







前言
老规矩,先上项目完整代码,再详细讲解代码每一段内容。博文结尾附Github地址,里面包含我在完成本项目过程中,不同版本的代码。讲解不清的地方请多包涵,我们开始吧!
0、泰坦尼克号灾难生存预测代码
# Author: Gatzliu
# Date: 2018.08.30
# Abstract: Titanic6_embarked: with familysize ,and fare not scaling, but range. Add embarked
# -*- coding:utf-8 -*-
import numpy as np #科学计算
import pandas as pd #数据分析
from pandas import Series, DataFrame
import re # 正则
# 保证图表中的字不为乱码
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 1 加载训练集数据
data_train = pd.read_csv("all/train.csv")
# 2 观察数据 图表等
# 本块会在后续数据分析处讲解,正式代码中删除了本部分
# 3 数据处理
# 3.1补全缺失数据 Age Cabin
from sklearn.ensemble import RandomForestRegressor
# (1) 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])# 一个或是2个冒号都一样的
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
# (2)补全 Cabin属性,由于缺失较多,以Cabin是否为空为特征
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)
# (3)补全embarked 使用众数补全(.dropna()删除缺失值,.mode()取众数 values取值)
data_train.Embarked[data_train.Embarked.isnull()] = data_train.Embarked.dropna().mode().values
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
# 3.2 提取名字中信息
data_train['Title'] = data_train['Name'].map(lambda x: re.compile(", (.*?)\.").findall(x)[0])
title_Dict = {}
title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
data_train['Title'] = data_train['Title'].map(title_Dict)
dummies_title = pd.get_dummies(data_train['Title'], prefix="Title")
data_train = pd.concat([data_train,dummies_title], axis=1)
# 3.3 对部分特征进行二值化处理
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
# 联合二值化处理后的特征
df = pd.concat([data_train, dummies_Cabin, dummies_Sex, dummies_Pclass,dummies_Embarked], axis=1)
# 删除不用的特征
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked','Title'], axis=1, inplace=True) # 删除指定列
df.head()
# 3.4 Age特征分段 并二值化
#df['Age'].values.reshape(-1,1)
bins = [0, 12, 18, 65, 100]
df['Age_group'] = pd.cut(df['Age'], bins)
#by_age = df.groupby('Age_group')['Survived'].mean()
dummies_Age = pd.get_dummies(df['Age_group'], prefix= 'Age')
df = pd.concat([df, dummies_Age], axis=1)
df.drop(['Age','Age_group'], axis=1, inplace=True)
df.head()
# 3.5 fare特征分段 并二值化
df['Fare_bin'] = pd.qcut(df['Fare'], 5)
#print (df[['Fare_bin', 'Survived']].groupby(['Fare_bin'], as_index=False).mean().sort_values(by='Fare_bin', ascending=True))
dummies_Fare_bin = pd.get_dummies(df['Fare_bin'], prefix= 'Fare_bin')
df = pd.concat([df, dummies_Fare_bin], axis=1)
df.drop(['Fare','Fare_bin'], axis=1, inplace=True)
df.head()
# #3.6 对 SibSp Parch合并为family_size
df['Family_Size'] = df['Parch'] + df['SibSp'] + 1
df[['Family_Size','Survived']].groupby(['Family_Size']).mean().plot.bar()
df.drop(['SibSp','Parch'], axis=1, inplace=True)
df.head()
# 4、划分训练集、验证集
# 分割数据,按照 训练数据:cv数据 = 0.75:0.25的比例
from sklearn import cross_validation
from sklearn import linear_model
from sklearn.ensemble import BaggingRegressor
# 划分
split_train, split_cv = cross_validation.train_test_split(df, test_size=0.25, random_state=0)
# 训练集
train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*') #过滤规则
print (train_df.shape) # 大小
print (train_df.columns.tolist()) # 列名
train_df.head() #PassengerId age fare embarked 都没有了 说明上述过滤规则没问题,并且第一列是标签列
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
#用生成的模型 对 验证集 数据进行预测
cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')
predictions = bagging_clf.predict(cv_df.as_matrix()[:,1:]) # 返回的是验证集的预测标签
# 计算正确率
from sklearn.metrics import accuracy_score
