







1.实验目的
学习AdaBoost算法,并利用Adaboodst分类器对Iris dataset进行分类
2.理论方法
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。
AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。
它的自适应在于:前一个弱分类器分错的样本的权值(样本对应的权值)会得到加强,权值更新后的样本再次被用来训练下一个新的弱分类器。在每轮训练中,用总体(样本总体)训练新的弱分类器,产生新的样本权值、该弱分类器的话语权,一直迭代直到达到预定的错误率或达到指定的最大迭代次数。
总体——样本——个体三者间的关系需要搞清除
总体N。样本:{ni}i从1到M。个体:如n1=(1,2),样本n1中有两个个体。
算法原理
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。
假设我们的训练样本是
T
=
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
T={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)}
T=(x1,y1),(x2,y2),...,(xm,ym)
训练集在第k个弱学习器的输出权重为
D
(
K
)
=
(
ω
k
1
,
ω
k
2
,
.
.
.
.
,
ω
k
m
)
;
ω
1
i
=
1
m
;
i
=
1
,
2
,
.
.
.
,
m
D(K)=(\omega_{k1},\omega_{k2},....,\omega_{km});\omega_{1i}=\frac 1m;i=1,2,...,m
D(K)=(ωk1,ωk2,....,ωkm);ω1i=m1;i=1,2,...,m
由于多元分类是二元分类的推广,这里假设我们是二元分类问题,输出为{-1,1},则第k个弱分类器Gk(x)在训练集上的加权误差率为:
e
k
=
P
(
G
k
(
x
i
)
≠
y
i
)
=
∑
i
=
1
m
ω
k
i
I
(
G
k
(
x
i
)
≠
y
i
)
e_k=P(G_k(x_i)\not=y_i)=\sum_{i=1}^{m}{\omega_{ki}I(G_k(x_i)\not=y_i)}
ek=P(Gk(xi)=yi)=i=1∑mωkiI(Gk(xi)=yi)
看弱学习器权重系数,对于二元分类问题,第k个弱分类器Gk(x)的权重系数为:
α
k
=
1
2
log
1
−
e
k
e
k
\alpha_k=\frac 12\log{\frac{1-e_k}{e_k}}
αk=21logek1−ek
更新更新样本权重D。假设第k个弱分类器的样本集权重系数为
D
(
k
)
=
(
ω
k
1
ω
k
1
,
ω
k
2
,
.
.
.
.
,
ω
k
m
)
D(k)=(\omega_{k1}\omega_{k1},\omega_{k2},....,\omega_{km})
D(k)=(ωk1ωk1,ωk2,....,ωkm) ,则对应的第k+1个弱分类器的样本集权重系数为:
w
k
+
1
,
i
=
w
k
i
Z
K
exp
(
−
α
k
y
i
G
k
(
x
i
)
)
Z
k
=
∑
i
=
1
m
w
k
i
exp
(
−
α
k
y
i
G
k
(
x
i
)
)
w_{k+1, i}=\frac{w_{k i}}{Z_{K}} \exp \left(-\alpha_{k} y_{i} G_{k}\left(x_{i}\right)\right) Z_{k}=\sum_{i=1}^{m} w_{k i} \exp \left(-\alpha_{k} y_{i} G_{k}\left(x_{i}\right)\right)
wk+1,i=ZKwkiexp(−αkyiGk(xi))Zk=i=1∑mwkiexp(−αkyiGk(xi))
Z
k
Z_k
Zk是规范化因子,它使
D
k
D_k
Dk成为一个概率分布。
集合策略,Adaboost分类采用的是加权求和法,最终的强分类器为
f
(
x
)
=
s
i
g
n
(
∑
k
=
1
K
α
x
G
k
(
x
)
)
f(x)=sign(\sum_{k=1}^{K}{\alpha_xG_k(x)})
f(x)=sign(k=1∑KαxGk(x))
3. 实验数据及方法
1.导入必要的库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
from sklearn import datasets
import numpy as np
import warnings
warnings.filterwarnings('ignore') #this will ignore the warnings.it wont display warnings in notebook
2.导入数据集
iris = datasets.load_iris()
data = pd.DataFrame(data=iris.data,columns=iris.feature_names)
data['target'] = iris.target
data.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 5.0 | 3.6 | 1.4 | 0.2 | 0 |
3.给特征改一下名字,方便我们实验
data = data.rename(columns={'sepal length (cm)':'sepal.length',
'sepal width (cm)':'sepal.width',
'petal length (cm)':'petal.length',
'petal width (cm)':'petal.width'
})
data.head()
| sepal.length | sepal.width | petal.length | petal.width | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
4.画出三种花占的比例
我们可以从图中看出,三个种类占的比例非常平均
size = data.target.value_counts()
colors = ['lightblue', 'lightgreen','lightyellow']
labels = 'setosa', 'versicolor', 'virginica'
explode = [0, 0.01, 0.01]
my_circle = plt.Circle((0, 0), 0.7, color = 'white')
plt.rcParams['figure.figsize'] = (9, 9)
plt.pie(size, colors = colors, labels = labels, shadow = True, explode = explode, autopct = '%.2f%%')
plt.title('Distribution of Feature', fontsize = 20)
p = plt.gcf()
p.gca().add_artist(my_circle)
plt.legend()
# plt.savefig('Distribution of Feature')
plt.show()

