






一、逻辑回归简介
逻辑回归(Logistic Regression)是一种用于解决二分类(0或1,是或否)问题的统计学习方法,它虽名为“回归”,但实际上是一种分类学习方法。逻辑回归通过分析因变量(目标变量)与自变量(特征变量)之间的关系,预测因变量取某个值的概率。
基本原理
逻辑回归使用sigmoid函数(或称为逻辑函数)将线性回归的预测值转换为一个概率值,这个概率值可以表示样本属于某个类别的可能性。sigmoid函数的数学表达式为:
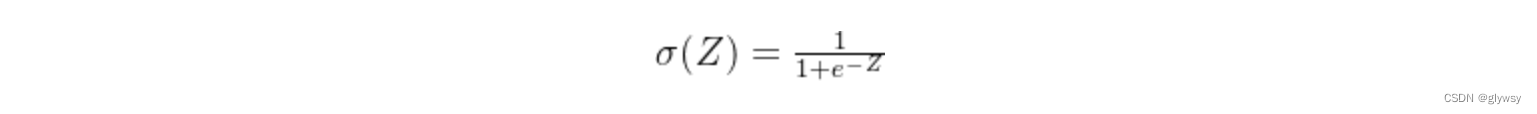
其中,( z )是特征的线性组合,即( z = w_1x_1 + w_2x_2 + ... + w_nx_n + b ),( w_i )是权重,( b )是偏差项。
sigmoid函数的值域在0和1之间,因此它可以被解释为概率。例如,如果sigmoid函数的输出为0.7,则可以解释为该样本属于正类的概率为70%。
模型训练
在逻辑回归中,我们通常使用最大似然估计(Maximum Likelihood Estimation)来估计参数 ( \theta )。具体地,我们试图找到一组参数,使得在这组参数下,样本的观测值出现的概率最大。这通常通过最小化损失函数(如交叉熵损失)来实现。
优点
- 计算效率高:逻辑回归的计算成本相对较低,因为它只涉及线性计算和sigmoid函数。
- 易于理解和实现:逻辑回归的模型简单,易于理解和解释。
- 不需要数据归一化:与一些其他算法不同,逻辑回归不需要对特征进行严格的归一化处理。
缺点
- 对非线性数据效果不佳:当数据不是线性可分时,逻辑回归的效果可能不佳。
- 对特征工程敏感:逻辑回归的性能很大程度上取决于特征的选择和构造。
- 容易过拟合:当模型复杂度过高或样本量较少时,逻辑回归容易过拟合。
二、参数估计方法
在统计学和机器学习中,参数估计是指确定模型参数的过程,以便模型能够最好地拟合数据。常见的参数估计方法包括最大似然估计(Maximum Likelihood Estimation, MLE)、最小二乘估计(Least Squares Estimation, LSE)等。在Logistic回归中,我们通常使用最大似然估计(MLE)来估计参数。
最大似然估计是一种在给定观测数据的条件下,寻找使得观测数据概率最大化的参数值的方法。在逻辑回归中,MLE尤为重要,因为逻辑回归模型的输出被解释为事件发生的概率。
逻辑回归中的MLE:
逻辑回归模型的似然函数是所有样本分类正确的概率的乘积。
对数似然函数通常被用来简化计算,因为连乘操作在对数变换后变成了求和操作。
通过最大化对数似然函数,可以得到逻辑回归模型的参数估计。
通常使用梯度下降法、牛顿法或拟牛顿法等优化算法来求解最大似然估计问题。
