






文章目录
绪论
今年读研了,学校要求参加研究生数学建模大赛,9.26就要开始了,but今天已经是9.15了,算是从今天开始入门吧。
感觉从0开始看理论已经来不及了,从之前参加研究生数学建模大赛的同学那里取取经,他建议直接从代码出发进行学习,不会的问chatgpt,然后多总结,从应用向理论进军。
那我选择的就是bilibili里面数学建模老哥的视频,然后搞清楚每一行代码,因为毕竟是工科,单纯的理论无法支撑自己的代码实践。
注:我采用这种方法的原因是因为我自己还是有较好的python基础,之前也用python开发过不少东西,所以对于语法什么的还算比较熟练,相信同样适用于对于任意一门编程语言熟悉的相似的同学,如果对于编程一点基础没有的同学,可能我的学习方法比较吃力了
代码初入门
下面是第一部分的代码,对于自己还是比较难理解里面的很多代码的。
鸢尾花分类代码入门
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.datasets import load_iris
iris_dataset = load_iris()
# 分离数据集
X = iris_dataset.data # 特征数据
Y = iris_dataset.target # 目标数据
validation_size = 0.2 # 验证集比例
seed = 7 # 随机数种子
# 将数据集分为训练集和验证级
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y, test_size=validation_size, random_state=seed)
# 算法
models = {}
# 第一个模型 逻辑回归模型
models['LR'] = LogisticRegression()
# 第二个模型 聚类模型(K临近分类器)
models['KNN'] = KNeighborsClassifier()
# 第三个模型 线性判别分析模型
models['LDA'] = LinearDiscriminantAnalysis()
# 第四个模型 决策树模型
models['CART'] = DecisionTreeClassifier()
# 第五个模型 支持向量机模型
models['SVM'] = SVC()
# 第六个模型 高斯朴素贝叶斯模型
models['NB'] = GaussianNB()
results = []
# 使用交叉验证对每个模型进行评估
for key in models:
# 十折检验
kflod = KFold(n_splits=10, random_state=seed, shuffle=True)
cv_results = cross_val_score(models[key], X_train, Y_train, cv=kflod, scoring="accuracy") # 计算模型性能
results.append(cv_results)
print('%s: %f (%f)' % (key, cv_results.mean(), cv_results.std()))
# 结果报告
svm = SVC() # 创建一个支持向量机模型
svm.fit(X=X_train, y=Y_train) # 在训练集上训练模型
predictions = svm.predict(X_validation) # 在验证集上进行预测
print(accuracy_score(Y_validation, predictions)) # 打印准确度
print(confusion_matrix(Y_validation, predictions)) # 打印混淆矩阵
print(classification_report(Y_validation, predictions)) # 打印分类报告
这部分代码有几个概念我需要进行深度理解
1、随机数种子
chatgpt:
随机数种子(Random Seed)是在生成随机数时用来初始化伪随机数生成器的起始值。伪随机数生成器是计算机程序中用来生成看似随机的数字序列的算法,它们实际上是基于确定性的数学计算,因此被称为伪随机数生成器。
随机数种子的作用如下:
-
可重复性:在相同的随机数种子下,伪随机数生成器将生成相同的随机数序列。这对于调试和复现实验结果非常重要。如果你需要确保你的随机实验或模型可以复现,就应该使用相同的随机数种子。
-
控制随机性:通过设置不同的随机数种子,你可以控制伪随机数生成器生成的随机数序列。这对于进行实验时研究不同随机性对结果的影响很有用。如果你想比较不同的随机种子下的模型性能,可以多次运行实验并选择最好的结果。
-
消除偏差:在某些情况下,伪随机数生成器可能受到初始条件的影响,导致生成的随机数序列有一定的偏差。通过设置随机数种子,你可以在一定程度上消除这种偏差。
在编程中,通常通过设置随机数种子的方式来控制伪随机数生成器的行为。例如,在Python的random模块中,可以使用random.seed(seed)来设置随机数种子,其中seed是一个整数值。
总之,随机数种子是在伪随机数生成器中起到初始值的作用,用来确保随机性的可控性和可重复性,特别在科学研究、数据分析和机器学习中是非常有用的。
晦涩难懂?用代码简单说明一下吧
当你设置随机数种子时,你可以确保在相同的种子下生成的随机数是相同的。
import random
# 不设置随机数种子,生成两个随机数
random_number1 = random.random()
random_number2 = random.random()
print("随机数1(没有种子):", random_number1)
print("随机数2(没有种子):", random_number2)
# 设置随机数种子为1,生成两个随机数
random.seed(1)
random_number3 = random.random()
random_number4 = random.random()
print("随机数3(种子为1):", random_number3)
print("随机数4(种子为1):", random_number4)