5.绘制属性speal length与类别的关系
我们可以从图中发现,0类花的speal length值整体最低,2类花的speal length值整体最高
plt.rcParams['figure.figsize'] = (12, 9)
sns.boxplot(data['target'], data['sepal.length'], palette = 'viridis')
plt.title('Relation of sepal length with target', fontsize = 20)
# plt.savefig('Relation of sepal length with target')
plt.show()

6.绘制属性sepal width与类别的关系图
由图可知,0类的sepal width值整体较高,1类和2类sepal width值差距不大
plt.rcParams['figure.figsize'] = (12, 9)
sns.violinplot(data['target'], data['sepal.width'], palette = 'colorblind')
plt.title('Relation of sepal width with Target', fontsize = 20, fontweight = 30)
# plt.savefig('Relation of sepal width with Target')
plt.show()

7.绘制属性petal length和类别的关系图
我们从图中可以发现3类花的petal length值都比较集中,0类的数值最低,1类比0类高,2类最高。
plt.rcParams['figure.figsize'] = (15, 9)
# sns.swarmplot(data['target'], data['petal.length'], palette = 'winter', size = 10)
sns.boxplot(data['target'], data['petal.length'], palette = 'winter')
plt.title('Relation between petal length and target', fontsize = 20, fontweight = 30)
# plt.savefig('Relation between petal length and target')
plt.show()

8.绘制petal width和类别的关系图
petal width和petal length值的分布比较相似
plt.rcParams['figure.figsize'] = (12, 9)
sns.boxplot(data['target'], data['petal.width'], palette = 'Set3')
plt.title('Relation of petal width with Target', fontsize = 20, fontweight = 30)
# plt.savefig('Relation of petal width with Target')
plt.show()

除特征sepal width看不太出来,不同特征间sepal.width值的变化。我们从其他特征的关系图中就能看出特征和类别之间的关系,0类的三个特征值最低,1类的三个值第二高,2类的最高。
9.绘制特征间相关系数的热力图
图中两个特征间相关系数越大,方块的颜色就越深。
我们可从图中发现speal length与petal width和petal length相关系数都比较大,petal length 和petal width相关系数比较大
%matplotlib inline
plt.rcParams['figure.figsize'] = (10, 10)
plt.style.use('ggplot')
ax = sns.heatmap(data[['sepal.length','sepal.width','petal.length','petal.width']].corr(),linewidths=.5, annot = True, cmap = 'YlGnBu')
plt.title('Heatmap for the Dataset', fontsize = 20)
ax.set_ylim(4.0, 0)
ax.set_xlim(0,4.0)
plt.show()

