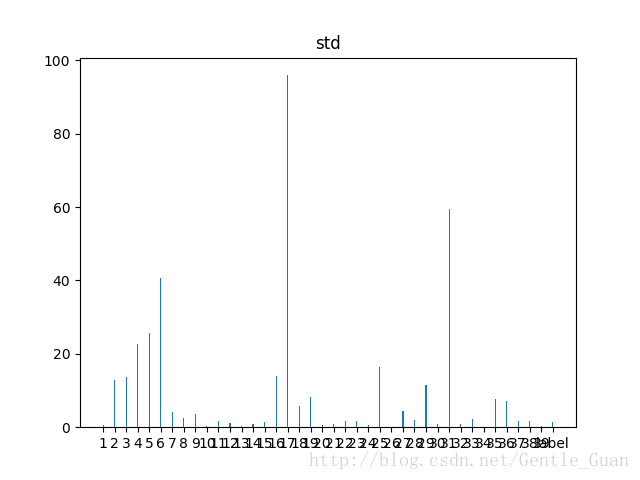
各个特征(标签)的标准差
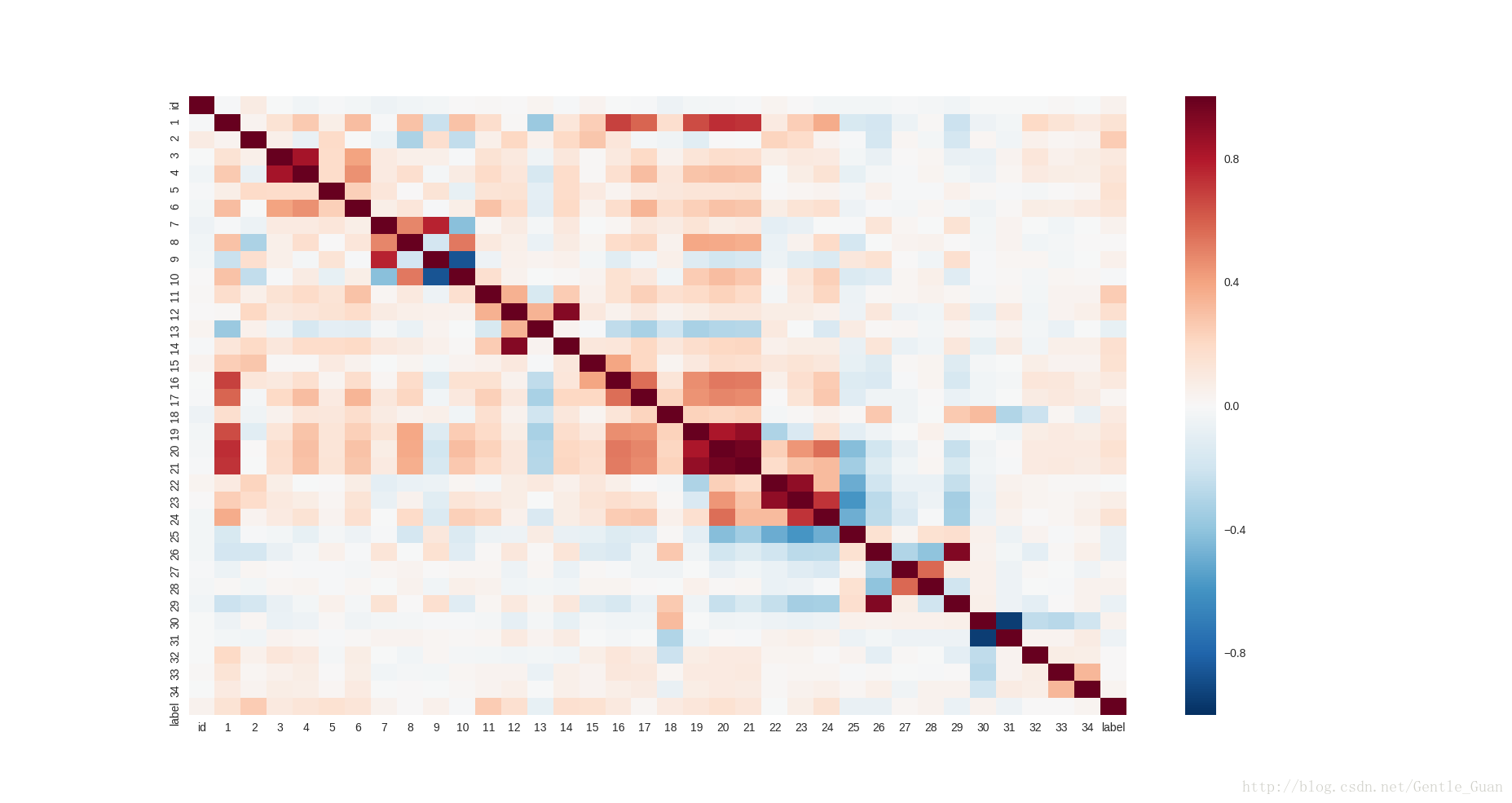
热力图(反应相关性)
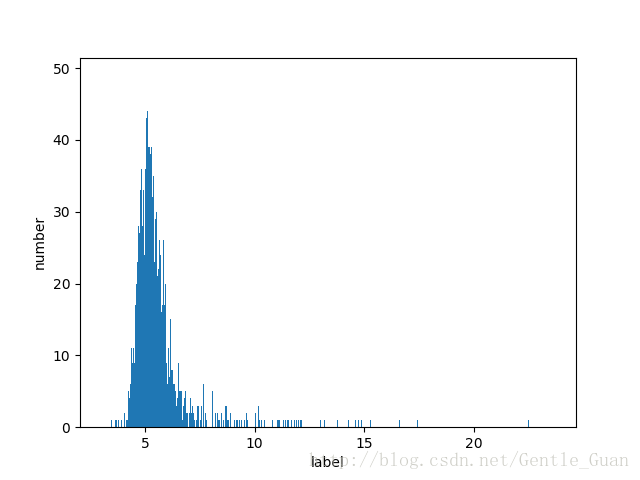
标签数量分布(简单取整)
2. 对以上数据分析一下:
1)特征的数据分布基本上是类似图中的分布规律(符合实际情况,说明该指标大部分人都正常)
2)个别特征的标准差比较大,说明有离群值,先baseline在进行离群值处理
3)个别特征缺失值比较多(尤其中间五个,缺失近乎75%,实际指标为乙肝五项),所以暂不使用
4)由于特征是医学指标,所以需要挖掘内在的医学上的关系
5)数据中时间以及id暂不使用,并且性别映射为数值: 男1女0
3. 根据上述分析进行简单模型跑出baseline,xgboost模型

# 得分score按照题目要求实现
# 利用xgboost的树模型以及泊松分布(label大致符合泊松分布)
# 误差rmse为均方根误差(均方误差开方)
# 参数如下,1000-50次迭代
para = {
'booster': 'gbtree',
'objective': 'count:poisson',
'eval_metric': 'rmse',
'eta': 0.3, # alpha
'silent': 1,
'max_depth': 3,
'subsample': 0.9, # 0.9样本选取率 防止过拟合
"miss": -999,
"lambda":1.5
}
结果:
本地cv-5折测试得分score<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









