






前言
YOLO(You Only Look Once)是一个非常著名的实时目标检测系统,由Joseph Redmon等人首次提出。它因其简单、快速和高效的特点而广受欢迎。YOLO将目标检测任务视为一个回归问题,即直接在图片中预测边界框和类别概率,yolo系列是one-stage且是基于深度学习的回归方法,而R-CNN,Fast-RCNN,Faster-Rcnn等是two-stage且是基于深度学习的分类方法。
YOLOv1
yolov1的核心思想就是利用整张图作为网络的输入,直接在输出层回归bound ing box的位置和所属类别
模型结构
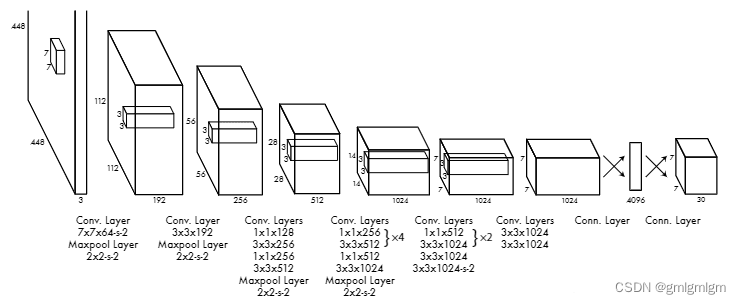
yolov1是一种传统的one-stage的卷积神经网络
优点
1.实时检测:YOLOv1能够达到每秒45帧的检测速度,这在当时是非常快的,使得实时目标检测成为可能。
2.全局理解:由于YOLOv1在整个图像上同时进行预测,因此它具有很好的全局上下文理解能力,减少了误检。
3.泛化能力:YOLOv1在训练时能够看到整个图像的上下文,这使得它在泛化到新的或不常见的对象时表现得更好。
4.端到端训练:YOLOv1是一个端到端的系统,简化了训练和推理过程,不需要复杂的流水线。
5.较少的定位误差:YOLOv1直接在图像中预测边界框,因此在定位方面通常比基于分类的方法要准确。
局限性
1.定位精度:虽然YOLOv1在定位方面比一些分类方法好,但与当时一些区域提议方法(如Fast R-CNN)相比,它在定位小目标和密集对象时精度较低。
2.每个网格的边界框数量限制:YOLOv1为每个网格单元预测B个边界框和C个条件类别概率,这限制了每个单元能检测的对象数量。
3.尺度变化问题:YOLOv1在处理不同尺度的对象时效果不佳,特别是对于小对象,由于其较小的感受野,YOLOv1很难准确地检测到。