accuracy_score(cv_df.as_matrix()[:,0],predictions.astype(np.int32))
# 5 正式训练数据
from sklearn.ensemble import BaggingRegressor
from sklearn import linear_model
# 用正则取出我们要的属性值,其实就是过滤掉了PassengerID列 但是这里好像把age 和fare embark也过滤掉了 什么鬼 #对的,因为age 和fare用 Age_scale和fare_scale特征代替了
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')
train_np = train_df.as_matrix() #r如果这里不转成矩阵那么就不能用[:,0]这种表述,而必须用 train_df['具体列名或者列名组成的列表,旧金山犯罪那个比赛就是用的列名组成的列表']
# y即Survival结果
y = train_np[:, 0] # 整个数据集
# X即特征属性值
X = train_np[:, 1:]
print ('训练集规模:',X.shape)
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y) # 训练完毕
# 6 处理测试集 (对测试集做与前面一样的处理)
data_test = pd.read_csv('all/test.csv')
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
xp = null_age[:, 1:]
predictedAges = rfr.predict(xp)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
#处理embarked
#补缺失
data_test.Embarked[data_test.Embarked.isnull()] = data_test.Embarked.dropna().mode().values
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
# 提取名字中信息
data_test['Title'] = data_test['Name'].map(lambda x: re.compile(", (.*?)\.").findall(x)[0])
title_Dict = {}
title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
data_test['Title'] = data_test['Title'].map(title_Dict)
dummies_title = pd.get_dummies(data_test['Title'], prefix="Title")
data_test = pd.concat([data_test,dummies_title], axis=1)
#二值化
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
#dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Sex, dummies_Pclass, dummies_Embarked], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked','Title'], axis=1, inplace=True)
# 年龄分段处理
bins_test = [0, 12, 18, 65, 100]
df_test['Age_group'] = pd.cut(df_test['Age'], bins_test)
dummies_Age = pd.get_dummies(df_test['Age_group'], prefix= 'Age')
df_test = pd.concat([df_test, dummies_Age], axis=1)
df_test.drop(['Age','Age_group'], axis=1, inplace=True)
# fare特征分段 并二值化
df_test['Fare_bin'] = pd.qcut(df_test['Fare'], 5)
#print (df[['Fare_bin', 'Survived']].groupby(['Fare_bin'], as_index=False).mean().sort_values(by='Fare_bin', ascending=True))
dummies_Fare_bin = pd.get_dummies(df_test['Fare_bin'], prefix= 'Fare_bin')
df_test = pd.concat([df_test, dummies_Fare_bin], axis=1)
df_test.drop(['Fare','Fare_bin'], axis=1, inplace=True)
#df.head()
# 对 SibSp Parch合并为family_size
df_test['Family_Size'] = df_test['Parch'] + df_test['SibSp'] + 1
df_test.drop(['SibSp','Parch'], axis=1, inplace=True)
df_test.head()
# 过滤规则
test = df_test.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')# 过滤掉PassengerId 、 age 和 fare embark
print ('测试集规模: ',test.shape)
test.head()
# 7 生成预测结果
predictions = bagging_clf.predict(test)# 获得预测的标签
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)
print ("End")
1、加载数据集
# 1 加载训练集数据
data_train = pd.read_csv("all/train.csv")
利用pandas库中的 read_csv()函数读取本地csv文件,返回类型为 DataFrame 数据结构的 表。
2、观察数据(图表等)
这部分是前期大量的数据数据分析工作,我们在这一步分析特征,看分布、看与生存率关系、看价值等等,这些数据分析的代码是整个项目的中间代码,在最终代码中并不出现,因此在本篇没有给出。
这些数据分析工作的代码、可视化图形,参见我的这篇博客。
[ 机器学习——画图方法 - titanic数据初步分析 ]
3、数据处理
通过对数据的观察,我们进行数据的处理工作
3.1 补全缺失数据 Age-Cabin-Embarked
通过观察数据,可以发现Age 和 Cabin特征有缺失,但缺失不多,因此,我们可以将缺失数据补上。
关于缺失值处理方法:
1、如果数据集很多,但有很少的缺失值,可以删掉带缺失值的行;
2、如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
3、对于标称属性,可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。比如船舱号Cabin这一属性,缺失可能代表并没有船舱。
(1)补全Age信息
使用随机森林分类器,用’Fare’, ‘Parch’, ‘SibSp’, 'Pclass’四个特征预测Age。