由于逻辑回归模型的非线性特性,最小二乘估计不适用于直接估计逻辑回归的参数。但是,有时候在逻辑回归的线性部分也可以使用类似最小二乘的方法进行参数初始化或者近似计算。
此外还有其他参数估计方法,例如贝叶斯估计、岭回归(Ridge Regression)和LASSO(Least Absolute Shrinkage and Selection Operator)以及弹性网(Elastic Net)等
参数优化
梯度上升法
梯度上升法是一种用于求解最优化问题的迭代算法,特别是在机器学习和深度学习中广泛应用于参数估计。它与梯度下降法类似,但目标是最大化目标函数,而不是最小化损失函数。在逻辑回归等模型中,通常使用梯度上升法来最大化对数似然函数,从而找到最佳参数。
梯度上升法的原理:
梯度上升法基于这样一个观察:如果目标函数在点处可微,那么在点沿着其梯度方向增长最快。因此,可以通过在当前位置沿梯度方向前进一小步来增加的值。
算法步骤
1.初始化:选择一个初始参数值和学习率(步长)。
2.迭代更新:对于第( k )次迭代,参数的更新规则为:其中,是目标函数在点的梯度。
3.收敛判断:重复迭代更新直到满足收敛条件,例如梯度的大小小于某个阈值,或者迭代次数达到预设的上限。
学习率(步长)
学习率决定了每次迭代中参数更新的幅度。如果学习率过大,可能会导致更新过度,使得算法无法收敛或者在最优点附近震荡。如果学习率过小,算法的收敛速度会非常慢,需要更多的迭代次数。
三、使用Iris数据集实现Logistic回归:
这里使用将使用 scikit-learn 库中的经典数据集——鸢尾花(Iris)数据集,来演示如何使用逻辑回归(Logistic Regression)进行分类。在这个例子中,将手动实现梯度上升法来估计参数,并使用逻辑回归模型对数据进行分类。最后,我们将计算准确率并绘制散点图来可视化结果。
三、逻辑回归案例
我们将使用sklearn中的鸢尾花(Iris)数据集,但只选择两个类别和两个特征来模拟一个二分类问题。鸢尾花数据集通常用于多类分类问题,但我们可以只选择其中的两个类别(例如:山鸢尾花和杂色鸢尾花)和两个特征(例如:花瓣长度和花瓣宽度)来创建一个二分类问题。
代码实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
# 选择两个类别(0和1)和两个特征(花瓣长度和花瓣宽度)
X = iris.data[iris.target != 2, :2] # 排除类别2(维吉尼亚鸢尾花)
y = iris.target[iris.target != 2] # 对应的标签(0和1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化逻辑回归模型
model = LogisticRegression(max_iter=1000) # 增加max_iter以避免警告(可能需要更多迭代来收敛)