4.泛化能力的局限性:虽然YOLOv1在一般对象检测上表现良好,但对于高度重叠或者非常规形状的
YOLOV2
YOLOv2(You Only Look Once version 2)是在YOLOv1的基础上进行改进的一个版本,它旨在提高检测的准确性和速度
模型结构
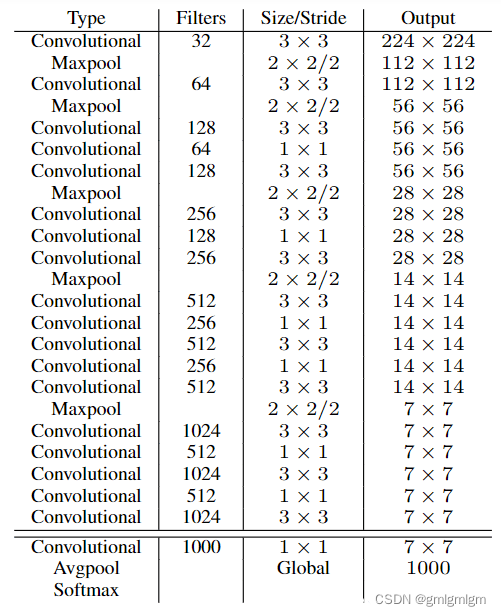
优点
1.更快更强的网络:YOLOv2使用了Darknet-19作为特征提取网络,这是一个比YOLOv1中的网络更深、性能更好的网络,同时速度也更快。
2.引入anchor boxes:YOLOv2借鉴了Faster R-CNN中的anchor boxes概念,通过预测anchor boxes的偏移量而不是直接预测边界框,提高了定位的准确性。
3.更好的尺度处理:YOLOv2通过在多个尺度上进行预测,改善了小目标的检测能力。它使用了passthrough层来将高分辨率的特征图与低分辨率的特征图结合起来,从而捕捉到更细粒度的信息。
4.准确性和速度的平衡:YOLOv2在保持实时检测的同时,显著提高了检测的准确性,特别是在小目标的检测上。
5.泛化能力:YOLOv2在训练时使用了大量的数据增强技术,提高了模型对不同尺寸和角度的对象的泛化能力。
6.类别预测:YOLOv2使用softmax层进行类别预测,并且可以预测每个边界框的类别,而不仅仅是每个单元格的类别。
局限性
1.小目标检测:虽然YOLOv2在小目标检测上有所改进,但与其他一些专门针对小目标设计的检测算法相比,仍然存在局限性。
2.定位误差:YOLOv2在定位精度上有所提升,但与一些基于区域提议的算法相比,仍然存在一定的定位误差。
3.上下文信息的利用:尽管YOLOv2在全局上下文理解方面有所改进,但与一些基于分割的方法相比,它在利用局部上下文信息方面可能不够充分。