# 再次设置随机数种子为1,生成两个随机数,结果会与上面的相同
random.seed(1)
random_number5 = random.random()
random_number6 = random.random()
print("随机数5(种子为1,再次生成):", random_number5)
print("随机数6(种子为1,再次生成):", random_number6)
这段代码首先使用random.random()函数生成两个随机数,然后设置随机数种子为1,再次生成两个随机数。你会注意到,在设置了相同的种子后,生成的随机数是相同的。这就是随机数种子的作用,它确保了在相同种子下生成的随机数序列是可重复的。如果你更改种子,生成的随机数将不同。
总之,随机数种子允许你控制和复现伪随机数生成器的行为,这对于在机器学习、实验和模拟中需要可重复性的任务非常有用。
2、逻辑回归模型
逻辑回归模型:
逻辑回归是一种广泛用于分类问题的统计模型,它基于线性回归模型的概念,但经过了一些修改,以输出一个在0和1之间的概率值,用于描述样本属于某一类别的概率。
模型基本思想:
逻辑回归的基本思想是通过将线性函数的输出(称为“逻辑(logit)”)映射到0和1之间的概率来完成分类。这个映射通常是通过Sigmoid函数(也称为Logistic函数)来实现的。
σ
(
z
)
=
1
1
+
(
e
)
−
z
σ(z)=\frac{1}{1+(e )^{-z}}
σ(z)=1+(e)−z1
逻辑回归模型的表达式如下:
P
(
Y
=
1
∣
X
)
=
1
1
+
e
−
(
β
0
+
β
1
X
1
+
β
2
X
2
+
⋯
+
β
n
X
n
)
P(Y=1∣X)= \frac{1}{1+e^{-(\beta_{0} + \beta_{1}X_{1} + \beta_{2}X_{2} + \cdots + \beta_{n}X_{n})}}
P(Y=1∣X)=1+e−(β0+β1X1+β2X2+⋯+βnXn)1
其中, P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X)表示给定输入特征 X X X条件下,样本属于类别1的概率; X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn是输入特征; β 0 , β 1 , β 2 , … , β n \beta_0, \beta_1, \beta_2, \ldots, \beta_n β0,β1,β2,…,βn是模型参数,它们通过训练数据学习得到。
模型训练:
模型的训练过程通常使用最大似然估计(Maximum Likelihood Estimation,MLE)来估计模型参数。训练过程的目标是最大化观测数据的似然函数,从而找到最适合数据的模型参数。
预测:
一旦模型参数学习完成,就可以用于进行新样本的分类预测。通过计算 P ( Y = 1 ∣ X ) P(Y=1|X) P(Y=1∣X),如果概率大于0.5,通常将样本分为类别1;否则,分为类别0。
优点:
逻辑回归简单且易于实现。
对于二分类问题,输出结果有明确的概率解释。
在适当的正则化情况下,逻辑回归也可以用于处理高维数据。
缺点:
逻辑回归是线性模型,对于复杂的非线性关系建模能力有限。
对于多分类问题,需要通过一对多(One-vs-Rest)或Softmax回归进行扩展。
逻辑回归是许多机器学习问题的基础,尤其是在分类问题中。虽然它是一个简单的模型,但在许多实际应用中表现良好。
代码助理解
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 载入Iris数据集
iris_dataset = load_iris()
# 分离数据集
X = iris_dataset.data
Y = iris_dataset.target
# 将数据集分为训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, Y_train)
# 进行预测
predictions = model.predict(X_test)
# 计算准确度
accuracy = accuracy_score(Y_test, predictions)
# 打印准确度
print("准确度:", accuracy)
3、聚类模型(K临近分类器)
当谈到K近邻分类器(K-Nearest Neighbors,KNN)模型时,我们通常指的是一种基于实例的监督学习算法,主要用于分类任务,尽管它也可以用于回归问题。KNN模型的核心思想是基于数据点的相似性来进行分类或预测。
下面是关于KNN模型的详细解释:
①KNN的数学公式:
KNN的核心思想是通过计算数据点之间的距离来确定最近邻居,然后基于这些最近邻居的类别来进行分类。以下是KNN的数学公式:
距离度量:通常使用欧氏距离(Euclidean Distance)来衡量两个数据点之间的距离。对于两个数据点 X X X和 Y Y Y,它们之间的欧氏距离可以表示为:
距离 ( X , Y ) = ∑ i = 1 n ( X i − Y i ) 2 距离(X,Y)=\sqrt{ \sum_{i=1}^{n}(X{_i} −Y{_i})^2} 距离(X,Y)=i=1∑n(Xi−Yi)2
其中, X i X_i Xi和 Y i Y_i Yi是数据点 X X X和 Y Y Y的特征值, n n n是特征的数量。
K近邻的选择:对于要进行分类的新数据点 X X X,KNN算法会计算它与训练数据集中每个数据点的距离,并选择距离最近的K个数据点作为最近邻居。
分类决策:一旦找到最近的K个邻居,KNN将统计这些邻居中各个类别的出现频率。新数据点 X X X将分配到具有最多邻居的类别作为最终分类结果。
②KNN的基本思想:
KNN的核心思想可以总结为以下几个步骤:
选择一个合适的距离度量方法:通常使用欧氏距离、曼哈顿距离或其他距离度量方法来衡量数据点之间的相似性。
选择一个合适的K值:K值表示在进行分类或预测时要考虑的最近邻居的数量。K值的选择会影响模型的性能。
对于要进行分类或预测的新数据点:
计算它与训练数据集中每个数据点之间的距离。
选择距离最近的K个训练数据点。
