






一、朴素贝叶斯算法简介
朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,常用于文本分类、垃圾邮件过滤、情感分析等任务。它的核心思想是通过已知数据集中的特征与类别的联合概率来估计新样本的类别。具体来说,朴素贝叶斯算法假设各个特征之间相互独立,即一个特征对于给定类别的概率没有影响。虽然这个假设在实际情况中可能不成立,但朴素贝叶斯算法在许多情况下表现良好,尤其是在特征之间相关性较弱或者样本量较大时。
朴素贝叶斯算法的步骤通常包括:
- 准备数据集:收集并准备带有标签的训练数据。
- 特征提取:从数据集中提取特征,并将其表示为特征向量。
- 训练模型:利用训练数据集,估计各个特征对于每个类别的条件概率分布。
- 预测:对于新的未知样本,利用贝叶斯定理计算其属于各个类别的概率,选择具有最高概率的类别作为预测结果。
朴素贝叶斯算法有几个常见的变种,包括:
- 多项式朴素贝叶斯:用于处理离散特征的朴素贝叶斯变种。
- 高斯朴素贝叶斯:用于处理连续特征的朴素贝叶斯变种,假设特征的分布满足高斯分布。
- 伯努利朴素贝叶斯:用于处理二元特征的朴素贝叶斯变种,即特征只能取两个值。
朴素贝叶斯算法的优点包括简单易实现、对小规模数据表现良好、对于高维数据效果好等。然而,它也有一些缺点,例如对于特征之间相关性较强的数据表现不佳。
二、实例
假设我们有以下的训练数据集,其中包含了三个特征(色泽、根蒂、敲声)和对应的分类(好瓜、坏瓜):
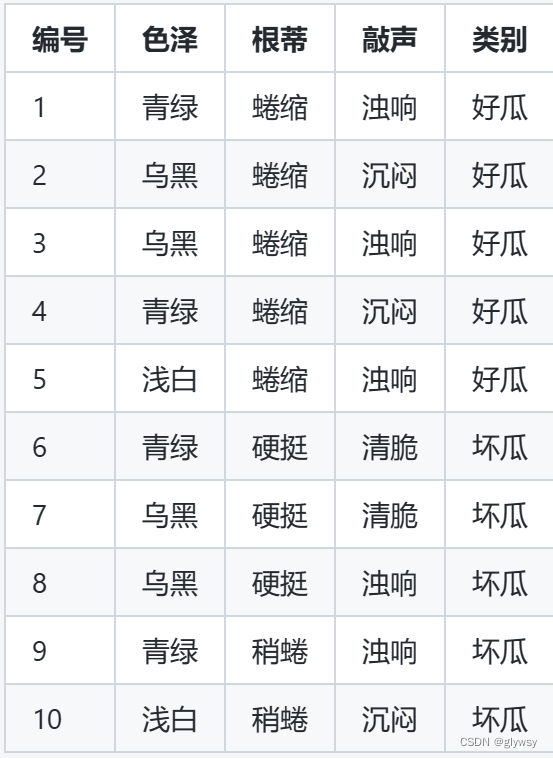
现在,我们要根据这个训练数据集构建一个朴素贝叶斯分类器,并使用该分类器对一个新的实例进行分类。假设我们有一个新的实例,特征为:色泽=青绿,根蒂=稍蜷,敲声=浊响,我们要计算这个实例属于好瓜和坏瓜的概率。
根据朴素贝叶斯算法的计算过程,我们需要计算出给定特征条件下各个类别的概率,并选择具有最大概率的类别作为预测结果。
下面是计算过程的结果:
- 好瓜的先验概率 P(好瓜) = 5/10 = 0.5
- 坏瓜的先验概率 P(坏瓜) = 5/10 = 0.5
对于特征条件下各个类别的概率,我们可以从训练数据中计算得出:
-
P(色泽=青绿|好瓜) = 3/5 = 0.6
-
P(根蒂=稍蜷|好瓜) = 1/5 = 0.2
-
P(敲声=浊响|好瓜) = 4/5 = 0.8
-
P(色泽=青绿|坏瓜) = 3/5 = 0.6
-
P(根蒂=稍蜷|坏瓜) = 2/5 = 0.4
-
P(敲声=浊响|坏瓜) = 3/5 = 0.6
现在,我们可以根据贝叶斯公式计算给定特征条件下各个类别的后验概率:
- P(好瓜|特征) ∝ P(好瓜) * P(色泽=青绿|好瓜) * P(根蒂=稍蜷|好瓜) * P(敲声=浊响|好瓜) = 0.5 * 0.6 * 0.2 * 0.8 = 0.048
- P(坏瓜|特征) ∝ P(坏瓜) * P(色泽=青绿|坏瓜) * P(根蒂=稍蜷|坏瓜) * P(敲声=浊响|坏瓜) = 0.5 * 0.6 * 0.4 * 0.6 = 0.072
根据贝叶斯公式,我们可以看到后验概率是不需要归一化的,因为归一化后两个概率的比值不会改变。
所以,根据计算结果,我们得出结论:给定特征条件下,该实例更可能属于坏瓜类别。
以下是一个简单的Python代码实现:
import pandas as pd
from sklearn.naive_bayes import GaussianNB
# 加载训练数据
data = {
'编号': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '青绿', '浅白'],
'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '硬挺', '硬挺', '硬挺', '稍蜷', '稍蜷'],