首先用DataFrame 的.notnull() 和 .isnull()将Age列分为两个,转成矩阵(为什么要转),用notnull训练模型,然后对isnull进行预测,最后使用.loc 方法填补缺失值。
from sklearn.ensemble import RandomForestRegressor
# (1) 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])# 一个或是2个冒号都一样的
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
data_train, rfr = set_missing_ages(data_train)
- DataFrame 的 .notnull() 和isnull()这两个功能很方便,注意学习。
- .loc 方法比较方便,注意学习。 [ Pandas中loc用法——索引、补全缺失值 ]
- model.predict() 和 model.predict_probe() 区别 [ sklearn中predict与predict_proba区别 ]
- 关于随机森林的回归的用法,参见
[随机森林回归 sklearn.ensemble.RandomForestRegressor ]
(2)补全Cabin信息
Cabin信息缺失较多,因此采用是否有Cabin作为特征进行训练。
# (2)补全 Cabin属性,由于缺失较多,以Cabin是否为空为特征
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train = set_Cabin_type(data_train)
.loc用法见上面链接。
(3)补全Embarked信息
# (3)补全embarked 使用众数补全(.dropna()删除缺失值,.mode()取众数 values取值)
data_train.Embarked[data_train.Embarked.isnull()] = data_train.Embarked.dropna().mode().values
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
data_train.Embarked.dropna() 为将Embarked缺失值删除,
data_train.Embarked.dropna() .mode() 为在删除缺失值的基础上,取众数,输出如下,众数为S (S港口),0是行标号,如果有多个众数 ,假设S和Q为众数,就会输出 0 S 1 Q
0 S
dtype: object
.values 取值,为列表
print (data_train.Embarked.dropna().mode().values)
>>>['S']
最后,将众数赋值到embarked特征所有为 isnull() 的地方,并进行二值化处理。
1、dropna()自动删除缺失值,[ dropna()用法详解 ]
3.2 提取名字中信息
在baseline的时候,是舍弃了名字属性,这是由于当时认为名字是唯一的,与生存率survived关系不大,但是仔细观察数据集我们会发现,名字中带有Mr,Mrs,Ms,Capt等,这明显和 当事人的 性别、年龄、职业有很大关联,因此不能忽略,需要利用name特征。
我们将这些称呼归类为Officer,Royalty,Mrs,Miss,Mr,Master几大类
data_train['Title'] = data_train['Name'].map(lambda x: re.compile(", (.*?)\.").findall(x)[0])
title_Dict = {}
title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
data_train['Title'] = data_train['Title'].map(title_Dict)
dummies_title = pd.get_dummies(data_train['Title'], prefix="Title")
data_train = pd.concat([data_train,dummies_title], axis=1)
处理完后,同样,进行二值化处理。
1、map函数用法。[ python map函数用法 ]
2、data_train[‘Title’] 返回的是每个人的称呼,例如Mr,Mrs,Ms,Capt等
3、update 是python字典添加内容的方式。
4、dict.fromkeys(seq,10) 可以将序列seq里面每一个值作为key,10分别作为value。具体用法见:[ dict.fromkeys()函数用法 ]
最后事实表明,对名字特征进行如上处理 与 不处理,精确度会有0.1 - 0.3 的提升。
3.3 对部分特征进行二值化处理
# 3.3 对部分特征进行二值化处理
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
# 联合二值化处理后的特征
df = pd.concat([data_train, dummies_Cabin, dummies_Sex, dummies_Pclass,dummies_Embarked], axis=1)
# 删除不用的特征
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked','Title'], axis=1, inplace=True) # 删除指定列
df.head()
这里使用get_dummies方法进行二值化处理,并使用pandas的concat方法将其连接到数据集,DataFrame的.drop方法可以删除掉我们不需要的列。
get_dummies方法与factorize方法都可以二值化,但是方式有区别。它们两者的效果差异我不太清楚,感觉上差不多。
3.4 Age特征分段 并二值化
# 3.4 Age特征分段 并二值化
#df['Age'].values.reshape(-1,1)
bins = [0, 12, 18, 65, 100]
df['Age_group'] = pd.cut(df['Age'], bins)
#by_age = df.groupby('Age_group')['Survived'].mean()
dummies_Age = pd.get_dummies(df['Age_group'], prefix= 'Age')
df = pd.concat([df, dummies_Age], axis=1)
df.drop(['Age','Age_group'], axis=1, inplace=True)
df.head()
Age在baseline的时候,其实只做了一个scaling操作,将其映射到[ -1 , 1 ]的区间中,如下:
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
#映射年龄到-1,1
age_scale_param = scaler.fit(df['Age'].values.reshape(-1,1))
df['Age_scaled'] = scaler.fit_transform(df['Age'].values.reshape(-1,1), age_scale_param) #df['Age_scaled'] 为将年龄映射到 -1,1之间后的年龄列
但后来发现age与生存率并不是成线性关系的,而是低年龄与高年龄生存率较高,因此最终没有采用scaling。
这里简单解释下scaling的用意:
仔细看看Age和Fare两个属性,乘客的数值幅度变化非常大。如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间scale差距太大,将对收敛速度造成极大影响,甚至不收敛!