统计这K个数据点所属的类别或计算它们的平均值(对于回归问题)。
将新数据点分配到具有最多邻居的类别(对于分类问题)或使用平均值作为预测结果(对于回归问题)。
因此K近邻分类器(KNN)的两个重要方面是K值和距离度量方式:
- K值(Neighbors数):KNN算法中的K表示要考虑的最近邻居的数量。选择适当的K值非常重要,因为它会影响模型的性能。较小的K值可能会导致模型对噪声敏感,而较大的K值可能会导致模型过于平滑。通常,可以通过交叉验证或其他模型选择技术来确定最佳的K值。
- 距离度量方式:KNN算法使用距离度量方法来衡量数据点之间的相似性。常用的距离度量包括欧氏距离(Euclidean Distance)和曼哈顿距离(Manhattan Distance),但也可以使用其他度量方法,具体取决于问题的性质和数据的特点。选择合适的距离度量方式对于KNN模型的性能至关重要。
除了K值和距离度量方式,KNN还涉及到如何处理平票问题(当多个类别的邻居数相等时),以及如何处理特征的权重等问题。这些因素可以根据具体的应用情况进行调整和优化。
总之,KNN模型的关键是选择适当的K值和距离度量方式,以便正确分类或回归新数据点。这两个因素对于模型的性能和行为至关重要。
③KNN的超参数K:
K值是KNN模型的一个关键超参数,它决定了模型考虑多少个最近邻居。选择合适的K值通常需要进行交叉验证或其他模型选择技巧,因为不同的K值会导致不同的模型性能。较小的K值可能会导致模型对噪声敏感,而较大的K值可能会导致模型过于平滑。
④KNN的特点:
- KNN是一种懒惰学习(Lazy Learning)算法,它没有显式的训练过程,而是在预测时进行实时计算。
- KNN适用于各种类型的数据,包括数值和分类数据。
- 它是一种非参数算法,因为它不对数据的分布进行假设。
- KNN的主要优点之一是它的直观性和简单性。
⑤KNN的应用:
KNN常用于模式识别、图像处理、推荐系统、异常检测等领域,尤其在小数据集或者没有明显分布特征的情况下表现良好。它也可用于多分类问题和回归问题。
⑥如何确定K值和距离度量
-
选择K值:要选择最佳的K值,通常可以尝试不同的K值并使用交叉验证来评估每个K值的性能。例如,可以尝试一系列的K值(如1到20),并对每个K值进行交叉验证,选择具有最佳性能的K值。
-
选择距离度量方式:选择距离度量方式通常取决于数据的特点。欧氏距离是一种常用的度量方式,适用于连续特征。曼哈顿距离适用于具有明显分段结构的数据。对于高维数据,可以考虑使用其他距离度量方式,如余弦相似度等。选择距离度量方式时,建议根据数据的分布和特征进行实验。
⑦注意事项:
- KNN的性能高度依赖于数据的特征和距离度量方法,因此在使用前需要对数据进行适当的预处理和特征工程。
- KNN对于高维数据集可能不太适用,因为高维空间中的距离计算变得更加困难。
- 对于大型数据集,KNN的计算成本可能较高,因此可以考虑使用近似算法或数据降维来减少计算复杂性。
总之,K近邻分类器是一种简单而直观的分类算法,它基于数据点的相似性来进行分类或回归。了解K值的选择和距离度量方法对于成功应用KNN模型非常重要。
⑧代码助理解
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 载入Iris数据集
iris_dataset = load_iris()
# 分离数据集
X = iris_dataset.data
Y = iris_dataset.target
# 将数据集分为训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
# 定义一系列的K值
k_values = [1, 3, 5, 7, 9]
# 定义一系列的距离度量方式
# euclidean即默认距离度量方式是欧氏距离
distance_metrics = ['euclidean', 'manhattan', 'chebyshev']
# 遍历不同的K值和距离度量方式
for k in k_values:
for metric in distance_metrics:
# 创建KNN分类器模型
knn_model = KNeighborsClassifier(n_neighbors=k, metric=metric)
# 训练模型
knn_model.fit(X_train, Y_train)
# 进行预测
predictions = knn_model.predict(X_test)
# 计算准确度
accuracy = accuracy_score(Y_test, predictions)
# 打印结果
print(f'K={k}, 距离度量方式={metric}, 准确度={accuracy}')
几种距离度量方式
上面讲到的
- 欧式距离
距离
(
X
,
Y
)
=
∑
i
=
1
n
(
X
i
−
Y
i
)
2
距离(X,Y)=\sqrt{ \sum_{i=1}^{n}(X{_i} −Y{_i})^2}
距离(X,Y)=i=1∑n(Xi−Yi)2
2. 曼哈顿距离(Manhattan Distance)
距离
(
X
,
Y
)
=
∑
i
=
1
n
∣
X
i
−
Y
i
∣
距离(X,Y)={ \sum_{i=1}^{n}\left| X{_i} −Y{_i} \right|}
距离(X,Y)=i=1∑n∣Xi−Yi∣
3. 切比雪夫距离(Chebyshev Distance)
距离
(
X
,
Y
)
=
max
i
∣
X
i
−
Y
i
∣
距离(X,Y)={ \max_{i}\left| X{_i} −Y{_i} \right|}
距离(X,Y)=imax∣Xi−Yi∣
4. 闵可夫斯基距离(Minkowski Distance)
距离
(
X
,
Y
)
=
(
∑
i
=
1
n
∣
X
i
−
Y
i
∣
p
)
1
p
距离(X,Y)={ (\sum_{i=1}^{n}\left| X{_i} −Y{_i} \right|^p}) ^ {\frac{1}{p} }
距离(X,Y)=(i=1∑n∣Xi−Yi∣p)p1
5. 余弦相似度(Cosine Similarity)
余弦相似度用于衡量两个数据点之间的夹角余弦值,通常用于文本数据或高维数据。其公式如下:
距离
(
