








收集器简介
1.收集器介绍
Java 8中流支持两种类型的操作:中间操作(如filter或map)和终端操作(如count、findFirst、forEach和reduce)。
中间操作可以链接起来,将一个流转换为另一个流。这些操作不会消耗流,其目的是建立一个流水线。与此相反,终端操作会消耗流,以产生一个最终结果,例如返回流中的最大元素。
2.概念辨析
collect:Stream接口中定义的方法用来整合收集流操作的最终结果,其中的一个接口定义为。
<R, A> R collect(Collector<? super T, A, R> collector);Collector:Collector是专门用来作为Stream的collect方法的参数的,Collector主要包含五个参数,它的行为也是由这五个参数来定义的。
public interface Collector<T, A, R> {// supplier参数用于生成结果容器,容器类型为ASupplier<A> supplier();// accumulator用于消费元素,也就是归纳元素,这里的T就是元素,它会将流中的元素一个一个与结果容器A发生操作BiConsumer<A, T> accumulator();// combiner用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果ABinaryOperator<A> combiner();// finisher用于将之前整合完的结果R转换成为AFunction<A, R> finisher();// characteristics表示当前Collector的特征值,这是个不可变SetSet<Characteristics> characteristics();}Collectors:Collectors是一个工具类,是JDK预实现Collector的工具类,它内部提供了多种Collector,我们可以直接拿来使用。
Collection:Collection接口是 (java.util.Collection)是Java集合类的顶级接口之一,整个集合框架就围绕一组标准接口而设计。

使用Collector进行collect收集
Collector接口中的方法介绍
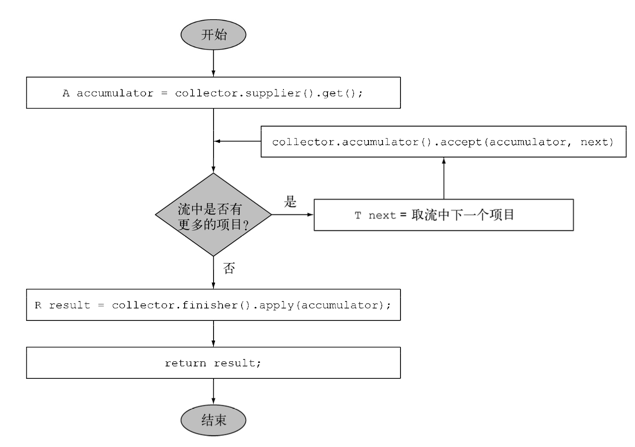
1. 建立新的结果容器:supplier方法
supplier方法必须返回一个结果为空的Supplier,也就是一个无参数函数,在调用时它会创建一个空的累加器实例,供数据收集过程使用。
2. 将元素添加到结果容器:accumulator方法
accumulator方法会返回执行操作的函数。当遍历到流中第n个元素时,这个函数执行时会有两个参数保存归约结果的累加器(已收集了流中的前n-1个项目),还有第n个元素本身。
3.对结果容器应用最终转换finisher
在遍历完流后,finisher方法必须返回在累积过程的,最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。
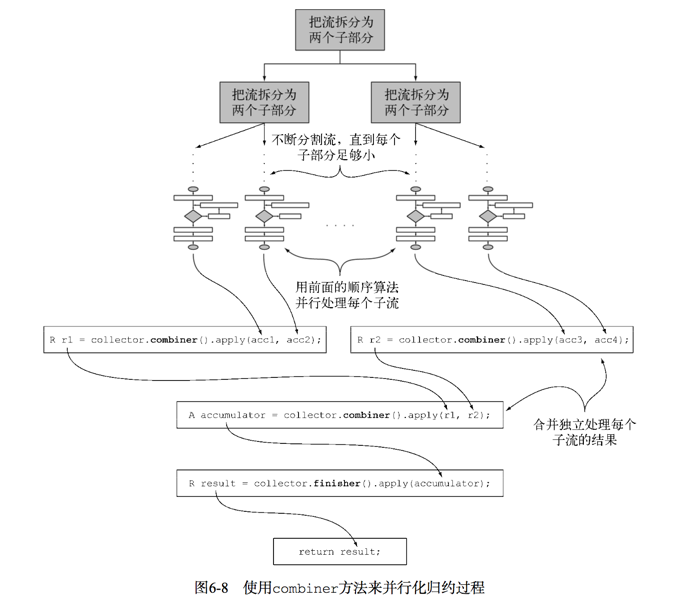
4.合并两个结果容器:combiner方法
四个方法中的最后一个——combiner方法会返回一个供归约操作使用的函数,它定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器要如何合并。
5.characteristics方法
-
Characteristics是一个包含三个项目的枚举。
-
UNORDERED—— 结果不受流中项目的遍历和累积顺序的影响。
-
CONCURRENT—— accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约。
-
IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查地转换为结果R是安全的。
示例
1.顺序归约过程的逻辑步骤
1. 建立新的结果容器:supplier方法
2. 将元素添加到结果容器:accumulator方法
3. 对结果容器应用最终转换:finisher
2.使用combiner来并行化归约过程

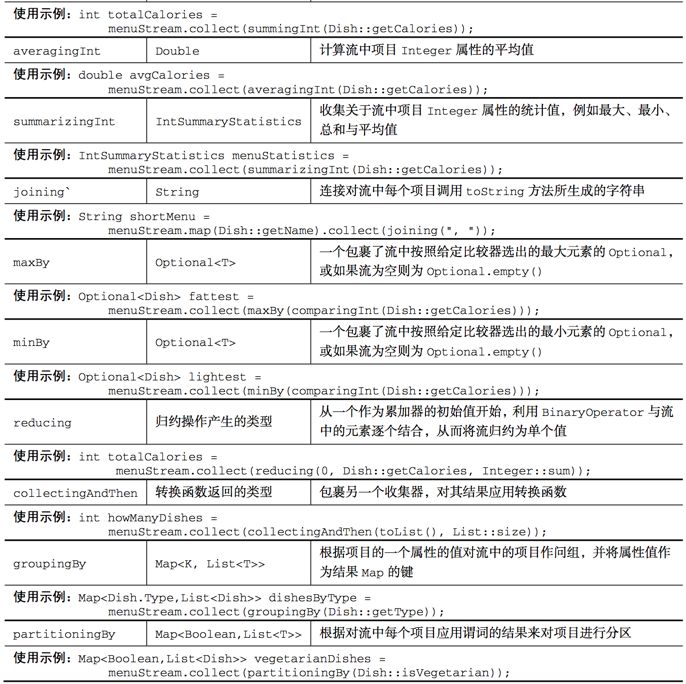
Collectors类


小结
-
collect是一个终端操作,它接受的参数是将流中元素累积到汇总结果的,各种方式(称为收集器)。
-
预定义收集器包括将流元素归约和汇总到一个值,例如计算最小值、最大值或平均值。
-
预定义收集器可以用groupingBy对流中元素进行分组,或用partitioningBy进行分区。
-
你可以实现Collector接口中定义的方法来开发你自己的收集器。
作者:翎野君
博客:https://www.cnblogs.com/lingyejun/
本篇文章如有帮助到您,请给「翎野君」点个赞,感谢您的支持。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