'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '清脆', '清脆', '浊响', '浊响', '沉闷'],
'类别': ['好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜']
}
df = pd.DataFrame(data)
# 将分类特征转换为数字
color_mapping = {'青绿': 0, '乌黑': 1, '浅白': 2}
root_mapping = {'蜷缩': 0, '硬挺': 1, '稍蜷': 2}
sound_mapping = {'浊响': 0, '沉闷': 1, '清脆': 2}
class_mapping = {'好瓜': 0, '坏瓜': 1}
df['色泽'] = df['色泽'].map(color_mapping)
df['根蒂'] = df['根蒂'].map(root_mapping)
df['敲声'] = df['敲声'].map(sound_mapping)
df['类别'] = df['类别'].map(class_mapping)
# 构建朴素贝叶斯分类器
X = df.drop(['编号', '类别'], axis=1)
y = df['类别']
classifier = GaussianNB()
classifier.fit(X, y)
# 新实例特征
new_instance = pd.DataFrame({'色泽': ['青绿'], '根蒂': ['稍蜷'], '敲声': ['浊响']})
new_instance['色泽'] = new_instance['色泽'].map(color_mapping)
new_instance['根蒂'] = new_instance['根蒂'].map(root_mapping)
new_instance['敲声'] = new_instance['敲声'].map(sound_mapping)
# 预测新实例
predicted_prob = classifier.predict_proba(new_instance)
# 结果
print("好瓜的概率:", predicted_prob[0][0])
print("坏瓜的概率:", predicted_prob[0][1])
三、总结
朴素贝叶斯是一种基于贝叶斯定理的分类算法,其核心思想是通过特征之间的条件独立性假设来简化计算,从而实现高效的分类。
以下是对朴素贝叶斯算法的总结:
-
基于概率模型: 朴素贝叶斯是基于概率的分类模型,通过计算样本属于每个类别的概率来进行分类。
-
条件独立性假设: 朴素贝叶斯假设给定类别的情况下,特征之间是相互独立的。尽管这个假设在实际数据中往往并不成立,但朴素贝叶斯仍然是一种有效的分类方法,并且在许多实际应用中表现良好。
-
适用性广泛: 朴素贝叶斯适用于多种类型的分类问题,包括文本分类、垃圾邮件过滤、情感分析等。由于其简单性和高效性,朴素贝叶斯在实际应用中得到了广泛的应用。
-
处理连续和离散特征: 朴素贝叶斯可以处理连续型和离散型的特征,并且不需要对数据进行特殊的处理或转换。
-
对小规模数据集效果好: 即使在小规模数据集上,朴素贝叶斯也可以表现出色。由于其简单性和对噪声数据的鲁棒性,朴素贝叶斯在小规模数据集上的表现往往比其他复杂的分类算法更好。
-
处理多分类问题: 朴素贝叶斯可以很容易地扩展到多分类问题,例如使用多项式朴素贝叶斯处理多类别的文本分类问题。
尽管朴素贝叶斯在处理复杂数据集时可能无法达到其他更复杂的分类算法的精度,但它仍然是一个简单而强大的分类工具,特别适用于处理大规模数据集和需要快速训练和预测的场景。















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