4.每个网格的边界框数量限制:YOLOv2仍然受到每个网格单元预测的边界框数量限制,这可能会影响模型检测密集对象的能力。
5.训练难度:YOLOv2的训练过程相对复杂,需要仔细调整超参数和锚框的设计,以达到最佳性能。
YOLOV3
2018年,作者Redmon又在YOLOv2的基础上做了一些改进。特征提取部分采用Darknet-53网络结构代替原来的Darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实用性的同时保证了目标检测的准确性。
模型结构
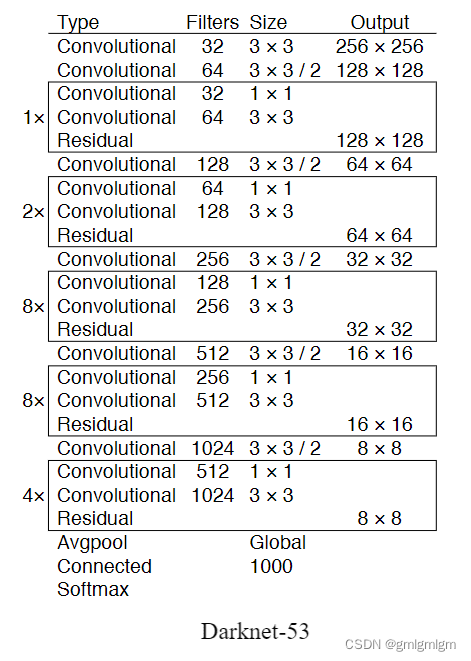
网络结构
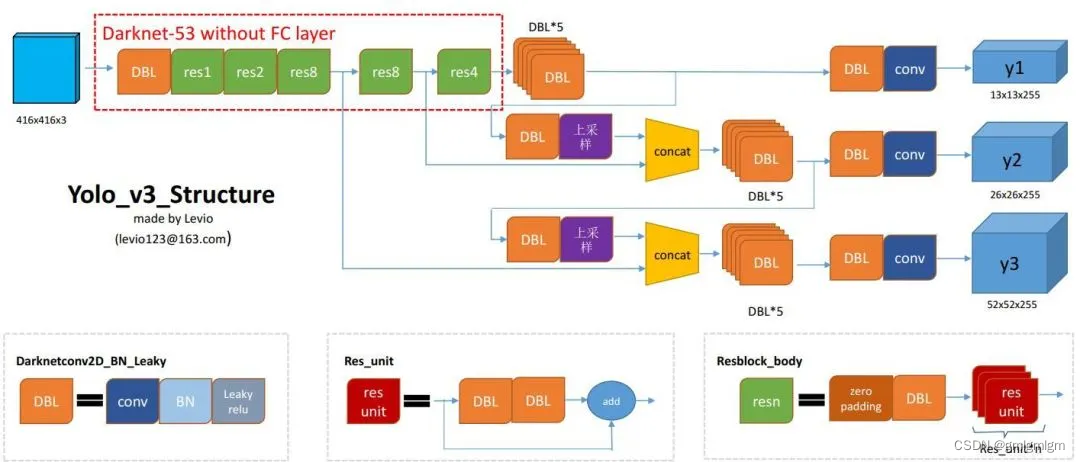
YOLOv3(You Only Look Once version 3)是在YOLOv2的基础上进一步改进的一个版本,它旨在提高检测的准确性和灵活性。
优点
1.多尺度预测:YOLOv3在三个不同尺度的特征图上进行预测,这使得它能够更好地检测到不同大小的对象,特别是小对象。
2.深度特征提取网络:YOLOv3使用了Darknet-53作为特征提取网络,这是一个比YOLOv2中的Darknet-19更深、性能更好的网络。
3.类别预测:YOLOv3使用独立的逻辑回归分类器来预测每个边界框的类别,而不是使用softmax层,这使得它可以处理多标签分类问题。
4.锚框设计:YOLOv3为每个尺度设计了不同的锚框,以更好地适应不同大小的对象。
5.速度与准确性的平衡:YOLOv3在保持较高检测速度的同时,提高了检测的准确性,特别是在小目标和复杂场景中的检测。
6.开源和易于部署:YOLOv3的代码是开源的,并且可以在多种平台上轻松部署,包括CPU、GPU和移动设备。
