






一、常见的分类模型评估指标
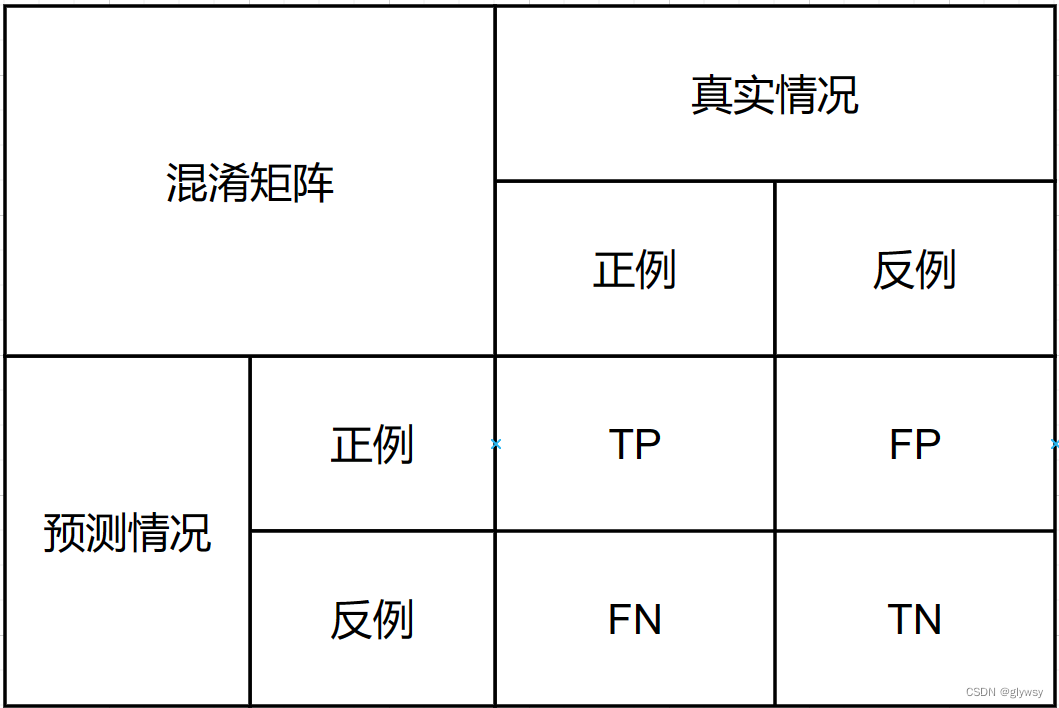
上述矩阵称为混淆矩阵,其中:
True Positive(TP):真正例。模型正确地预测了正类别的样本数量。
False Negative(FN):假负例。模型错误地将正类别的样本预测为负类别的数量。
False Positive(FP):假正例。模型错误地将负类别的样本预测为正类别的数量。
True Negative(TN):真负例。模型正确地预测了负类别的样本数量。
由混淆矩阵可以得到以下分类指标。
1.准确率(Accuracy):分类正确的样本数占总样本数的比例。
准确率 = (TP+TN)/ (TP + TN + FP + FN)
2.精确率(Precision):被分类器正确分类为正例的样本数占分类器判定为正例的样本数的比例。
精确率 = TP / (TP + FP)