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 模型的系数和截距
print(f"Coefficients: {model.coef_}")
print(f"Intercept: {model.intercept_}")
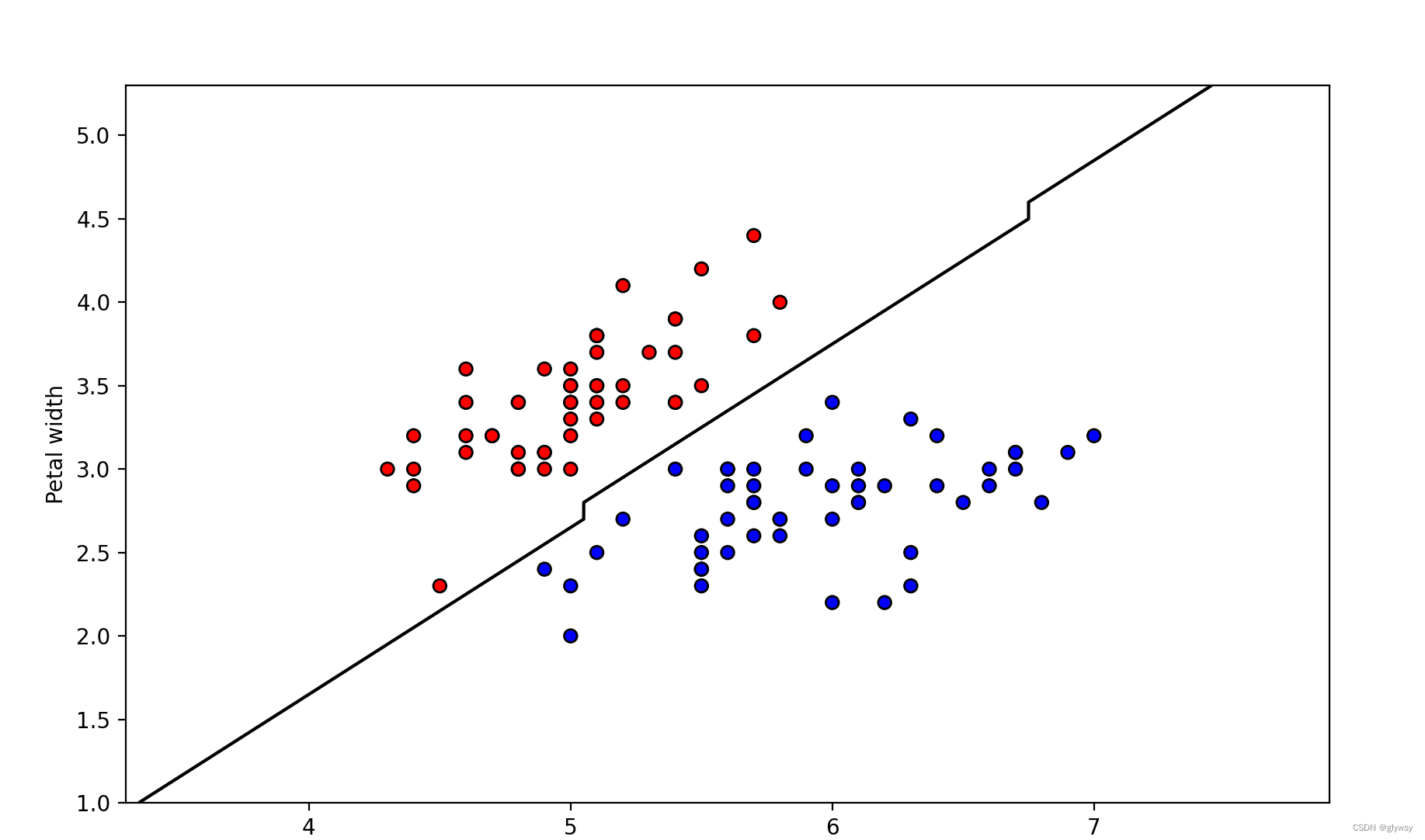
# 可视化决策边界
def plot_decision_boundary(model, X, y):
# 设置图的大小
plt.figure(figsize=(10, 6))
# 获取最小和最大的边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# 创建评估模型网格的x和y值
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
# 将网格转换为2D数组
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界(不填充颜色,仅显示轮廓)
plt.contour(xx, yy, Z, colors='k', levels=[0.5]) # 黑色轮廓线
# 绘制样本点,红色为类别0,蓝色为类别1
colors = ['red' if i == 0 else 'blue' for i in y]
plt.scatter(X[:, 0], X[:, 1], c=colors, edgecolor='k')
# 设置x和y轴的标签
plt.xlabel('Petal length')
plt.ylabel('Petal width')
# 显示图形
plt.show()
# 调用函数来绘制决策边界
plot_decision_boundary(model, X, y)- 我们首先加载了鸢尾花数据集。
- 然后,选择了两个类别(山鸢尾花和杂色鸢尾花,标签为0和1)和两个特征(花瓣长度和花瓣宽度)。
- 接着,划分了训练集和测试集。
- 之后初始化了逻辑回归模型,并设置了
max_iter参数以避免收敛警告(逻辑回归可能需要多次迭代才能收敛)。 - 使用训练数据拟合模型。
- 然后,我们对测试集进行了预测,并计算了准确率。
- 最后,我们打印了模型的系数和截距,这些值可以帮助我们理解特征对预测结果的影响。
运行结果:
Accuracy: 1.0
Coefficients: [[ 2.88998626 -2.72779317]]
Intercept: [-7.09121494]















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