我们选择这三个特征画出三维的散点图
import plotly.graph_objs as go
import plotly.offline as py
trace = go.Scatter3d(
x = data['sepal.length'],
y = data['petal.length'],
z = data['petal.width'],
name = 'Marvel',
mode = 'markers',
marker = dict(
size = 10,
color = data['sepal.length']
)
)
df = [trace]
layout = go.Layout(
title = 'sepal.length vs petal.length vs petal.width',
margin=dict(
l=0,
r=0,
b=0,
t=0
),
scene = dict(
xaxis = dict(title = 'sepal.length'),
yaxis = dict(title = 'petal.length'),
zaxis = dict(title = 'petal.width')
)
)
fig = go.Figure(data = df, layout=layout)
py.iplot(fig)
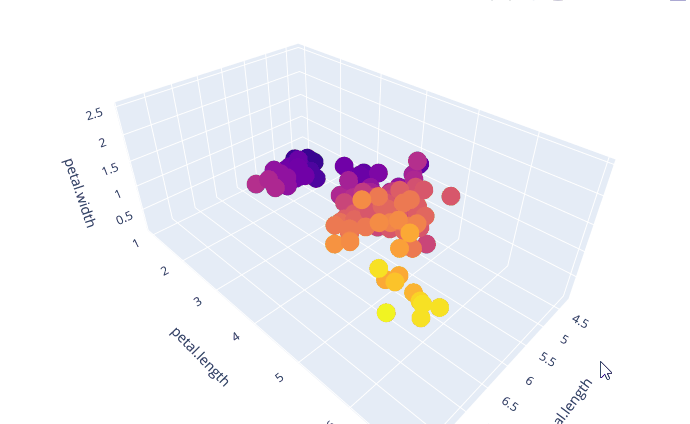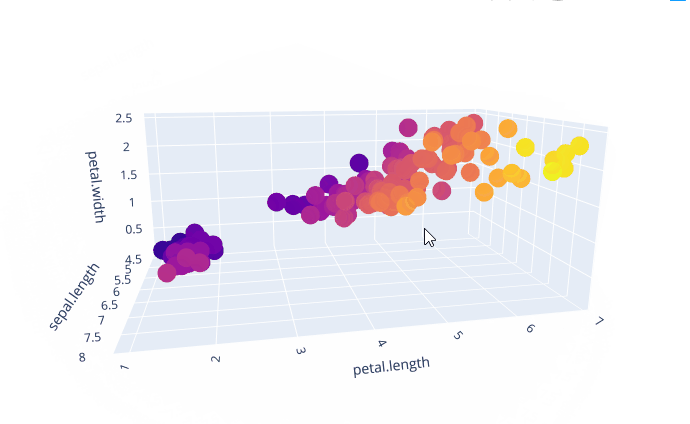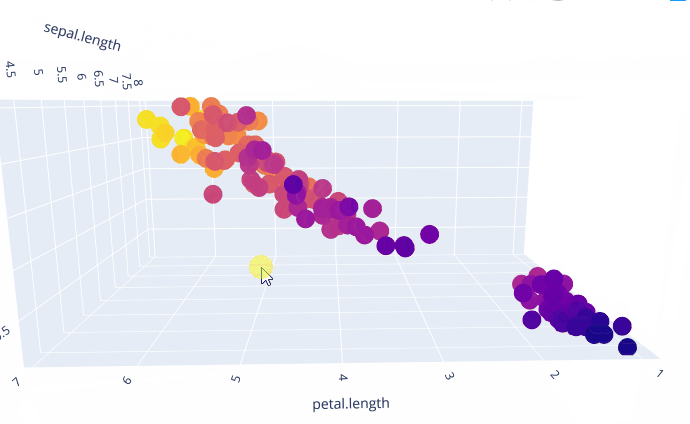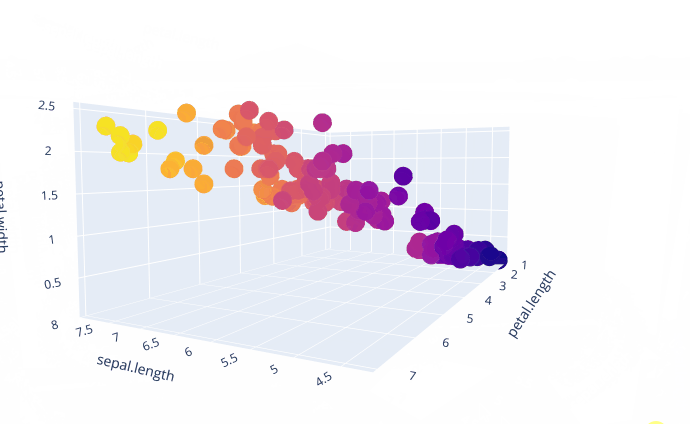
我们从中可以比较清晰的看出,这三个属性是成线性相关的。
10.使用随机森林算法进行训练
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data[['sepal.length','sepal.width','petal.length','petal.width']],
data['target'],
test_size = 0.3,
random_state = 0)
# getting the shapes
print("Shape of x_train :", x_train.shape)
print("Shape of x_test :", x_test.shape)
print("Shape of y_train :", y_train.shape)