X
,
Y
)
=
X
⋅
Y
∣
∣
X
∣
∣
⋅
∣
∣
Y
∣
∣
距离(X,Y)=\frac{X\cdot Y}{\left||X \right||\cdot \left|| Y \right||}
距离(X,Y)=∣∣X∣∣⋅∣∣Y∣∣X⋅Y
其中,
X
X
X和
Y
Y
Y是数据点的特征向量,
⋅
\cdot
⋅表示向量的点积,
∣
X
∣
|X|
∣X∣和
∣
Y
∣
|Y|
∣Y∣表示向量的模(范数)。
4、线性判别分析模型
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的监督学习算法,主要用于解决分类问题。LDA的目标是通过线性投影将数据从高维空间映射到低维空间,同时最大化不同类别之间的距离,以实现有效的分类。
- 什么是高维空间映射到低维空间
在机器学习中,通常情况下,我们处理的数据具有多个特征(也就是维度),每个特征可以看作是空间中的一个坐标轴。这使得我们的数据存在于高维空间中,每个数据点都可以表示为高维空间中的一个点,其坐标由各个特征的值组成。
例如,考虑一个包含三个特征的数据集,每个数据点可以表示为一个三维空间中的点,如下所示:
数据点1: (x1, y1, z1)
数据点2: (x2, y2, z2)
数据点3: (x3, y3, z3)
在高维空间中,数据点之间的距离可能会变得非常复杂,难以可视化和理解。而且,高维空间中的数据可能存在冗余信息,不利于分类任务。
LDA的一个主要目标是将这个高维空间中的数据点映射到一个低维空间中,使得在低维空间中能够更好地区分不同类别的数据点。这个低维空间通常具有比原始高维空间低得多的维度,例如,将数据映射到一维或二维空间。
映射的目的是找到一个合适的投影方向,通过将数据点投影到这个方向上,能够最大程度地区分不同类别的数据点,同时使得同一类别的数据点尽量靠近。这个投影方向即为LDA中的“判别方向”。
举例来说,假设我们的数据包含两个类别的点,用红色和蓝色表示,它们在高维空间中可能重叠在一起,很难分类。但通过LDA的映射,我们可以将它们映射到一维空间上,如下所示:
映射后的数据点:
红色点: *
蓝色点: +
一维空间:
* +
在一维空间中,不同类别的数据点更容易区分。这使得分类任务更加简单和有效。
简单来说,也就是删除某一个维度或者说是删除某一个特征值来实现降维。
LDA的一种主要应用就是通过删除维度(特征值)来进行降维。在LDA中,我们寻找一个投影方向,将数据点映射到一维或更低维度的空间,从而实现降维的目标。
具体来说,LDA选择一个最佳的投影方向,使得在这个方向上不同类别的数据点之间的距离(类间距离)最大,同时同一类别内的数据点之间的距离(类内距离)最小。通过选择合适的投影方向,LDA可以实现在低维空间中更好地区分不同类别的数据点。
这种降维的过程通常会减少数据的特征数,即删除一些特征值,以便在降维后的空间中表示数据。这有助于减少数据的复杂性、降低计算成本,并提高分类的效率。
总之,LDA的降维过程通常包括删除特征值,但是删除的特征值是经过优化选择的,以保留对分类任务最有用的信息。这使得数据在更低维度上更容易分类,同时保留了关键信息。如果需要,LDA还可以将数据映射到更高维度的空间,以便更好地区分不同类别的数据点。
- LDA的关键概念
-
类别:在LDA中,我们处理的数据通常包含多个类别。每个类别都包含一组数据点,我们的目标是将这些数据点正确地分类到它们所属的类别中。
-
投影:LDA通过将高维数据点投影到一条直线或多条直线上来实现数据的降维。这些直线称为"判别方向"或"投影方向"。将数据投影到这些方向上后,我们可以更容易地进行分类。
-
最大化类间距离:LDA的主要目标之一是最大化不同类别之间的距离。这意味着投影后,不同类别的数据点应尽可能分散,使得它们在低维空间中更容易区分。
-
最小化类内距离:同时,LDA也尽量减小同一类别内数据点之间的距离,以确保同一类别的数据点在投影后尽量靠近,以降低同一类别内的变异性。
-
判别准则:LDA使用一个判别准则来确定最佳的投影方向。这个准则通常涉及到类别之间的协方差矩阵和类别内的协方差矩阵。
- LDA的数学公式和步骤
-
计算每个类别的均值向量:
对于每个类别,计算该类别内所有数据点的特征均值,得到一个均值向量。假设有C个类别,那么将得到C个均值向量。
m c = 1 N c ∑ i = 1 N c x i \boldsymbol{m}_c = \frac{1}{N_c}\sum_{i=1}^{Nc}{x_i} mc=Nc1i=1∑Ncxi
其中, m c \boldsymbol{m}_c mc是第c个类别的均值向量, N c N_c Nc是第c个类别的数据点数量, x i \boldsymbol{x}_i xi是第c个类别的第i个数据点。 -
计算类内散布矩阵(Within-Class Scatter Matrix):
类内散布矩阵度量了每个类别内数据点的变异性,可以用以下公式计算:
S W = ∑ c = 1 C ∑ i = 1 N c ( x i − m c ) ( x i − m c ) T S_W = \sum_{c=1}^{C}\sum_{i=1}^{N_c}(x_i-m_c)(x_i-m_c)^T SW=c=1∑Ci=1∑Nc(xi−mc)(xi−mc)T
其中, S W S_W SW是类内散布矩阵, C C C是类别的数量, N c N_c Nc是第c个类别的数据点数量, m c \boldsymbol{m}_c mc是第c个类别的均值向量, x i \boldsymbol{x}_i xi是第c个类别的第i个数据点。 -
计算类间散布矩阵(Between-Class Scatter Matrix):
类间散布矩阵度量了不同类别之间数据点的差异性,可以用以下公式计算:
S B = ∑ c = 1 C N c ( m c − m ) ( m c − m ) T S_B = \sum_{c=1}^{C}N_c(m_c-m)(m_c-m)^T SB=c=1∑CNc(mc−m)(mc−m)T
其中, S B S_B SB是类间散布矩阵, C C C是类别的数量, N c N_c Nc是第c个类别的数据点数量, m c \boldsymbol{m}_c mc是第c个类别的均值向量, m \boldsymbol{m} m是所有类别的数据点均值向量。 -