因此我们先用scikit-learn里面的preprocessing模块对这两个特征做一个scaling,
.
Scaling可以将一个很大范围的数值映射到一个很小的范围(通常是[-1 , 1],或则是[0, 1], **【很多情况下我们需要将数值做Scaling使其范围大小一样,否则大范围数值特征将会获得更高的权重,而不是因为其真的重要而获得更高权限。】**比如:Age的范围可能只是0-100,而income的范围可能是0-10000000,在某些对数组大小敏感的模型中会影响其结果。
因此这里说下将年龄特征分组处理,使用cut将年龄分层几组,然后每组作为一个特征值进行get_dummies操作,具体用法和示例,可以参加
[ Pandas库qcut( )与cut( )的用法与区别 ]
3.5 fare特征分段 并二值化
# 3.5 fare特征分段 并二值化
df['Fare_bin'] = pd.qcut(df['Fare'], 5)
#print (df[['Fare_bin', 'Survived']].groupby(['Fare_bin'], as_index=False).mean().sort_values(by='Fare_bin', ascending=True))
dummies_Fare_bin = pd.get_dummies(df['Fare_bin'], prefix= 'Fare_bin')
df = pd.concat([df, dummies_Fare_bin], axis=1)
df.drop(['Fare','Fare_bin'], axis=1, inplace=True)
df.head()
fare特征在baseline也只是scaling了一下,映射到[ -1 , 1 ]的区间,并且fare特征分组与不分组,就我试验的来说,结果并无明显变化
3.6 对 SibSp Parch合并为family_size
# #3.6 对 SibSp Parch合并为family_size
df['Family_Size'] = df['Parch'] + df['SibSp'] + 1
#df[['Family_Size','Survived']].groupby(['Family_Size']).mean().plot.bar()
df.drop(['SibSp','Parch'], axis=1, inplace=True)
df.head()
将两个特征合并为一个特征,感觉结果在合并后并无明显变化
至此,所有特征已经处理完毕,下面进行交叉验证
4、划分训练集、验证集
# 分割数据,按照 训练数据:cv数据 = 0.75:0.25的比例
from sklearn import cross_validation
from sklearn import linear_model
from sklearn.ensemble import BaggingRegressor
# 划分
split_train, split_cv = cross_validation.train_test_split(df, test_size=0.25, random_state=0)
# 训练集
train_df = split_train.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*') #过滤规则
print (train_df.shape) # 大小
print (train_df.columns.tolist()) # 列名
train_df.head() #PassengerId age fare embarked 都没有了 说明上述过滤规则没问题,并且第一列是标签列
# 生成模型
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
#用生成的模型 对 验证集 数据进行预测
cv_df = split_cv.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')
predictions = bagging_clf.predict(cv_df.as_matrix()[:,1:]) # 返回的是验证集的预测标签
# 计算正确率
from sklearn.metrics import accuracy_score
accuracy_score(cv_df.as_matrix()[:,0],predictions.astype(np.int32))
首先使用cross_validation.train_test_spli() 函数将其划分为训练集 和验证集
然后使用split_train.filter(regex=’ ')设置过滤规则,即要保留的列,当然,如果数据集已经按要求整理好的话,可以不必再用此过滤规则
开始训练模型,baseline方案只是用了linear_model.LogisticRegression 逻辑回归方式,
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(train_df.as_matrix()[:,1:], train_df.as_matrix()[:,0])
但使用
模型融合