print("Shape of y_test :", y_test.shape)
'''
Shape of x_train :(105, 4)
Shape of x_test :(45, 4)
Shape of y_train :(105,)
Shape of y_test :(45,)
'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
model = RandomForestClassifier(n_estimators = 50, max_depth = 5) #n_estimators树的数目
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
y_pred = model.predict(x_test)
4.实验结果及分析
# evaluating the model
print("Training Accuracy :", model.score(x_train, y_train))
print("Testing Accuracy :", model.score(x_test, y_test))
cm = confusion_matrix(y_test, y_pred)
plt.rcParams['figure.figsize'] = (5, 5)
ax = sns.heatmap(cm, annot = True, annot_kws = {'size':15}, cmap = 'PuBu')
ax.set_ylim(3.0, 0)
ax.set_xlim(0,3.0)
# classification report
cr = classification_report(y_test, y_pred)
print(cr)
# plt.savefig('混淆矩阵.png')
Training Accuracy :1.0
Testing Accuracy : 0.9777777777777777
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 | 16 |
| 1 | 1.00 | 0.94 | 0.97 | 18 |
| 2 | 0.92 | 1.00 | 0.96 | 11 |
| accuracy | 0.98 | 45 | ||
| macro avg | 0.97 | 0.98 | 0.98 | 45 |
| weighted avg | 0.98 | 0.98 | 0.98 | 45 |
生成混淆矩阵的热力图

