






PCA(主成分分析)、PLS(偏最小二乘法)和变分自编码器(VAE)都是用于降维的技术,但它们来自不同的背景领域,目的和方法也各不相同。
1. 主成分分析(PCA)
- 目的:PCA 通过识别主要成分(数据最大方差的方向)来降低数据维度。
- 方法:这是一种线性方法,找到能捕获数据中最大方差的正交方向(主成分)。这些方向形成了一个新的基底,可以在这个低维空间中表示数据。
- 应用:PCA 通常用于数据探索分析、降噪和特征工程,适用于线性可分的数据。
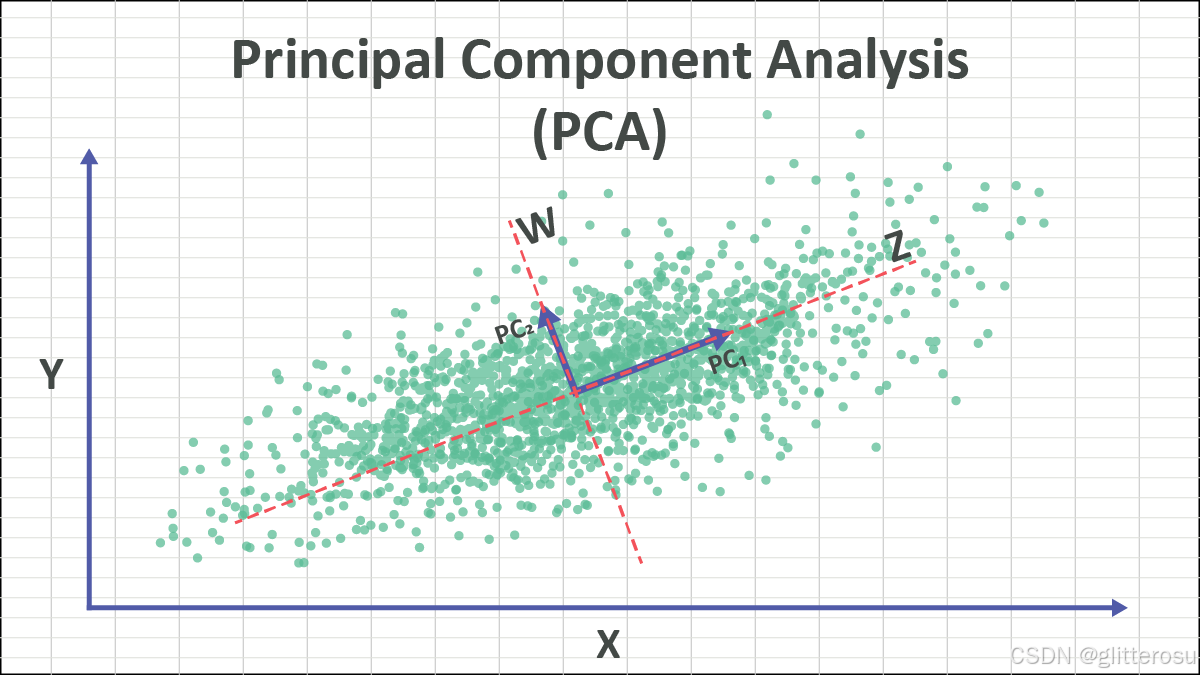
如下图,绿色为我们的数据集,PCA 会自动找到数据变化最大的方向,这个方向称为第一主成分(PC1),在图中用蓝色箭头表示。沿着 PC1 方向投影数据,就可以保留最多的信息。
第二个方向(第二主成分 PC2)是垂直于第一主成分的方向,表示在主方向之外的其他变化。PC2虽然也能捕捉一些信息,但相比于PC1,它包含的数据变化量较少。
2. 偏最小二乘法(PLS)
- 目的:PLS 也用于降维,但专注于最大化输入特征与目标变量之间的相关性(通常用于监督学习)。
- 方法:PLS 通过考虑预测变量和响应变量,将输入数据投影到低维空间,重点在于找到与响应变量协方差最高的成分。
- 应用:PLS 适用于高维数据场景,能够创建对目标变量有预测力的特征,常用于化学计量学、生物信息学等含有噪声的数据分析中。
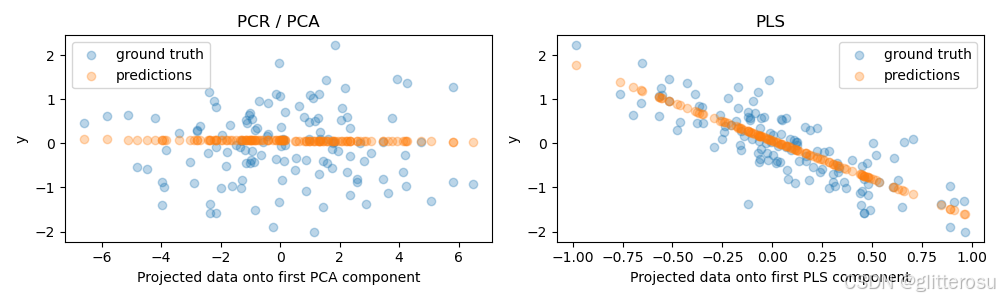
如下图,- 左图(PCA):由于主成分分析 (PCA) 是一种完全无监督的降维方法,它仅基于数据的方差来选择主要方向。结果是,PCA 舍弃了第二主成分(方差较小的方向),尽管该方向对目标预测更有帮助。这导致 PCA 转换后的数据在预测目标变量时效果较差。
- 右图(PLS):偏最小二乘法 (PLS) 由于在降维时利用了目标信息,它能够识别出虽然方差较小但对目标预测更重要的方向。因此,PLS 的第一主成分与目标变量呈负相关,这样的转换提高了模型的预测能力。
3. 变分自编码器(VAE)
- 目的:VAE 是一种深度学习模型,通过生成一个压缩的潜在空间来学习数据的内在结构,可以从中大致重建数据。
