






前言
最近国产的一部电视剧《人民的名义》突然的就火了,随之而来的是各大Coder们的社交网络分析。针对剧本中出现的人名,事件,词频等以图形化的界面展示,清晰化的显示出了剧本的特色。
而对于CSDN的关注人和粉丝的图形化展示,也恰好符合这一个主题(暂且这么认为吧)。本来想做的是公共粉丝(比如哪个人既关注了A,又关注了B),但是在博客中由于权限的问题,获取不到相关的数据,于是只能做下关注人和粉丝的图形化展示了。
先来看下最终效果图。
环境
从上面的效果图上也可以看出,命令行前面有一个(env)的前缀,这是使用了virtualenv的缘故。
virtualenv
使用virtualenv可以很好的隔绝本地的Python环境,而且也不是很占用磁盘空间,对每一个项目使用一个单独的环境还能大大减少出现意外的频率,更好的维护代码,排查错误。
安装virtualenv也非常的简单。
pip install virtualenv
- 1
安装好之后,就可以在任意的目录下,使用命令行执行下面的命令。比如我在桌面新建了一个名为nerwork的文件夹,我就可以进入到这个文件夹内部,打开命令行,执行:
virtualenv env
- 1
这样network文件夹下就会多出一个env的目录,里面的环境就是根据我们本地的Python环境而新建的一个隔离区。
这样还不算完成,最后一步就是激活这个虚拟环境。执行:
env\Scripts\activate.bat
- 1
如果前缀变成了(env)XXX,那就说明虚拟环境激活成功了,我们只需要在这个虚拟环境中进行开发就可以了。
第三方库
这里需要用到一些第三方的库,通过pip freeze命令,可以详细的查看每一个库的名称以及精确的版本号。
(env) C:\Users\biao\Desktop\network\code\relationanalysis>pip freezeappdirs==1.4.3beautifulsoup4==4.6.0csdnbackup==0.0.1cycler==0.10.0decorator==4.0.11matplotlib==2.0.2networkx==1.11numpy==1.12.1packaging==16.8pyparsing==2.2.0python-dateutil==2.6.0pytz==2017.2requests==2.14.2six==1.10.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
但是我们需要安装的却不多,因为很多库是与之关联的,pip命令会自动把依赖的包帮我们安装。我们需要安装的包如下:
- networkx:
pip install networkx - csdnbackuo: 这个包是我之前写过的一个关于CSDN博客备份的工具库,源码上传到了GitHub。而且为了方便使用,我把它做成了一个.whl包,下面是下载地址:
https://github.com/guoruibiao/csdn-blog-backup-tool
下载里面适合自己Python版本的whl文件,然后执行pip install csdnbackup-0.0.1-py2.py3-none-any.whl即可。