3.召回率(Recall):分类器正确分类为正例的样本数占真实正例的样本数的比例。
召回率 = TP / (TP + FN)
4.F1分数(F1 Score):精确率和召回率的调和平均数,综合考虑了分类器的准确率和召回率。
F1分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
5.ROC曲线和AUC(Area Under the ROC Curve):ROC曲线是以假正例率(False Positive Rate)为横轴,真正例率(True Positive Rate)为纵轴的曲线,用于衡量二分类模型在不同阈值下的性能。AUC是ROC曲线下方的面积,用于衡量分类模型的性能,AUC值越接近1,模型性能越好。
二、ROC曲线和PR曲线
ROC曲线(Receiver Operating Characteristic Curve)和PR曲线(Precision-Recall Curve)是评估二分类模型性能的两种常用工具,它们在不同场景下有着不同的优势和用途。
ROC曲线:
- 横轴:假正例率(False Positive Rate,FPR),表示被错误地预测为正例的负例样本占所有负例样本的比例。
- 纵轴:真正例率(True Positive Rate,TPR),也称为召回率(Recall),表示被正确地预测为正例的正例样本占所有真实正例样本的比例。
- 特点:ROC曲线能够展示在不同阈值下模型的性能,可以帮助选择合适的阈值来平衡假正例率和真正例率。
PR曲线:
- 横轴:召回率(Recall),表示被正确地预测为正例的正例样本占所有真实正例样本的比例。
- 纵轴:精确率(Precision),表示被正确地预测为正例的样本中真正例样本的比例。
- 特点:PR曲线能够直接展示在不同阈值下模型的精确率和召回率之间的权衡关系。
差异:
- 适用场景:ROC曲线适用于正负样本类别平衡的情况,而PR曲线更适用于正负样本类别不平衡的情况。