后,即bagging,明显取得了更好的效果,因此,最终采用bagging的方式,其基学习器为逻辑回归。代码见上面。
而后,使用训练好的模型对验证集进行预测,predict() 返回的是预测标签。
关于predict 和 predict_probe() 区别,请见
[ sklearn中predict与predict_proba区别 ]
最后,评价方法,
即计算验证集上的正确率:
# 计算正确率
from sklearn.metrics import accuracy_score
accuracy_score(cv_df.as_matrix()[:,0],predictions.astype(np.int32))
输出:
0.78
accuracy_score 输出所有分类正确的百分比。关于评价方法,见
[机器学习模型的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)]
accuracy_score会输出一个正确率的百分比,例如 0.78。
关于为什么要predictions 后面 加上.astype(np.int32),这是因为如果你直接输出predictions来看的话,你会发现结果并不只是 0 或 1 ,还会有0.6 0.2 0.8等等数值的出现,此种情况下直接和 验证集标签(只有0 和 1 两种类型)进行比较正确率,那结果 肯定很低,因此, .astype(np.int32)强制将其转换为int型,即大于等于0.4 取1,小于0.4 取 0。 关于astype用法,具体参见
[ Numpy数据类型转换astype,dtype ]
其实在baseline的时候,这时候可以通过观察badcase,来对我们的特征进行调整,比如我就是通过观察bad case,看看错分的数据都有什么特点,而后发现,错分 和 年龄这个特征有关,进而将年龄特征从scaling 改成了 分组的方式。
下面简单介绍下查看bad case的代码
origin_data_train = pd.read_csv("all/Train.csv")
bad_cases = origin_data_train.loc[origin_data_train['PassengerId'].isin(split_cv[predictions != cv_df.as_matrix()[:,0]]['PassengerId'].values)]
bad_cases
#输出的是 badcase 的例子
bad_cases那条长语句解析如下:
#具体的意义,如下,不用太纠结,看不懂也无所谓。
a = split_cv[predictions != cv_df.as_matrix()[:,0]] ['PassengerId'].values # a = 验证集上 与 predictions 上不相等的 PassengerId的值
bad = origin_data_train.loc[origin_data_train['PassengerId'].isin[a] # b = 数据集上的 PassengerId 在a中有的
在本节,我们直接将数据集划分为 70%的训练集 和30%的 验证集,然后进行测试,看看效果,其实还有一种方式,就是
K-折交叉验证
在下一节会介绍K-折交叉验证
5 正式训练数据
from sklearn.ensemble import BaggingRegressor
from sklearn import linear_model
# 用正则取出我们要的属性值,其实就是过滤掉了PassengerID列 但是这里好像把age 和fare embark也过滤掉了 什么鬼 #对的,因为age 和fare用 Age_scale和fare_scale特征代替了
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')
train_np = train_df.as_matrix() #如果这里不转成矩阵那么就不能用[:,0]这种表述,而必须用 train_df['具体列名或者列名组成的列表,旧金山犯罪那个比赛就是用的列名组成的列表']
# y即Survival结果
y = train_np[:, 0] # 整个数据集
# X即特征属性值
X = train_np[:, 1:]
print ('训练集规模:',X.shape)
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
bagging_clf = BaggingRegressor(clf, n_estimators=20, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y) # 训练完毕
这块代码比较清晰,大致就是使用BaggingRegressor,基学习器为LogisticRegression
最后训练完成,保存在 bagging_clf 对象中。
注意
train_np = train_df.as_matrix()
如果这里不转成矩阵那么就不能用[:,0]这种表述,而必须用 train_df[‘具体列名或者列名组成的列表,旧金山犯罪那个比赛就是用的列名组成的列表’]
###K-折交叉验证
关于k-折交叉验证,在X,y确定了后,可以进行k折交叉验证,其使用 cross_val_score () 函数进行