这样,依赖的库就基本上安装成功了。
模块化
完成一个任务,首先并不是上来就写代码。而是先搞清楚需求。比如这里,要做的是关注人和粉丝的图形化展示。那么仔细想想,不难发现可以细化这个大任务。
- 获取粉丝信息
- 获取关注人信息
- 关于图形化展示的部分
这样一来,我们只需要每次完成一个小任务,最终通过集成测试就能完成任务了。下面针对每一个小任务进行实现。
爬虫模块
这里的爬虫模块不是必须要用我那个库,你也可以自己写。但是重复造轮子是一件很枯燥的事,人生苦短,咱还是用轮子吧。
关于模拟登陆
from csdnbackup.login import Login
- 1
然后使用下面的代码即可实现模拟登陆。
# coding: utf8# @Author: 郭 璞# @File: logintest.py # @Time: 2017/5/18 # @Contact: 1064319632@qq.com# @blog: http://blog.csdn.net/marksinoberg# @Description: csdnbackup模拟登陆测试from csdnbackup.login import Loginimport getpass#username = input('请输入您的账号:')password = getpass.getpass(prompt='请输入您的密码:')loginer = Login(username=username, password=password)session = loginer.login()headers = loginer.headersheaders['Host'] = 'blog.csdn.net'response = session.get('http://blog.csdn.net/marksinoberg', headers=headers)print(response.status_code)print(response.text)print("网页总长度:", len(response.text))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
没有图不足以证实此轮子的好用。
爬取数据
巧妇难为无米之炊,下面来弄点米出来。
# coding: utf8# @Author: 郭 璞# @File: spider.py # @Time: 2017/5/18 # @Contact: 1064319632@qq.com# @blog: http://blog.csdn.net/marksinoberg# @Description: 爬虫,爬取博主的粉丝信息from csdnbackup.login import Loginfrom bs4 import BeautifulSoupimport mathimport numpy as npclass Fans(object): def __init__(self, domain, password): self.domain = domain self.loginer = Login(username=domain, password=password) self.session = self.loginer.login() # set the headers self.headers = self.loginer.headers self.headers['Referer'] = 'http://blog.csdn.net/{}'.format(self.domain) self.headers['Host'] = 'my.csdn.net' def get_fans_number(self): url = 'http://my.csdn.net/{}'.format(self.domain) response = self.session.get(url=url, headers=self.headers) # print(response.text) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') return soup.find('a', {'href': '/my/fans'}).get_text() else: return 0 def get_fans(self): fans = [] url = 'http://my.csdn.net/{}'.format(self.domain) fans_number = self.get_fans_number() pages = math.ceil(int(fans_number)/20) # pages+1 for index in range(1, pages): url = 'http://my.csdn.net/my/fans/{}'.format(index) response = self.session.get(url=url, headers=self.headers) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') user_names = soup.find_all('a', {'class': 'user_name'}) fans.extend([str(username.attrs['href']).lstrip('/') for username in user_names]) else: raise Exception("获取第{}页数据失效".format(index)) return fans def get_follow_number(self): url = 'http://my.csdn.net/{}'.format(self.domain) response = self.session.get(url=url, headers=self.headers) # print(response.text) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') return soup.find('a', {'href': '/my/follow'}).get_text() else: return 0 def get_follow(self): follows = [] url = 'http://my.csdn.net/{}'.format(self.domain) follow_number = self.get_follow_number() pages = math.ceil(int(follow_number) / 20) # pages+1 for index in range(1, pages): url = 'http://my.csdn.net/my/follow/{}'.format(index) response = self.session.get(url=url, headers=self.headers) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') user_names = soup.find_all('a', {'class': 'user_name'}) follows.extend([str(username.attrs['href']).lstrip('/') for username in user_names]) else: raise Exception("获取第{}页数据失效".format(index)) return followsclass ListUtils(object): """ 利用numpy 进行数据的筛选 """ def __init__(self): pass @staticmethod def comminInList(self, x=[], y=[]): return np.intersect1d(ar1=x, ar2=y, assume_unique=True)if __name__ == '__main__': fans = Fans(domain='你的用户名', password='你的密码') # fans1 = fans.get_fans(username='marksinoberg') # result = ListUtils.comminInList(fans1, fans2) # print(result) follows = fans.get_follow() print(follows)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
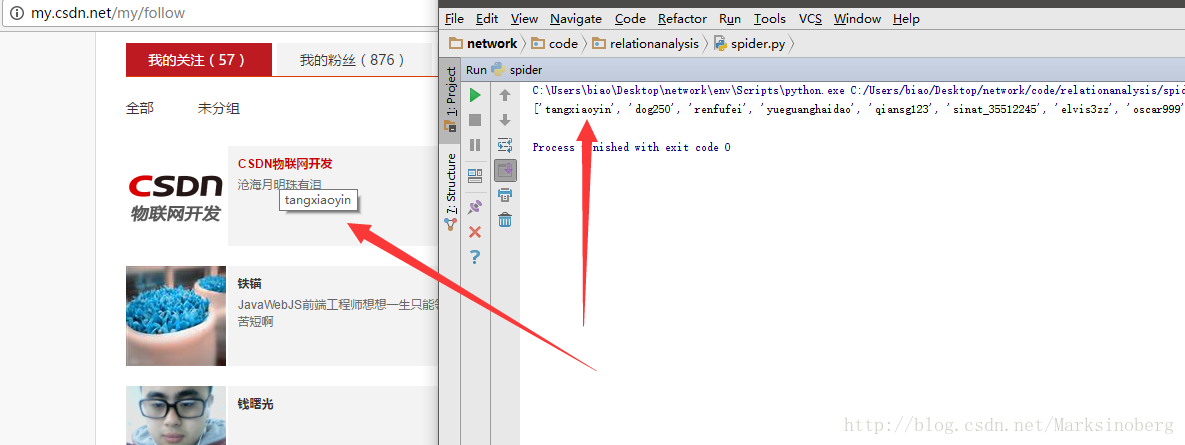
对照一下运行结果,关注人信息获取如下。
图形化
图形化需要借助matplotlib来画图,而载体就是networkx,所以我们需要对此进行安装。在此不再过多叙述。
然后就是对于networkx的使用了。
步骤
一般有如下几个步骤:
- 声明graph
- 填充节点和边
- 画出图形
中文节点问题
默认的matplotlib 对于中文支持的不太友好。为了解决这一个问题,可以通过如下步骤实现。
到matplotlib的安装目录下找到字体文件夹, 比如我的是