计算广义特征值问题(Generalized Eigenvalue Problem):
LDA的关键步骤是解决广义特征值问题,其中需要计算类内散布矩阵 S W S_W SW和类间散布矩阵 S B S_B SB的特征向量和特征值。这些特征向量对应于LDA的判别方向。 -
选择投影方向:
选择特征值最大的k个特征向量,其中k是降维后的维度(通常小于原始特征的数量)。这些特征向量构成了LDA的判别方向,也称为线性判别函数。 -
数据投影:
将原始数据点投影到选定的判别方向上,从而得到降维后的数据。 -
分类:
在降维后的数据上应用分类算法,通常是使用线性判别函数来进行分类。
- 注意点
类内散布矩阵(Within-Class Scatter Matrix)是在线性判别分析(LDA)模型的训练过程中用于计算特征变换矩阵的一部分,它主要用于最大化不同类别之间的距离,从而更好地实现分类任务。在使用训练好的LDA模型对新数据进行降维或分类时,通常不需要显式地使用类内散布矩阵。
类内散布矩阵的计算是为了确定最佳的投影方向,以便在投影后不同类别之间的距离最大化,而同一类别内的数据点之间的距离最小化。一旦LDA模型训练完成,得到了特征变换矩阵,你可以将新的数据点投影到这个低维空间上,然后进行分类或其他任务,而无需再次计算类内散布矩阵。
所以,你在使用LDA模型时通常不需要直接处理类内散布矩阵,而是使用已经训练好的模型进行预测和分类。类内散布矩阵的计算是在模型训练过程中完成的,为了最优化特征变换矩阵而进行的一步。
- 代码助理解
在这个示例中,我们将使用scikit-learn库,并考虑以下三种常用的降维方法:
主成分分析(Principal Component Analysis,PCA)
线性判别分析(Linear Discriminant Analysis,LDA)
t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.ensemble import RandomForestClassifier
# 载入Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 标准化数据
scaler = StandardScaler()
X_std = scaler.fit_transform(X)
# 创建降维模型列表,包括PCA、t-SNE和LDA
models = []
models.append(('PCA', PCA(n_components=2)))
models.append(('t-SNE', TSNE(n_components=2, perplexity=30)))
models.append(('LDA', LDA(n_components=2))) # 添加LDA模型
# 评估每个模型的性能
results = []
names = []
for name, model in models:
try:
if name == 'LDA':
X_reduced = model.fit_transform(X_std, y) # 传递目标变量 y
else:
X_reduced = model.fit_transform(X_std)
cv_results = cross_val_score(RandomForestClassifier(), X_reduced, y, cv=5, scoring='accuracy')
results.append(cv_results)
names.append(name)
print(f'{name}: 平均准确率 {cv_results.mean():.4f}, 标准差 {cv_results.std():.4f}')
except Exception as e:
print(f'{name} 出现错误: {str(e)}')
# 绘制性能比较图
plt.boxplot(results, labels=names)
plt.title('降维方法性能比较')
plt.show()
在上面的代码中,绘制的性能比较图中,横坐标代表不同的降维方法(例如,‘PCA’、‘t-SNE’、‘LDA’),而纵坐标代表每个降维方法的性能评估指标,这里使用的是随机森林分类器的准确率(Accuracy)。
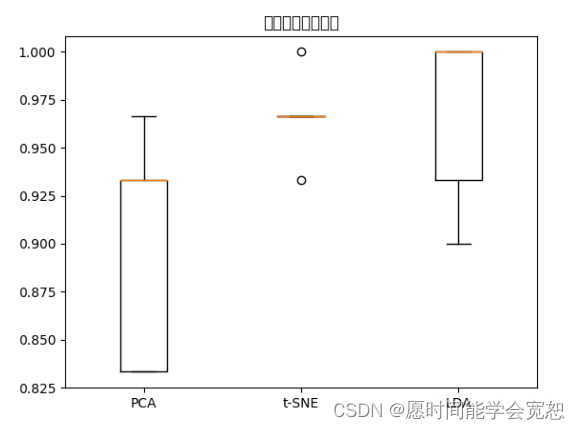
箱型图具体学习内容
每个箱形图(box plot)表示对应降维方法的性能评估结果,箱形图的属性如下:
箱子的底部和顶部分别表示第25和第75百分位数,也就是数据的中间50%范围。
箱子内的横线表示中位数(第50百分位数)。
箱子上下的“须”(whiskers)表示数据的范围,排除了异常值。
箱子上方的小点可能是异常值。
通过观察箱形图,你可以比较不同降维方法在准确率方面的性能表现,并识别是否存在异常值
5、决策树模型
决策树是一种基于树状结构的监督学习模型,用于解决分类和回归问题。在决策树中,每个内部节点代表一个特征属性的测试,每个分支表示测试的结果,而每个叶节点代表一个类别标签或一个数值。
- 构建方式
-
树的开始:通常,整个数据集被视为树的根节点。
-
选择最佳特征分割:在每个内部节点,算法选择一个特征属性,以最好地分割数据。分割的目标是尽可能纯净地划分数据,使得同一子集内的样本属于同一类别或具有相似的数值。
-
递归分割:在选择了特征属性后,将数据分割为多个子集,并对每个子集递归应用相同的过程,直到达到停止条件。停止条件可以是树达到了最大深度、子集的样本数量小于某个阈值,或者子集的样本属于同一类别。
-
生成叶节点:一旦停止条件满足,节点将被标记为叶节点,并分配一个类别标签(对于分类问题)或一个数值(对于回归问题)。
-
递归返回:递归地将这个过程应用于树的每个子节点,直到整棵树构建完成。
- 优势
-
易于理解和解释:决策树模型生成的规则非常直观,容易可视化和解释。你可以轻松理解每个节点的分割条件以及最终的决策。
-
可处理混合类型特征:决策树能够处理连续型特征和分类型特征,并且不需要特征归一化或标准化。
-
鲁棒性:对于缺失值和异常值有一定的鲁棒性。
-
适用于大规模数据:决策树的训练和预测速度相对较快,适用于大规模数据。