11.使用PDPbox库对特征进行分析
Partial Dependency Plots(PDP)会展示一个或两个特征对于模型预测的边际效益(J. H. Friedman 2001)。PDP可以展示一个特征是如何影响预测的。与此同时,我们可以通过绘制特征和预测目标之间的一维关系图或二维关系图来了解特征与目标之间的关系。
sepal.length与类别
图为当sepal.length取不同值时,预测概率随sepal.length值变化的走势图
- Y轴表示预测相较于基准线或最左值得增加值
- 蓝色区域表示置信区间
- 从图中我们可以发现随着sepal.length变大,预测为0类的概率为负值,负概率先增加然后趋于平稳;预测为1类准确度先上升,随之趋于平稳;预测为2类的概率为负值,且负概率略有上升降但变化幅度不大。故由图可知,sepal.length越大,越有可能是1类花,越不可能是0类花
base_features = data.columns.values.tolist()
feat_name = 'sepal.length'
pdp_dist = pdp.pdp_isolate(model=model, dataset=x_test, model_features = base_features[:4], feature = feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
# plt.savefig('PDP sepal.length.png')
plt.show()

sepal.width与类别
sepal.width值变大时,
- 预测为0类的概率增大
- 预测为1类的概率一开始会增加,然后下降,最后变成负值
- 预测为2类的概率为负值,且负概率增加
故,sepal.width值越大,越有可能是0类,越不可能是2类
base_features = data.columns.values.tolist()
feat_name = 'sepal.width'
pdp_dist = pdp.pdp_isolate(model=model, dataset=x_test, model_features = base_features[:4], feature = feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
# plt.savefig('PDP sepal.width.png')
plt.show()

petal.length与类别
petal.length值增加时,
- 预测为0类的概率为负值,且负概率值值大幅增加
- 预测为1类的概率会先增加,后下降,最后变为负值
- 预测为2类的概率会增加
可见petal.length越大的花,肯定不是0类,更有可能是1类
base_features = data.columns.values.tolist()
feat_name = 'petal.length'
pdp_dist = pdp.pdp_isolate(model=model, dataset=x_test, model_features = base_features[:4], feature = feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
# plt.savefig('PDP petal.length.png')
plt.show()

petal.width与类别
随着petal.width值得增加,
- 预测为0类得概率为负值,且负概率大幅增长
- 预测为1类得概率一开始增长较快,但大到一定程度之后概率开始下降
- 预测为2类概率越来越大
可知,petal.width值越大,越不可能是0类,但在一定范围内很可能是1类,超过了范围后更有可能是2类。
base_features = data.columns.values.tolist()
feat_name = 'petal.width'
pdp_dist = pdp.pdp_isolate(model=model, dataset=x_test, model_features = base_features[:4], feature = feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
# plt.savefig('PDP petal.width.png')
plt.show()

12.使用shap库对特征进行分析
SHAP值的主要思想就是Shapley值,Shapley值是一个来自合作博弈论(coalitional game theory)的方法,由Shapley在1953年创造的Shapley值是一种根据玩家对总支出的贡献来为玩家分配支出的方法,玩家在联盟中合作并从这种合作中获得一定的收益。用shaply值去解释机器学习的预测的话,其中“总支出”就是数据集单个实例的模型预测值,“玩家”是实例的特征值,“收益”是该实例的实际预测减去所有实例的平均预测。SHAP知识点全汇总-知乎
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(x_test)
shap.summary_plot(shap_values, x_test, plot_type="bar")
# plt.savefig('shape value.png')
可以从图中看到,每个特征对每个类的预测准确度的贡献。

SHAP 摘要图绘制
图中的点:
- 垂直位置显示了它所描述的特征
- 颜色显示数据集中这一行的特征值是高还是低
- 水平位置显示该值的影响是导致较高的预测还是较低的预测。
shap.summary_plot(shap_values[0], x_test)
# plt.savefig('shape feature 0.png')

由图可知,petal.length和petal.width值越高,会导致模型准确率降低;值越低,模型预测准确率就越高。
shap.summary_plot(shap_values[1], x_test)
#plt.savefig('shape feature 1.png')

shap.summary_plot(shap_values[2], x_test)
#plt.savefig('shape feature 2.png')

从这三个图来看,主要影响模型准确率的还是petal.length和petal.width两个特征,speal.length和speal.width的影响值比较小,很多特征值贡献了比较小的值。由于特征值不多,如果特征数量如下图,我们对于不同特征对模型准确率的贡献程度会有一个更加直观的认识。哪些特征对于模型更重要,一目了然。

将预测进行分解
Shap值显示给定的特性对我们的预测有多大的改变(与我们在该特性的某个基线值上进行预测相比)。假设我们想知道当petal.length取4.9时预测是什么。
# let's create a function to check the patient's conditions
def analysis(model, target):
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(target)
shap.initjs()
return shap.force_plot(explainer.expected_value[1], shap_values[1], target)
analysis(model, x_test.iloc[1,:])

上面的解释显示了推动模型输出从基本值(我们传递的训练数据集中的平均模型输出)到模型输出的每个特性。将预测推高的特征用红色表示,将预测推低的特征用蓝色表示。
- 这里的base value是0.3105,我们的预测值是0.20
- petal.length=4.9对预测增加的影响最大
- petal.width=2对预测减少的影响最大















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