C:\Users\biao\Desktop\network\env\Lib\site-packages\matplotlib\mpl-data\fonts\ttf然后从本地的字体库(比如C:\Windows\Fonts\XX.ttf)中拷贝一份,重命名为DejaVuSans.ttf,放置到刚才的matplotlib字体文件夹下即可。为什么要这么做?答案就是matplotlib默认使用DejaVuSans.ttf。
实战
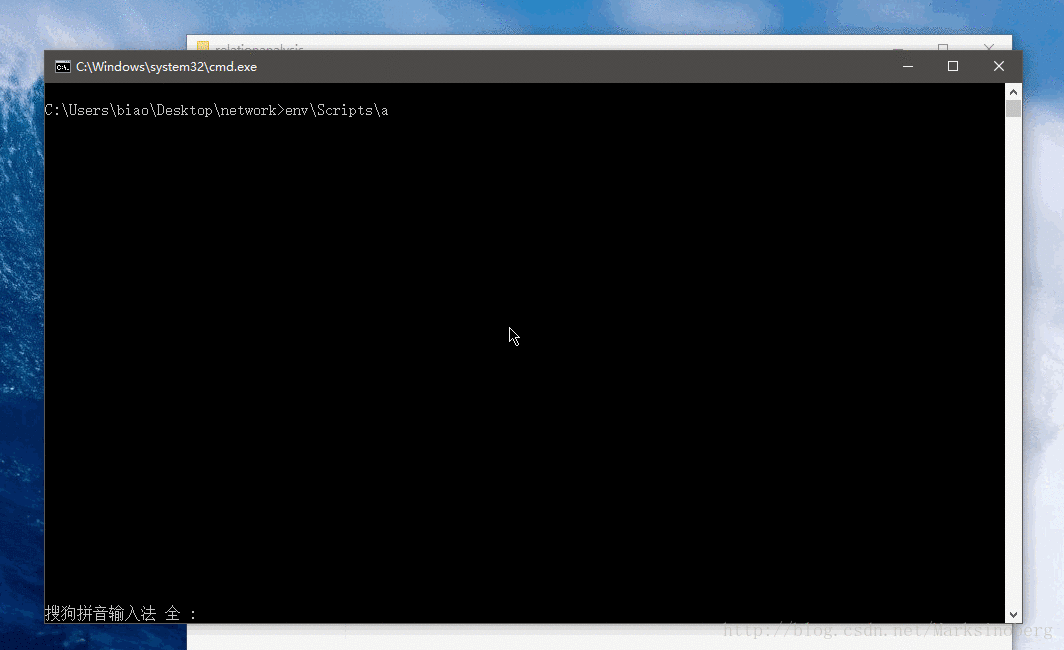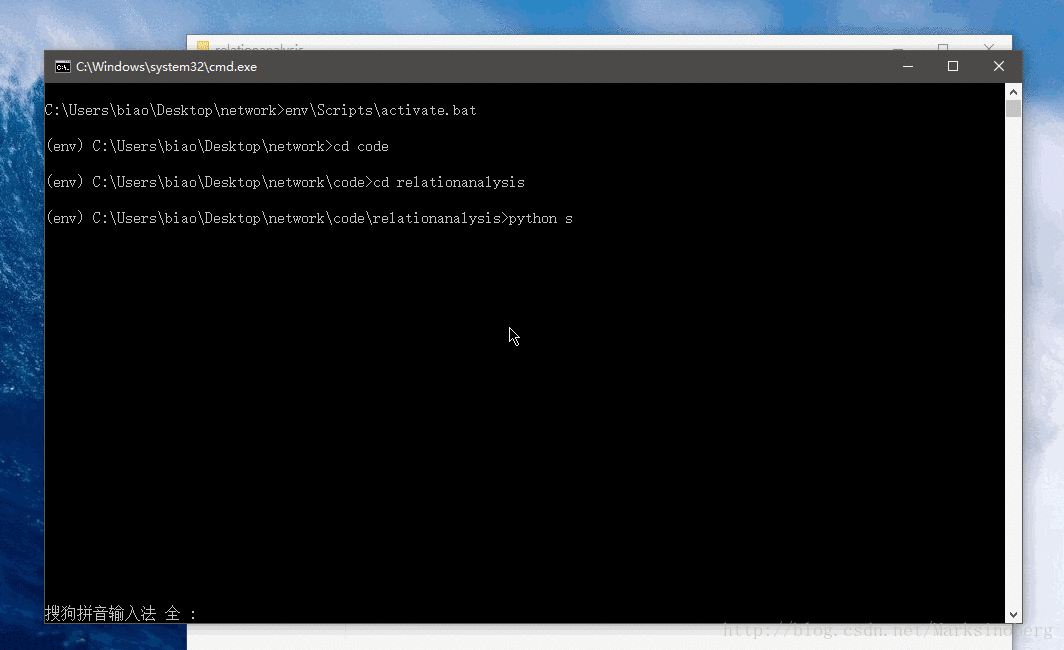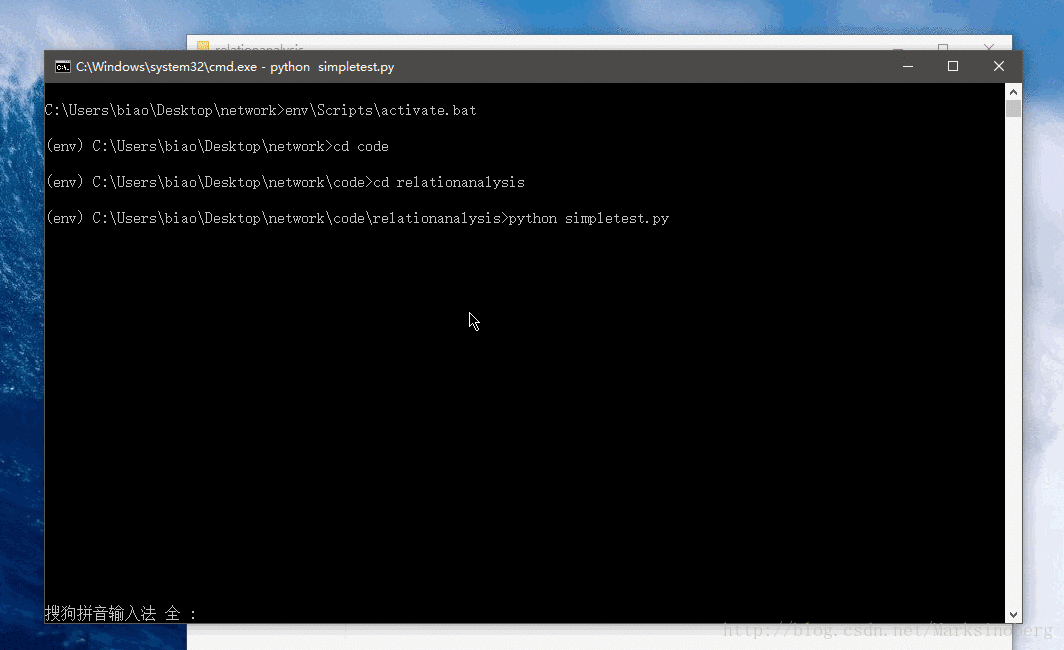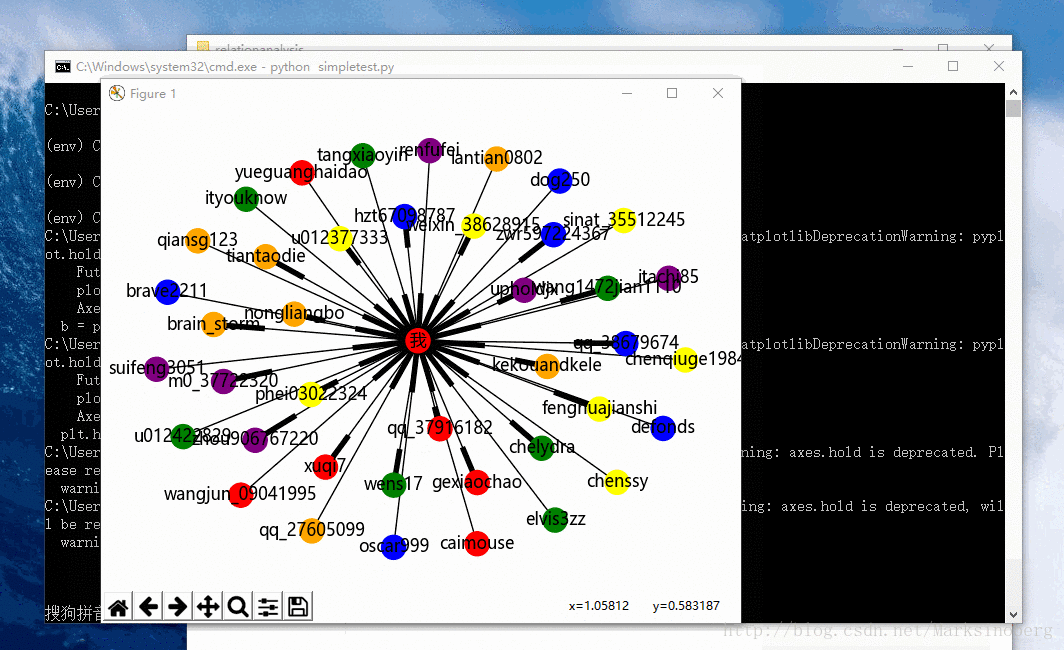
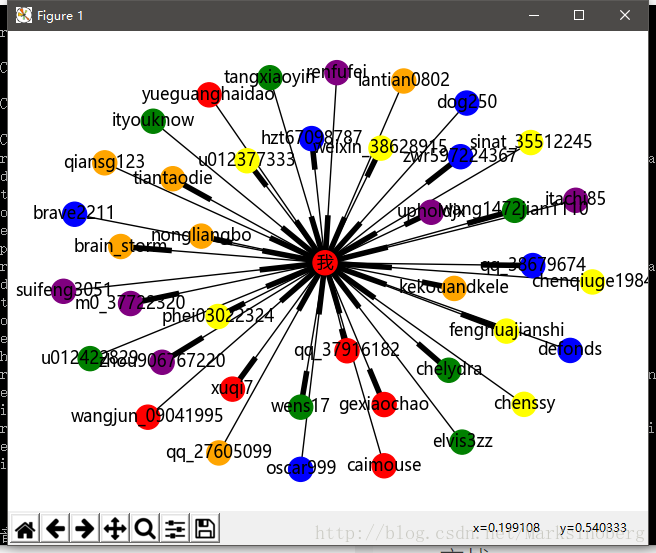
下面实战一下CSDN的关注人和粉丝跟自己的关系演示。因为粉丝人数过多的话,会导致生成的图片重叠度较大,所以这里选取前20个关注人和前20个粉丝。
import networkx as nximport matplotlib.pyplot as pltimport spiderfans = spider.Fans(domain='你的用户名', password='你的密码')fans_names = fans.get_fans()[:20]follow_names = fans.get_follow()[:20]nodes = fans_namesrelations1 = [('我', username) for username in fans_names]relations2 = [(username, '我') for username in follow_names]colors = ['red', 'orange', 'yellow', 'green', 'blue', 'purple']graph = nx.DiGraph()graph.add_node('我')graph.add_nodes_from(fans_names)graph.add_edges_from(relations1)graph.add_edges_from(relations2)nx.draw(graph, with_labels=True, hold=True, node_color=colors)plt.title('CSDN 博客关注与粉丝图形化显示')plt.axis('off')plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
生成的图片如下:
总结
对于networkx,这里讲的并不是很多,也可以说就没怎么讲。这是因为官方文档的却是够详细了。而且越往深处看,越觉惊喜。基本上对于社交网络的分析,它是一个很不错的选择了。
还有就是关于轮子,平时多写一些可靠的轮子,说不一定哪天就用到了。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow














 6066
6066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