- 方法:VAE 与上述方法的主要区别在于它是一种基于神经网络和概率建模的生成模型。VAE 引入了随机过程,编码器学习将输入数据映射到潜在空间中的分布(如高斯分布),解码器再从中重建原始输入。
- 应用:VAE 广泛用于无监督学习任务,例如数据生成、图像和文本生成,以及异常检测。
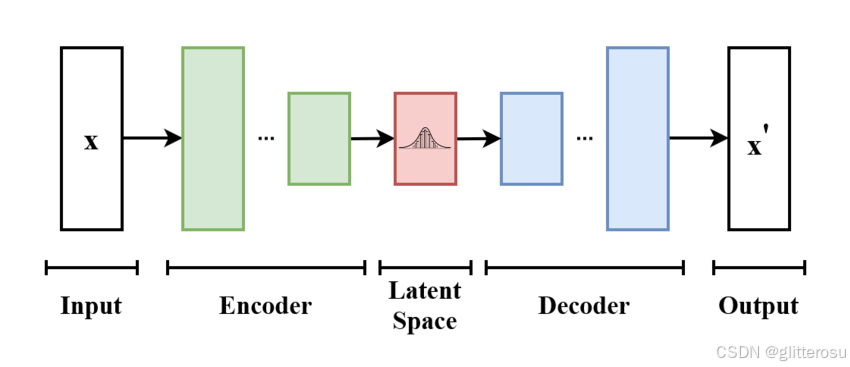
下图为变分自编码器(Variational Autoencoder, VAE)的基本结构示意图。模型接收输 x,编码器将其压缩到潜在空间(latent space)。解码器从潜在空间中取样信息,生成尽可能接近输入 x 的输出 x’。
主要关系与区别
-
降维:这三种方法都执行降维,但 PCA 和 PLS 是线性变换,而 VAE 能够建模复杂的非线性关系。
-
潜在空间表示:
- PCA:找到最大方差方向,不依赖监督信息。
- PLS:找到对目标变量有预测力的方向,使用监督学习。
- VAE:学习一个连续、概率化的潜在空间,可以捕捉复杂的结构,常用于高维数据。
-
数据生成:只有 VAE 本质上是生成模型,可以从潜在空间中采样以生成新的数据点,而 PCA 和 PLS 侧重于转换而非生成。
-
应用场景:
- PCA 适用于通用的无监督降维。
- PLS 适合有特定预测目标的监督场景。
- VAE 适用于无监督学习和生成建模。
虽然这三种方法都能降维,但 PCA 和 PLS 更可解释且相对简单,主要关注方差和相关性,而 VAE 则是非线性的,适合生成和学习复杂数据表示。
参考:
https://scikit-learn.org/dev/auto_examples/cross_decomposition/plot_pcr_vs_pls.html#sphx-glr-auto-examples-cross-decomposition-plot-pcr-vs-pls-py
https://scikit-learn.org/1.5/auto_examples/cross_decomposition/plot_pcr_vs_pls.html
https://en.wikipedia.org/wiki/Variational_autoencoder

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