- 缺点
-
容易过拟合:决策树容易过于复杂,导致过拟合。可以通过剪枝等技术来缓解这个问题。
-
不稳定性:数据的小变化可能导致树结构的巨大变化,这使得决策树在一些情况下不稳定。
-
基于单一属性的分割:决策树每次只能根据一个属性来分割数据,这可能会忽略了属性之间的相关性。
- 应用方式
决策树广泛用于分类和回归任务,包括医学诊断、金融风险评估、客户分析、自然语言处理等领域。
在使用决策树模型时,你可以调整一些参数,如树的深度、分割标准(如信息增益、基尼不纯度等)来优化模型的性能。同时,决策树还可以通过集成学习方法(如随机森林)来提高性能和稳定性。
- 代码助理解
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
# 载入Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集为训练集和验证集
X_train, X_validation, y_train, y_validation = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器模型
decision_tree = DecisionTreeClassifier()
# 训练模型
decision_tree.fit(X_train, y_train)
# 在验证集上进行预测
y_pred = decision_tree.predict(X_validation)
# 评估模型性能
accuracy = accuracy_score(y_validation, y_pred)
confusion = confusion_matrix(y_validation, y_pred)
report = classification_report(y_validation, y_pred)
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", confusion)
print("Classification Report:\n", report)
# 绘制决策树
plt.figure(figsize=(12, 6))
plot_tree(decision_tree, filled=True, feature_names=iris.feature_names)
plt.show()
- 决策树讲解
当绘制决策树的图像时,每个节点和箭头都包含了一些重要信息,以下是关于决策树图像的解释:
-
根节点 (Root Node): 图的最顶部节点表示整个数据集,并包含最初的样本数。它是决策树的起始点。
-
内部节点 (Internal Nodes): 决策树中的每个内部节点表示一个特征属性的测试。例如,在示例中的内部节点可以是 “petal length (cm) <= 2.45”。每个内部节点将数据集分成两个或更多子集,根据特征测试的结果来决定进入左子节点或右子节点。
-
叶节点 (Leaf Nodes): 叶节点是决策树的末端节点,它们代表最终的类别或回归值。例如,在示例中,叶节点可以是 “setosa”,“versicolor” 或 “virginica” 中的一个。当样本到达叶节点时,它们被分类为该叶节点所代表的类别。
-
箭头 (Arrows): 每个箭头表示数据流的方向,从父节点指向一个子节点。箭头上的标签表示了样本在特征上的测试结果,例如 “True” 或 “False”。
-
样本数量 (Samples): 每个节点下面的数字表示在该节点中的样本数量。这是用于计算节点纯度的一个重要指标。
-
Gini 不纯度 (Gini Impurity): 决策树的目标是在每个节点上减少数据的不纯度。Gini不纯度是一种衡量不纯度的指标,它越低表示节点中的样本越纯净。通常,节点上的Gini不纯度越低,就越有可能成为一个叶节点。
-
类别分布 (Class Distribution): 叶节点下面的类别分布表示在该叶节点中每个类别的样本数量。例如,在示例中,如果一个叶节点表示 “setosa”,那么它下面的类别分布可能是 “setosa: 10”,表示有10个 “setosa” 类别的样本。
-
样本分布(value)表示每个叶节点中的样本分布,具体来说,它显示了在叶节点中每个类别的样本数量
value = [50, 0, 0]表示在该叶节点中,有50个样本属于类别1(或者某个具体的类别,例如 “setosa”),而其他类别的样本数量为0。这个信息告诉我们,当数据流经这个叶节点时,它们将被分类为类别1(或者 “setosa”),因为它具有最多的样本。
value = [0, 10, 5]表示在该叶节点中,有10个样本属于类别2,5个样本属于类别3,而类别1的样本数量为0。这个信息告诉我们,当数据流经这个叶节点时,它们将被分类为类别2或类别3,具体取决于进入这个节点的样本。
综合来看,决策树图像以一种树状结构清晰地展示了如何根据一系列特征属性对样本进行分类或回归。它从根节点开始,通过一系列特征测试,最终将样本分配到叶节点,每个叶节点代表一个类别或数值。决策树的目标是构建一个具有高纯度的树,以便在每个叶节点上具有相对纯净的样本分布。这使得决策树成为一个直观且易于理解的分类和回归模型
6、支持向量机模型
支持向量机模型是一种强大的监督学习算法,用于分类和回归任务。它的目标是找到一个最佳的决策边界(或称为超平面),以将不同类别的数据分隔开来。SVM的主要思想是找到离决策边界最近的一些数据点,这些点被称为支持向量,它们决定了决策边界的位置。
- 概念
-
超平面(Hyperplane):在二维空间中,超平面是一条直线,而在更高维度的空间中,它是一个超平面或者一个超平面的线性组合。SVM的目标是找到一个超平面,使得两个不同类别的样本点尽可能远离这个超平面,从而实现分类。
w ⋅ x − b = 0 w⋅x−b=0 w⋅x−b=0其中, w \mathbf{w} w 是法向量(向量), x \mathbf{x} x 是数据点在特征空间中的表示, b b b 是偏置。 -
支持向量(Support Vectors):支持向量是离超平面最近的样本点,它们是决策边界的关键组成部分。这些样本点对于确定决策边界的位置非常重要。