局限性
1.定位精度:虽然YOLOv3在定位方面有所改进,但在处理一些极端情况下,如高度遮挡或非常规形状的对象时,仍然存在一定的局限性。
2.小目标检测:尽管YOLOv3通过多尺度预测改善了小目标的检测,但在某些情况下,小目标的检测仍然是一个挑战。
3.计算资源需求:YOLOv3相对于YOLOv2来说,使用了更深的网络,因此在计算资源上的需求也更高。
4.训练难度:YOLOv3的训练过程相对复杂,需要大量的数据和计算资源,以及精细的超参数调整。
5.上下文信息的利用:尽管YOLOv3在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
YOLOV4
2020年4月,YOLOv4保持了相同的YOLO理念——实时、开源、端到端和DarkNet框架——而且改进非常令人满意,社区迅速接受了这个版本作为官方的YOLOv4。
网络结构
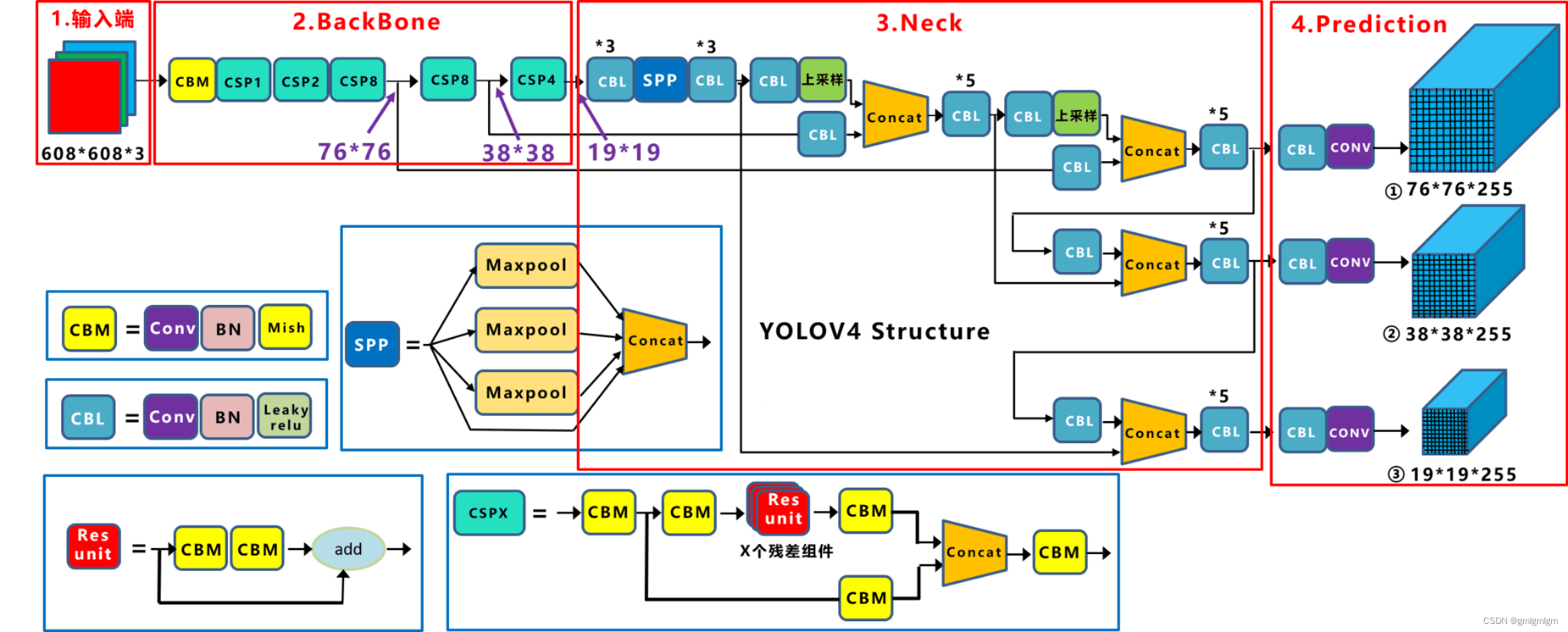
优点
1.高效的网络架构:YOLOv4使用了CSPDarknet53作为主干网络,结合了Mish激活函数,提高了特征提取的效率和准确性。
2.数据增强和正常化:YOLOv4采用了Mosaic数据增强、Self-Adversarial Training (SAT)和余弦退火等策略,提高了模型的泛化能力。
3.锚框和边界框预测:YOLOv4使用了新的锚框计算方法,并结合了Sigmoid函数来预测边界框的宽高,使得模型在预测不同形状和大小的对象时更加准确。
4.多尺度预测:YOLOv4在三个不同尺度的特征图上进行预测,这使得它能够更好地检测到不同大小的对象。
5.目标函数:YOLOv4使用了CIOU_loss作为目标函数,这有助于模型更好地学习预测边界框的位置。
