






一、SVM简介
支持向量机(Support Vector Machine,简称SVM)是一种用于分类和回归分析的监督学习算法。它的主要目的是找到一个最佳的决策边界(超平面),使得数据点能够被最大程度地分开,从而实现分类或预测的目标。以下是SVM的核心概念:
1. 基本原理
SVM通过寻找一个超平面来将不同类别的数据点分隔开。对于二分类问题,这个超平面所在的维度比输入数据的维度低一维。例如,在二维空间中,超平面是一条直线;在三维空间中,它是一个平面。
2. 最大化间隔
SVM的目标是找到一个能够最大化两类数据点之间间隔(margin)的超平面。这个间隔定义为从超平面到最近的正类和负类数据点的距离之和。通过最大化这个间隔,SVM可以提高模型的泛化能力,即在新数据上的表现。
3. 支持向量
支持向量是离超平面最近的那些数据点,这些点对确定超平面的位置起关键作用。实际上,只有这些支持向量决定了最优超平面的方程,其余的点不影响结果。
4. 软间隔与硬间隔
在实际应用中,数据可能无法完全线性可分。为了处理这种情况,SVM引入了软间隔(soft margin)概念。通过添加一个惩罚参数 ( C ),允许某些数据点违反间隔要求,但会对这些违反行为进行惩罚。较大的 ( C ) 值意味着对错误分类的惩罚更严格,较小的 ( C ) 值则允许更多的错误分类。
5. 核函数
当数据在原始空间中无法用线性超平面分开时,SVM可以使用核函数(kernel function)将数据映射到更高维空间,在高维空间中找到线性可分的超平面。常见的核函数包括:
- 线性核(Linear Kernel):适用于线性可分的数据。
- 多项式核(Polynomial Kernel):适用于特征间存在多项式关系的数据。
- 高斯径向基核(RBF Kernel):适用于复杂的非线性分类。
- Sigmoid核(Sigmoid Kernel):类似神经网络中的激活函数。
6. 优化问题
SVM的训练过程可以转化为一个凸优化问题,通过求解拉格朗日乘子来找到最优超平面。这通常涉及二次规划(Quadratic Programming,QP)技术。
二、SVM的基本步骤
-
收集数据:首先,收集用于训练和测试SVM模型的数据。每个数据点都应该有相应的标签,以指示其所属的类别。
-
特征选择和预处理:在训练SVM之前,需要对数据进行特征选择和预处理。这包括特征缩放、特征降维和特征选择等操作,以确保数据的质量和有效性。
-
训练模型:使用训练数据集,通过计算最大间隔超平面来训练SVM模型。最大间隔超平面是能够将不同类别的数据点有效分隔开的决策边界。
-
选择核函数:SVM可以使用不同的核函数来处理非线性问题。根据数据的特点选择合适的核函数,常见的核函数包括线性核、多项式核和高斯核等。
-
调参与交叉验证:SVM有一些重要的参数需要调整,例如正则化参数C和核函数的参数。可以使用交叉验证技术来选择最优的参数组合,以提高模型的性能和泛化能力。
-
预测和评估:使用训练好的SVM模型对新的未标记数据进行预测,并将其分类到相应的类别中。使用评估指标(如准确率、精确率、召回率和F1值)来评估模型的性能。
-
模型优化:根据模型在实际应用中的表现,可以进行模型优化和调整。可能需要尝试不同的核函数、参数设置或特征工程方法,以获得更好的结果。
三、实例
这里我将举一个简单的实例,假设我们有一个关于某种水果分类的数据集。这个数据集中包含了水果的重量和颜色强度两个特征,并且我们要将这些水果分为苹果和橘子两类。
数据集如下:
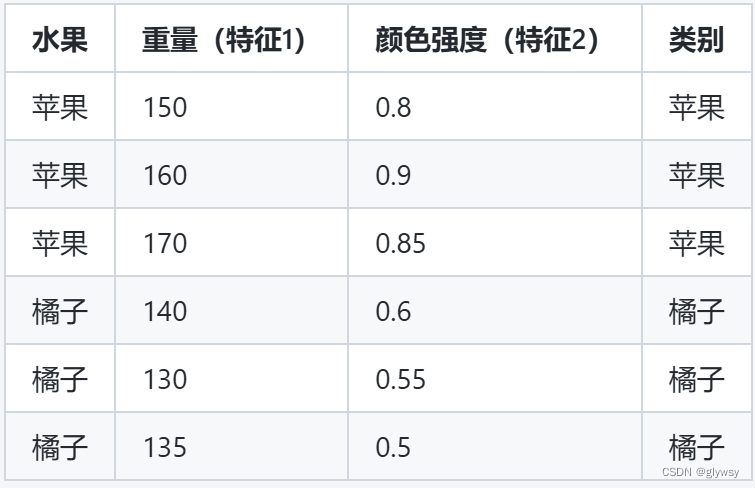
代码实现:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Create dataset
data = {
'Fruit': ['Apple', 'Apple', 'Apple', 'Orange', 'Orange', 'Orange'],
'Weight': [150, 160, 170, 140, 130, 135],
'ColorIntensity': [0.8, 0.9, 0.85, 0.6, 0.55, 0.5],
'Label': ['Apple', 'Apple', 'Apple', 'Orange', 'Orange', 'Orange']
}
# Convert labels to numeric values
label_map = {'Apple': 0, 'Orange': 1}
data['Label'] = [label_map[fruit] for fruit in data['Label']]
# Extract features and labels
X = np.array(list(zip(data['Weight'], data['ColorIntensity'])))
y = np.array(data['Label'])
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train SVM model
svm = SVC(kernel='linear', C=1.0, random_state=42)
svm.fit(X_train, y_train)
# Predict and evaluate the model
y_pred = svm.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')
# Visualize decision boundary
def plot_decision_boundary(model, X, y):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', cmap=plt.cm.Paired)
plt.xlabel('Weight')
plt.ylabel('Color Intensity')
plt.title('SVM Decision Boundary')
plt.show()
plot_decision_boundary(svm, X_train, y_train)
代码解释:
- 数据集创建:手动创建一个包含水果类别、重量和颜色强度的数据集,并且将类别映射为数值标签(苹果=0,橘子=1)。
- 数据预处理:标准化特征,以确保每个特征具有零均值和单位方差。
- 划分数据集:将数据分为训练集和测试集。
- 训练模型:使用线性核函数训练SVM模型。
- 评估模型:在测试集上进行预测并计算准确度。
- 可视化结果:绘制决策边界和数据点分布情况。
运行结果:
Accuracy: 100.00%

四、总结
-
优点:
- 在高维空间中依然有效。
- 对于少量的样本点也能很好地工作。
- 可以通过选择合适的核函数处理非线性问题。
-
缺点:
- 对于非常大的数据集,计算可能比较耗时。
- 对于噪声较多的数据集,性能可能下降。
- 需要调节惩罚参数 ( C ) 和选择合适的核函数。
SVM在许多实际应用中表现优异,包括图像识别、文本分类、生物信息学等领域。通过精心选择和调试参数及核函数,SVM可以成为一种非常强大的工具。















 2658
2658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