-
间隔(Margin):SVM追求最大化两个不同类别的样本点与决策边界之间的距离,这个距离称为间隔。间隔越大,模型对噪声的容忍性越好。
间隔 = ∥ w ∥ 2 间隔= \frac{∥w∥}{2} 间隔=2∥w∥其中, ∣ w ∣ |\mathbf{w}| ∣w∣ 是法向量 w \mathbf{w} w 的范数。 -
核函数(Kernel Function):SVM可以使用核函数将数据映射到更高维度的空间中,从而在原始空间中线性不可分的问题变得线性可分。常用的核函数包括线性核、多项式核和高斯核等。
-
正则化参数(Regularization Parameter):SVM有一个正则化参数C,用于平衡间隔的最大化和错误分类的最小化。较小的C值会产生更大的间隔但可能容忍一些错误分类,而较大的C值会减小间隔但更严格地惩罚错误分类。
-
多类别分类(Multiclass Classification):SVM通常是一个二分类算法,但可以通过一对多(One-vs-Rest)或一对一(One-vs-One)策略扩展到多类别分类问题。
- 代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
# 载入Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集为训练集和验证集
X_train, X_validation, y_train, y_validation = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建支持向量机(SVM)分类器模型
svm_classifier = SVC()
# 训练模型
svm_classifier.fit(X_train, y_train)
# 在验证集上进行预测
y_pred = svm_classifier.predict(X_validation)
# 评估模型性能
accuracy = accuracy_score(y_validation, y_pred)
confusion = confusion_matrix(y_validation, y_pred)
report = classification_report(y_validation, y_pred)
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", confusion)
print("Classification Report:\n", report)
# 计算学习曲线
train_sizes, train_scores, test_scores = learning_curve(svm_classifier, X_train, y_train, cv=5)
# 计算平均训练和测试得分
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
# 绘制学习曲线
plt.figure(figsize=(10, 6))
plt.title("Learning Curve")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.grid()
# 用于绘制训练得分(模型在训练集上的性能)随着训练样本数量的变化而变化的曲线。在图中,每个点代表一个训练集大小,o- 用于指定绘制的图形样式,label 用于图例中的标签。
plt.plot(train_sizes, train_scores_mean, 'o-', label="Training score")
# 用于绘制交叉验证得分(模型在验证集上的性能)随着训练样本数量的变化而变化的曲线。同样,每个点代表一个训练集大小,o- 用于指定绘制的图形样式,label 用于图例中的标签。
plt.plot(train_sizes, test_scores_mean, 'o-', label="Cross-validation score")
plt.legend(loc="best")
plt.show()
- 绘制边界
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.svm import SVC
# 载入Iris数据集
iris = load_iris()
X = iris.data[:, :2] # 仅选择前两个特征以便可视化
y = iris.target
# 创建SVM模型
svm_classifier = SVC(kernel='linear', C=1)
svm_classifier.fit(X, y)
# 绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
Z = svm_classifier.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('SVM Decision Boundary')
plt.show()
7、高斯朴素贝叶斯模型
一种基于贝叶斯定理的分类算法,它的核心思想是使用已知数据的统计信息来预测未知数据的分类。它被称为“朴素”是因为它假设特征之间相互独立,这在现实世界中并不总是成立,但这一假设简化了计算并使算法高效。
- 例子说明
下面我们将通过一个简单的例子来解释朴素贝叶斯的原理。
假设我们有一个垃圾邮件分类的任务。我们需要判断一封电子邮件是垃圾邮件还是非垃圾邮件。我们有一些已知的垃圾邮件和非垃圾邮件,每封邮件都有一些特征,例如词汇,邮件中出现的单词。
首先,让我们定义一些术语:
S
S
S:邮件是垃圾邮件的事件。
H
H
H:邮件是非垃圾邮件的事件。
D
D
D:邮件的特征数据,即包含了邮件中每个单词的信息。
我们的目标是计算在给定特征数据
D
D
D 的情况下,邮件属于事件
S
S
S(垃圾邮件)的概率
P
(
S
∣
D
)
P(S|D)
P(S∣D) 和邮件属于事件
H
H
H(非垃圾邮件)的概率
P
(
H
∣
D
)
P(H|D)
P(H∣D)。然后,我们将选择概率较大的那个事件作为分类结果。
朴素贝叶斯算法基于贝叶斯定理,计算这些概率如下:
-