6.速度与准确性的平衡:YOLOv4在保持较高检测速度的同时,通过上述多种技术提高了检测的准确性。
局限性
1.小目标检测:尽管YOLOv4通过多尺度预测和数据增强等手段改善了小目标的检测,但在一些极端情况下,小目标的检测仍然是一个挑战。
2.计算资源需求:YOLOv4相对于YOLOv3来说,引入了更多的计算机视觉技术,因此在计算资源上的需求也更高。
3.训练难度:YOLOv4的训练过程相对复杂,需要大量的数据和计算资源,以及精细的超参数调整。
4.上下文信息的利用:尽管YOLOv4在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
5.模型大小:YOLOv4模型的大小相比YOLOv3有所增加,这可能会影响到在一些资源受限的环境中的部署。
YOLOV5
YOLOv5有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本。文件中,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。YOLOv5s网络是YOLOv5系列中深度最小、特征图的宽度最小的网络。其他三种都是在此基础上不断加深,不断加宽。
网络结构
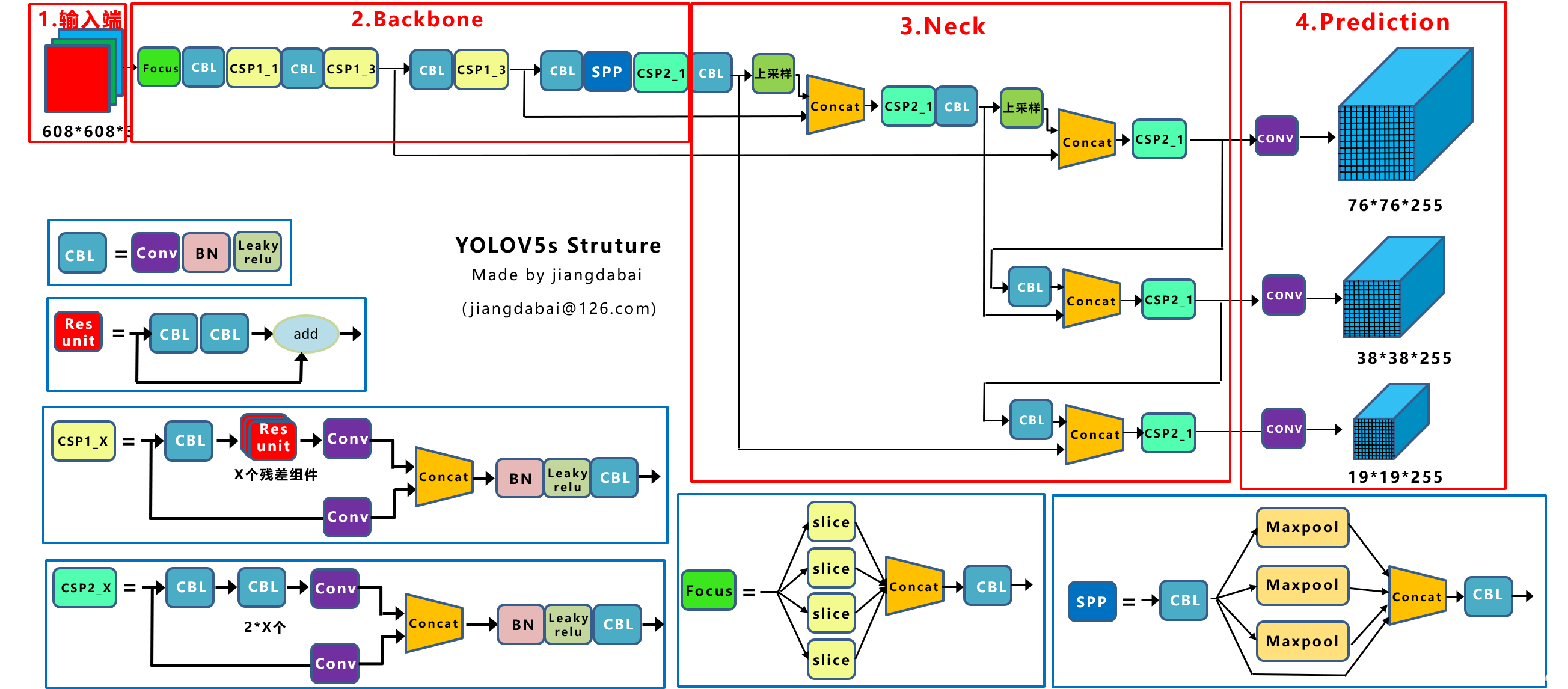
优点
1.用户友好:YOLOv5的代码是用Python编写的,并且结构清晰,易于安装和使用,对用户非常友好。
2.性能平衡:YOLOv5提供了不同大小的模型版本,包括YOLOv5s(小型),YOLOv5m(中型),YOLOv5l(大型)和YOLOv5x(超大型),用户可以根据自己的需求在速度和准确性之间进行权衡。
3.改进的模型训练:YOLOv5在模型训练方面进行了一些改进,如自动锚定框计算,这使得训练过程更加自动化和简化。