from sklearn import cross_validation
#简单看看打分情况
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
print (cross_validation.cross_val_score(clf, X, y, cv=5))
# 输出
>>> [0.80446927 0.79888268 0.78651685 0.78089888 0.8079096 ]
clf为训练器,cv为k值,X为前面的训练集,y为标签;
cross_val_score 输出k个值。关于K-折交叉验证原理,大家可以百度搜搜。
这里有个小问题,目前还没弄明白,就是使用bagging等集成学习方法时,k折交叉验证的结果正确率很低,普遍在0.2 0.3 左右。我觉得可能原因之一就是集成学习中 基学习器的训练数据太少了,但是应该还有别的原因。
注意:逻辑回归对象 clf 并没有进行训练(.fit)操作,而是直接放入cross_val_score()函数中,说明此函数带有训练功能。
6 处理测试集
# 6 处理测试集 (对测试集做与前面一样的处理)
data_test = pd.read_csv('all/test.csv')
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
#处理embarked
#补缺失
data_test.Embarked[data_test.Embarked.isnull()] = data_test.Embarked.dropna().mode().values
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
# 提取名字中信息
data_test['Title'] = data_test['Name'].map(lambda x: re.compile(", (.*?)\.").findall(x)[0])
title_Dict = {}
title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
data_test['Title'] = data_test['Title'].map(title_Dict)
dummies_title = pd.get_dummies(data_test['Title'], prefix="Title")
data_test = pd.concat([data_test,dummies_title], axis=1)
#二值化
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
#dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Sex, dummies_Pclass, dummies_Embarked], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked','Title'], axis=1, inplace=True)
# 年龄分段处理
bins_test = [0, 12, 18, 65, 100]
df_test['Age_group'] = pd.cut(df_test['Age'], bins_test)
dummies_Age = pd.get_dummies(df_test['Age_group'], prefix= 'Age')
df_test = pd.concat([df_test, dummies_Age], axis=1)
df_test.drop(['Age','Age_group'], axis=1, inplace=True)
# fare特征分段 并二值化
df_test['Fare_bin'] = pd.qcut(df_test['Fare'], 5)
#print (df[['Fare_bin', 'Survived']].groupby(['Fare_bin'], as_index=False).mean().sort_values(by='Fare_bin', ascending=True))
dummies_Fare_bin = pd.get_dummies(df_test['Fare_bin'], prefix= 'Fare_bin')
df_test = pd.concat([df_test, dummies_Fare_bin], axis=1)
df_test.drop(['Fare','Fare_bin'], axis=1, inplace=True)
#df.head()
# 对 SibSp Parch合并为family_size
df_test['Family_Size'] = df_test['Parch'] + df_test['SibSp'] + 1
df_test.drop(['SibSp','Parch'], axis=1, inplace=True)
df_test.head()
# 过滤规则
test = df_test.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Sex_.*|Pclass_.*|Title_.*|Family_Size|Embarked_.*')# 过滤掉PassengerId 、 age 和 fare embark