先验概率: P ( S ) P(S) P(S) 和 P ( H ) P(H) P(H),即在没有特征信息的情况下,一封邮件是垃圾邮件或非垃圾邮件的概率。这可以通过统计已知数据中垃圾邮件和非垃圾邮件的比例来估计。
-
似然概率: P ( D ∣ S ) P(D|S) P(D∣S) 和 P ( D ∣ H ) P(D|H) P(D∣H),即在已知一封邮件是垃圾邮件或非垃圾邮件的情况下,特征数据 D D D 出现的概率。这可以通过统计已知数据中每个特征在垃圾邮件和非垃圾邮件中的出现频率来估计。
-
后验概率: P ( S ∣ D ) P(S|D) P(S∣D) 和 P ( H ∣ D ) P(H|D) P(H∣D),即在给定特征数据 D D D 的情况下,一封邮件是垃圾邮件或非垃圾邮件的概率。根据贝叶斯定理,可以使用以下公式计算:
- 基本概念
-
贝叶斯定理:朴素贝叶斯算法基于贝叶斯定理,该定理描述了在已知先验概率的情况下,如何根据新观察到的数据来更新我们对事件的信念。在分类问题中,我们想要找到给定特征数据的情况下,每个类别的后验概率。
-
朴素假设:高斯朴素贝叶斯模型假设各个特征之间是相互独立的,这被称为"朴素假设"或"条件独立性假设"。虽然这个假设在现实世界中往往不成立,但它使得模型计算更加简单且高效。
-
高斯分布:高斯朴素贝叶斯假设每个特征在每个类别下都服从高斯分布(正态分布)。具体来说,它假设特征的值在给定类别下是以均值和方差为参数的正态分布。
-
参数估计:在训练阶段,模型需要估计每个类别下每个特征的均值和方差。这些估计值将用于计算概率密度函数,从而在测试阶段进行分类。
-
分类决策:一旦模型估计了每个类别下的概率密度函数,它可以使用贝叶斯定理计算后验概率,并选择具有最高后验概率的类别作为分类结果。
-
适用场景:高斯朴素贝叶斯通常用于处理连续型特征的分类问题,例如文本分类、垃圾邮件过滤、医学诊断等。它在实践中表现出色,尤其在数据较少的情况下,因为它对小规模数据集也能提供相对不错的分类性能。
- 代码
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 示例数据集,包括邮件文本和对应的标签
emails = [
"Buy cheap watches!!!",
"Meeting tomorrow at 2pm",
"Hello, how are you?",
"Get a free iPhone now!",
"Don't forget the meeting"
]
labels = [1, 0, 0, 1, 0] # 1表示垃圾邮件,0表示非垃圾邮件
# 文本向量化,将文本转换成特征向量
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 创建朴素贝叶斯分类器
nb_classifier = MultinomialNB()
# 训练模型
nb_classifier.fit(X_train, y_train)
# 新邮件文本
new_emails = [
"Congratulations! You've won a prize.",
"Important meeting at 3pm today."
]
# 文本向量化
new_email_vectors = vectorizer.transform(new_emails)
# 预测分类
predicted_labels = nb_classifier.predict(new_email_vectors)
# 解释分类结果
for i, email in enumerate(new_emails):
if predicted_labels[i] == 1:
print(f"'{email}' 是垃圾邮件.")
else:
print(f"'{email}' 不是垃圾邮件.")
交叉验证
混淆矩阵
混淆矩阵(Confusion Matrix是)用于评估分类模型性能的重要工具,特别是在二分类和多分类问题中。它以表格形式展示了模型的分类结果与实际标签之间的关系。混淆矩阵通常如下所示:
Actual Positive (真正) Actual Negative (真负)
Predicted Positive (假正) True Positive (真正) False Positive (假正)
Predicted Negative (假负) False Negative (假负) True Negative (真负)
-
True Positive (真正,TP):模型正确地将正类别样本分类为正类别。
-
False Positive (假正,FP):模型错误地将负类别样本分类为正类别。也称为“误报”。
-
True Negative (真负,TN):模型正确地将负类别样本分类为负类别。
-
False Negative (假负,FN):模型错误地将正类别样本分类为负类别。也称为“漏报”。
混淆矩阵的主要目的是帮助你分析模型的性能,特别是在不同类型的错误之间进行权衡。以下是一些混淆矩阵中的重要性能指标:
-
准确率(Accuracy):表示模型正确分类的样本数量与总样本数量的比例。计算公式为 (TP + TN) / (TP + TN + FP + FN)。准确率越高越好。
-
精确度(Precision):表示模型预测的正类别样本中有多少是真正的正类别。计算公式为 TP / (TP + FP)。精确度衡量了模型的预测准确性。
-
召回率(Recall):表示模型成功预测的正类别样本占所有正类别样本的比例。计算公式为 TP / (TP + FN)。召回率衡量了模型对正类别的敏感性。
-
F1分数(F1 Score):是精确度和召回率的调和平均数,用于综合考虑精确度和召回率。计算公式为 2 * (Precision * Recall) / (Precision + Recall)。
通过观察混淆矩阵和这些性能指标,你可以更好地了解模型在不同情况下的表现,例如模型的错误类型以及模型的准确性、精确度和召回率等。混淆矩阵是评估分类模型性能的有用工具之一,特别是在理解模型在不同类别上的表现时。















 8654
8654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









