






目录
梯度下降法的优化
调整神经网络结构,增加池化层,或者dropout
算法优化,如随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam
随机梯度下降法(min-bitch)
本质:减少每一次计算的计算量,
在原来的计算中是把整个训练集都计算一遍,在随机梯度下降法中,随机挑选一个数据,用这个数据计算,最后修改参数值,在下一次训练中,再随机挑一个数据再次训练,通过如此不断将参数收敛到极值点。
在凸问题这样的问题下,k代表迭代了k次,f星代表的是那个极值点,经过k次训练后,最后随机梯度下降法能达到的那个误差是根号k分之一这个量级的。
在强凸问题下,它的收敛还会更快,达到k分之一这个量级。
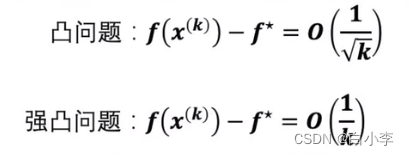
在正常情况下,标准的梯度下降法的收敛速度是要比随机梯度下降法快,但经过科学家证明,再快也不会块多k分之一。即总得来看,梯度下降法的效率和性价比不是很高,即直接选择用随机梯度下降法。
优化下降的路径(牛顿法)
本质:用更少的步数,更快地到达极值点。

学习步长由学习率决定,如果步长太长了,下一个更新到的节点就是箭头指向的位置,但此时B点的最快下降方向不是箭头的这个方向了,即这个下降路径不是最优的。若减少学习的步长,虽然可以贴近完美下降路径,但增加了学习的步数,增大了计算量。
保证一定的学习步长,又可以贴近最优下降路径。
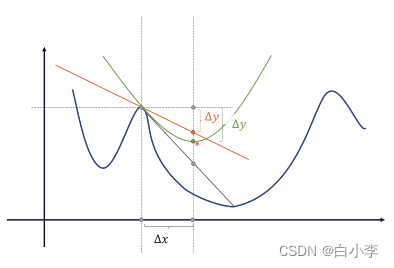
上图中灰色的曲线是到极值点最优的路线,橙色直线离极值点是有偏差的,距离越远,偏差越大。绿色抛物线在一定范围内是优于这条直线的,当这个抛物线取值到顶点时效果是最好的,当按照抛物线来进行学习的话,它的步长达到x时,它的学习效果是最好的。
数学表达:

缺陷:计算量大,实际中难以运用。
动量法(冲量法)

绿色路径上下震动减少了,横向跨度增加了。利用历史数据去修正分量,比如在第一个箭头点,计算出的梯度在纵轴的分量同历史的数据相比较,历史上纵轴的分量是向下的,跟它相反,则它会减少这个维度上的量,若方向相同,则加大步长。
将历史的数据添加进来。


缺陷:步数够多的话,前所有的历史数据都要全部考虑,其中包括一些没参考价值的数据。
Nesterov方法
超前参考未来的数据。

AdaGrad方法
让学习率实现自适应,其中是通过历史数据。

在学习率η下除了一个数值,这个数值是历史上所有梯度的内积开方。历史数据修改的多,则η学习率减少的也就越多。
学习到的梯度是真实梯度除以梯度内积的开方。adagrad本质是解决各方向导数数值量级的不一致而将梯度数值归一化
适合稀疏数据(训练集中的两个数据,它们之间的不同更多的是体现在特征的不同,而不是体现在某一个具体特征上的程度不一样)。















 9720
9720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