- 重点:ROC曲线关注的是真正例率和假正例率的平衡,适用于关注分类器整体性能的情况;而PR曲线关注的是精确率和召回率的平衡,更适用于关注正例样本的预测准确率的情况。
- 解读方式:ROC曲线越靠近左上角,说明模型性能越好;而PR曲线越靠近右上角,说明模型性能越好。
三、不同k值下的ROC曲线
绘制ROC曲线的代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
# 生成模拟数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练KNN模型,此处k值设置为1
model = KNeighborsClassifier(n_neighbors=1)
model.fit(X_train, y_train)
# 获取测试集上的预测概率
probs = model.predict_proba(X_test)[:, 1]
# 计算ROC曲线
fpr, tpr, _ = roc_curve(y_test, probs)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='black', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()
以下分别是k=1 、3、5、7、9时的ROC曲线
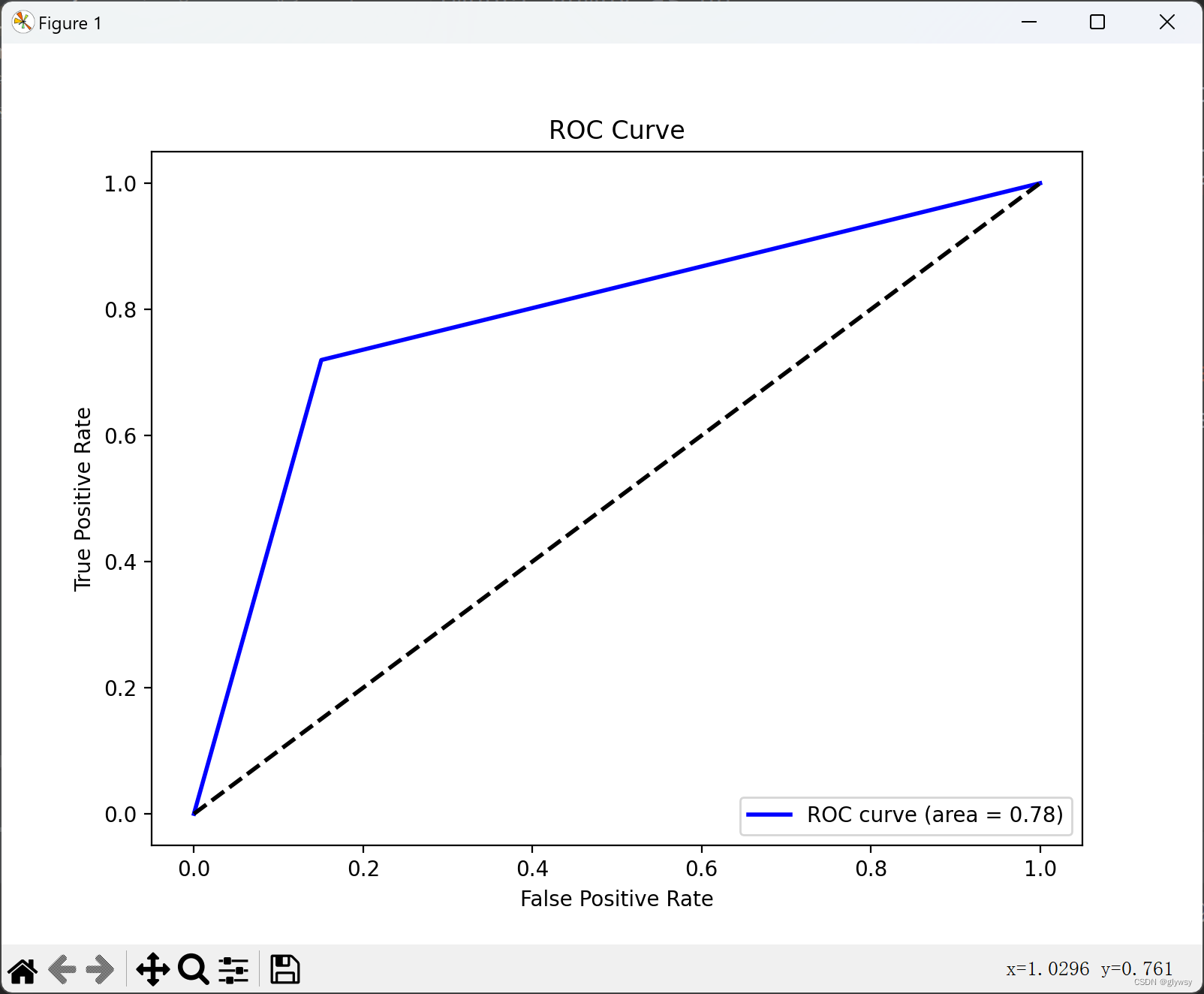
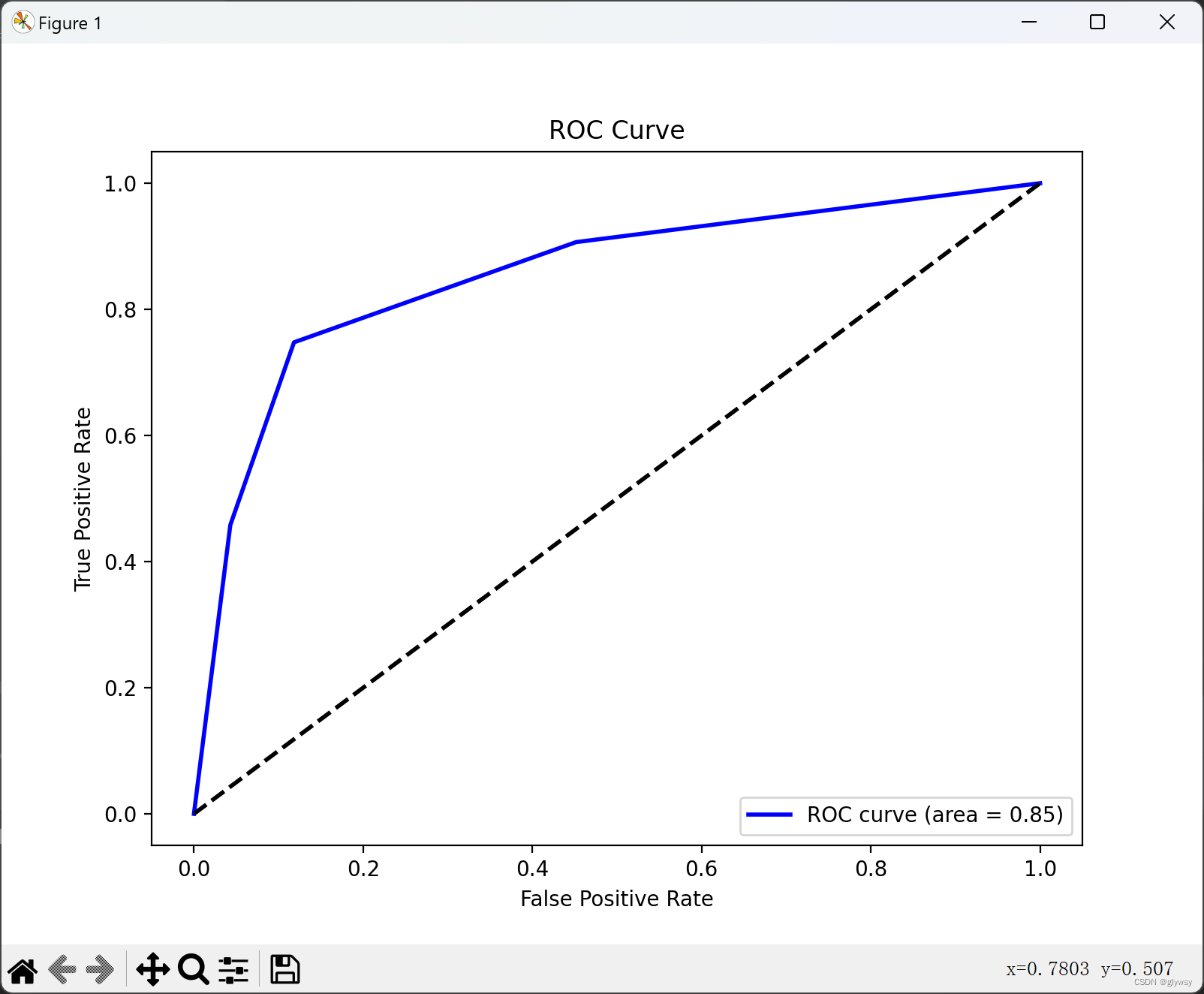
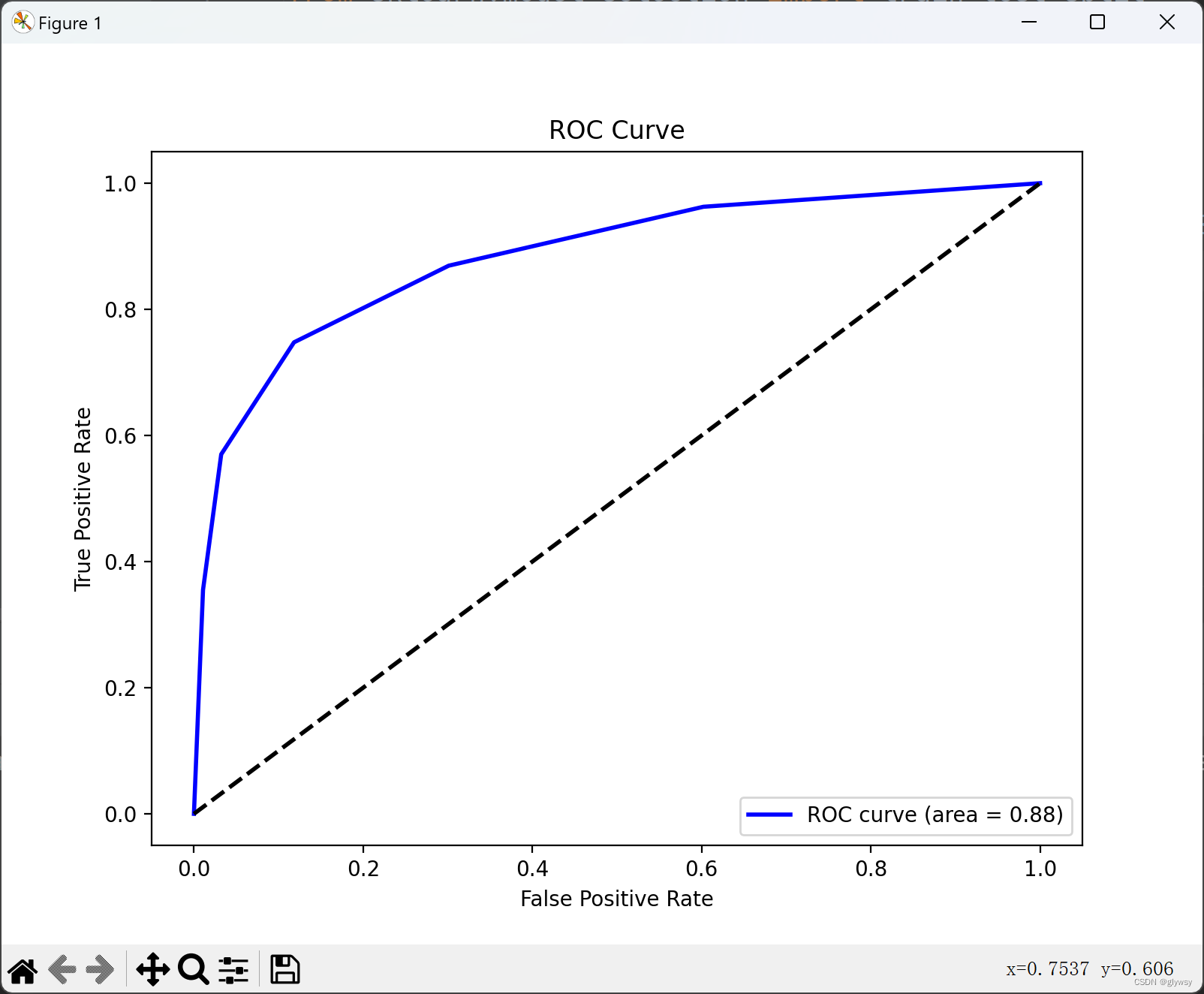
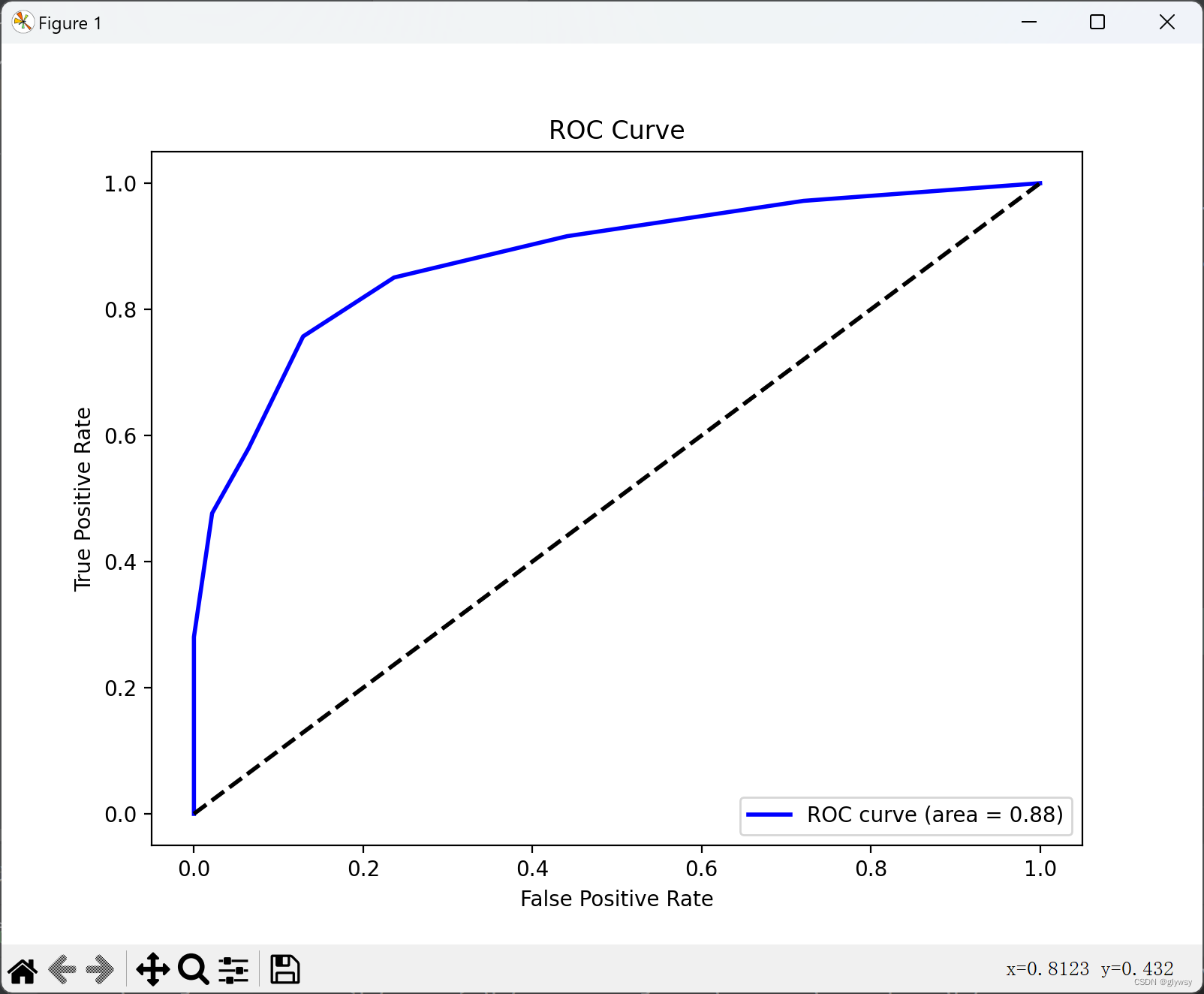
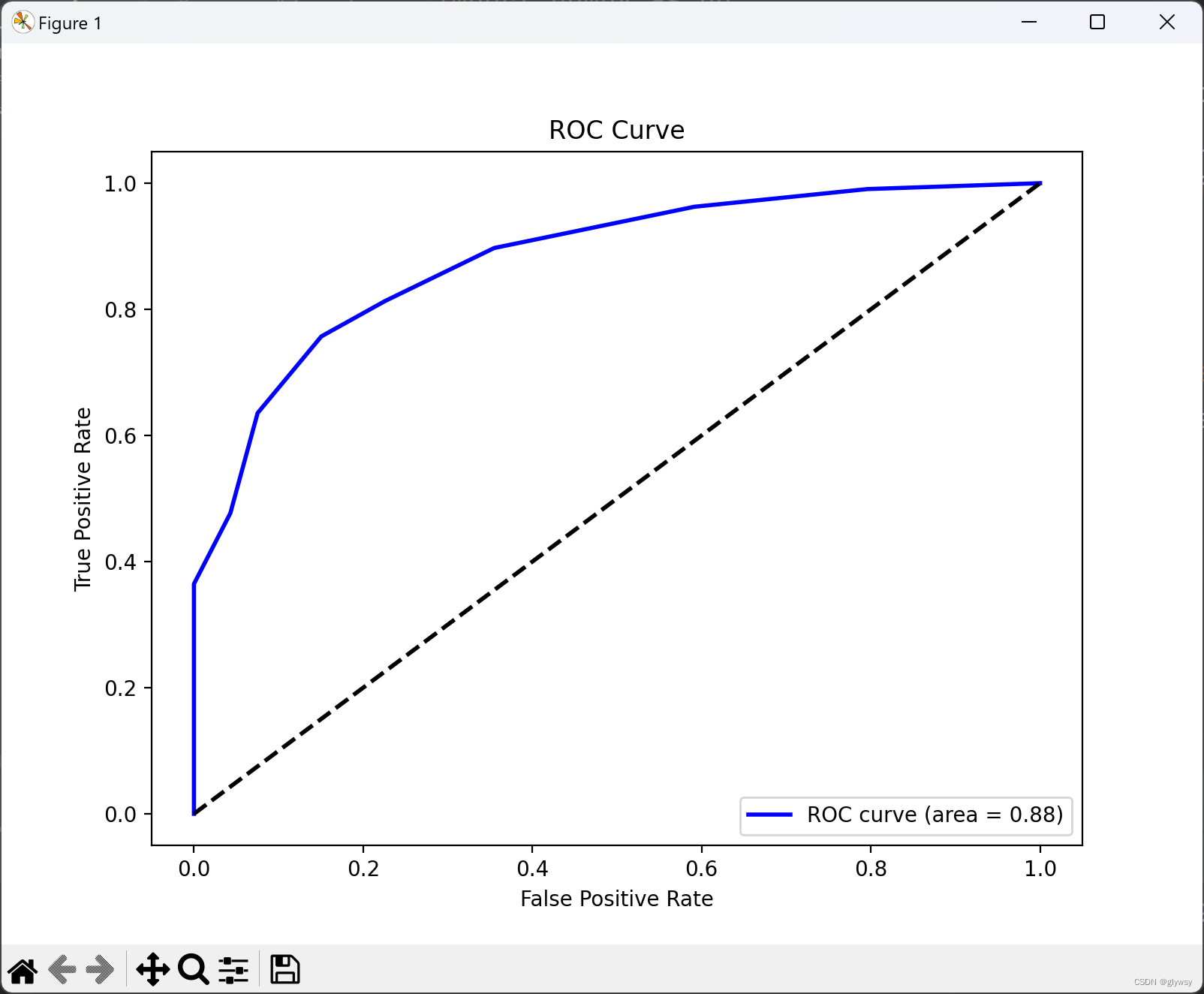
分析:
在我们的例子中,我们比较了 k 值为 1、3、5、7 和 9 时的 ROC 曲线。我们观察到:
-
当 k=1 时,模型倾向于过拟合,因为它几乎完美地匹配了训练数据。在测试数据上的性能可能不如在训练数据上的性能。这可能会导致 ROC 曲线的 AUC 值很高,但不一定能泛化到新数据。
-
当 k 值增加到 3、5 时,模型开始更加平滑,因为它考虑了更多的邻居。ROC 曲线的形状可能会有所变化,但通常 AUC 值仍然很高,因为模型在训练和测试数据上都表现良好。
-
随着 k 值继续增加到 7 和 9,模型变得更加保守,因为它考虑了更多的邻居。这可能导致模型在训练和测试数据上的性能略有下降,但是模型在新数据上的泛化性能可能更好。
综上所述,我们可以根据实际情况选择合适的 k 值。较小的 k 值可能导致过拟合,而较大的 k 值可能导致欠拟合。因此,在实际应用中,我们可能需要通过交叉验证等技术来选择最优的 k 值,以平衡模型的性能和泛化能力。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