print ('测试集规模: ',test.shape)
test.head()
这里没有什么好说的,对测试集的操作 与 对 训练集的操作完全一样,包括操作顺序,即保障测试集和训练集列的顺序也是一样的。
这里有什么问题,大家可以留言询问。
7 生成预测结果
# 7 生成预测结果
predictions = bagging_clf.predict(test)# 获得预测的标签
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)
print ("End")
最后,完事具备,用 bagging_clf 的 predict进行预测,结果保存在 predictions 变量中,result 为DataFrame数据格式,这里同样注意,predictions要.astype(np.int32)处理,否则会和前面所讲一样,出现问题。
保存为logistic_regression_predictions.csv 文件后,变可提交到kaggle上查看自己的评分和排名啦,
最后,祝大家比赛顺利,获得高分高名次。
8 关于kaggle参赛思路
8.1初步思路
要先看看训练集和测试集, 以及最后需要提交的结果
评价函数是什么 是log loss 还是像本例子中,用accuracy_score 评价一下就行。
8.2进一步思路
1、先做一个baseline 在通过步骤2观察数据后,我们可以先选出一些特征,使用基本的决策树、LR等,训练一个模型,用交叉验证,或者测试集去处理,先形成一个baseline,然后再详细考虑优化提升的问题,包括优化特征,优化算法等方面
可以概括为以下内容
- 先看训练集 测试集的属性,确定标签
- 概览一下数据
- 通过画图分析属性和分类标签之间的关联度,选择属性
- 补全数据(随机森林),这个方法挺好使,这个代码可以以后可以借鉴下
- 因子化 dummies 或者 factorize
- scaling (特征化到[-1,1]或[0,1]之内)、或分段处理 (视情况而定)
- 交叉验证
以上,完成一个baseline,而后进行优化。
分析分析模型现在的状态了,是过/欠拟合?,以确定我们需要更多的特征还是更多数据,或者其他操作
查看交叉验证的bad case,
以及 通过画学习曲线分析learning curves
重新对特征进行处理,组合成新特征,舍弃一些特征
模型融合(集成学习)。
9 补充
9.1 学习曲线分析learning curves
学习曲线简单来说,就是判断模型状态:过拟合欠拟合
学习曲线可以再交叉验证步骤之后画
输出:
我们的model并不处于overfitting的状态,overfitting的表现一般是训练集上得分高,而交叉验证集上要低很多,中间的gap比较大。因此我们可以再做些feature engineering的工作,添加一些新产出的特征或者组合特征到模型中。
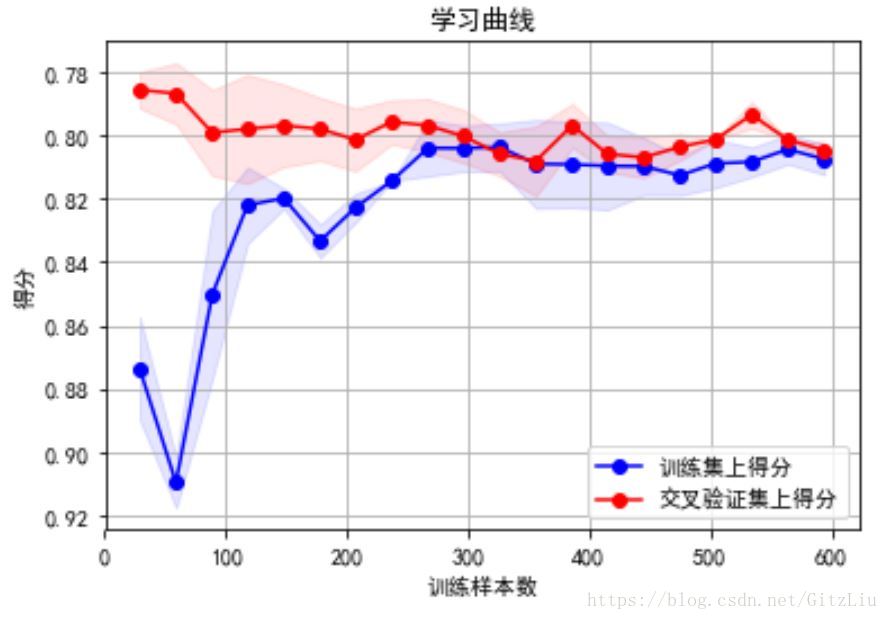
关于学习曲线的解释 和 画法,具体内容可以参见我的这篇博文:
[ 学习曲线-Learning Curve ]
9.2 模型融合
(1)voting
如果有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。 可以理解为是baggin形式的一种。
(2)bagging(需要补充内容)
Bagging 将多个模型,也就是多个基学习器的预测结果进行简单的加权平均或者投票(这块有三种,需要看笔记补充)。它的好处是可以并行地训练基学习器。Random Forest就用到了Bagging的思想。
(3)boosting(看以前比较补充)
Boosting 的思想有点像知错能改,每个基学习器是在上一个基学习器学习的基础上,对上一个基学习器的错误进行弥补。我们将会用到的 AdaBoost,Gradient Boost 就用到了这种思想。
(4)Stackiing(补充链接)
这个方法真是感觉太好了,初次听说的时候小小震惊了一下,城会玩。
我在本篇博客最前面给出的代码版本上,有尝试了下stacking方法,效果至少提高0.03,这说明stacking方法还是非常有效的。 stacking代码在如下链接中也有
记录一下:
[ 模型融合-Stacking ]
9.3 机器学习知识点补充
(1)过拟合(正则化处理) - 欠拟合
参加我的这篇博客 [ 过拟合(正则化处理)- 欠拟合 处理方法 ]
(2)关于缺失值处理方法:
1、如果数据集很多,但有很少的缺失值,可以删掉带缺失值的行;
2、如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
3、对于标称属性,可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。比如船舱号Cabin这一属性,缺失可能代表并没有船舱
附录
baseline版本
加入XX特征版本
加入XX特征版本
…
未完待续














 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