4.更好的部署流程:YOLOv5提供了更简单的模型导出和部署流程,支持ONNX和TorchScript格式,使得模型可以在不同的平台上部署。
5.实时检测性能:YOLOv5保持了YOLO系列的传统优势,即实时目标检测,即使在移动设备上也能达到很高的帧率。
6.社区支持:由于YOLOv5的用户友好性和高性能,它拥有一个活跃的社区,提供了大量的教程、预训练模型和工具
局限性
1.小目标检测:尽管YOLOv5在多尺度预测方面有所改进,但在检测非常小或密集的对象时仍然存在挑战。
2.定位精度:与一些基于区域提议的算法相比,YOLOv5在精确的边界框定位方面可能稍显不足。
3.上下文信息的利用:虽然YOLOv5在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
4.计算资源需求:对于较大的模型版本(如YOLOv5x),计算资源的需求较高,这可能限制了在一些资源受限环境中的使用。
5.训练数据需求:YOLOv5的性能在很大程度上依赖于大量的训练数据,对于一些特定的应用领域,可能需要大量的标注数据来获得最佳性能。
YOLOV6
YOLOX在YOLO系列的基础上做了一系列的工作,其主要贡献在于:在YOLOv3的基础上,引入了Decoupled Head,Data Aug,Anchor Free和SimOTA样本匹配的方法,构建了一种anchor-free的端到端目标检测框架,并且达到了一流的检测水平。
网络结构
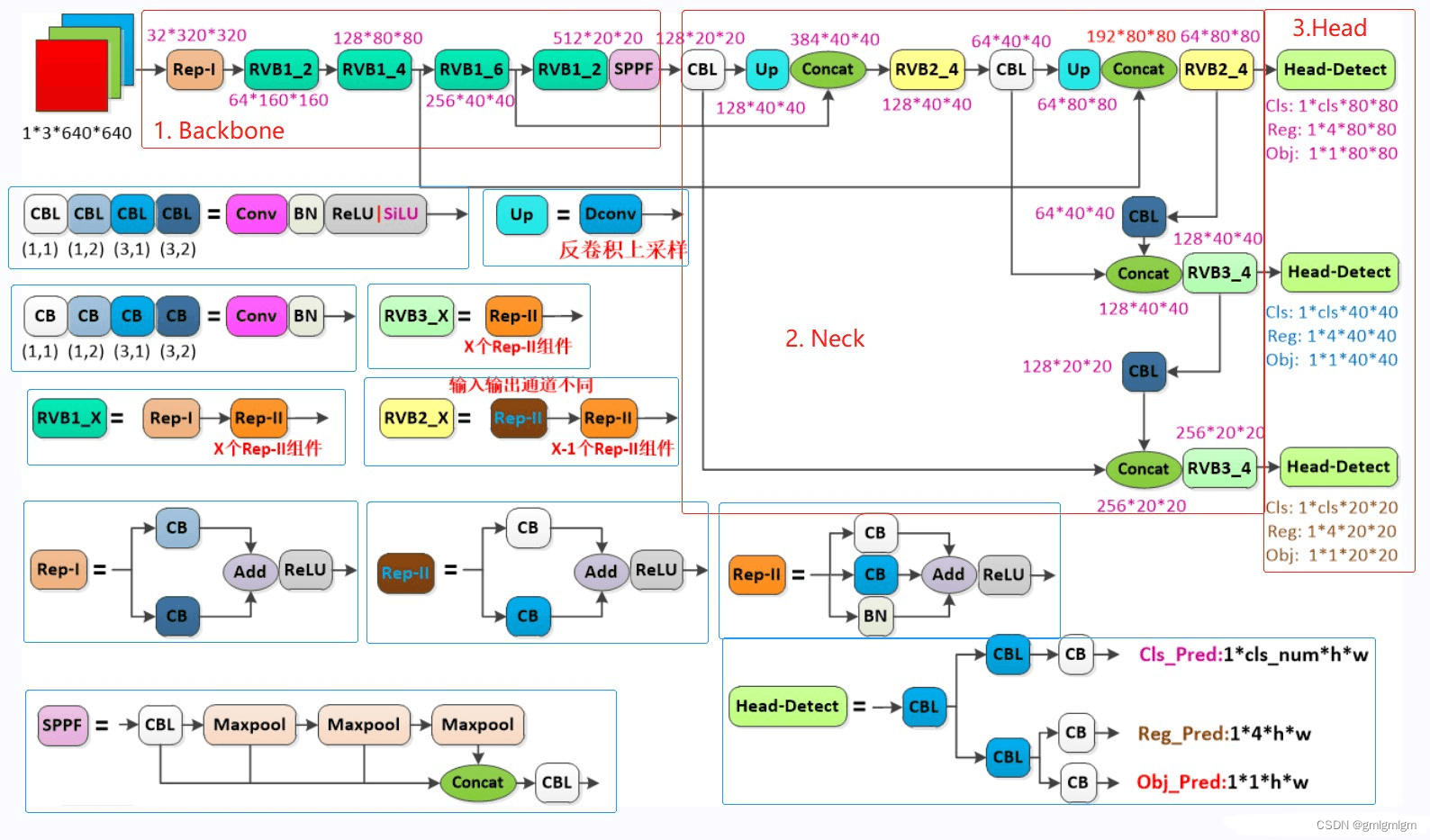
优点
1.更快的检测速度:YOLOv6通过优化网络结构和训练流程,实现了比前代更快的检测速度,这使得它在实时应用中更具优势。
2.改进的网络架构:YOLOv6采用了EfficientCSpod网络架构,这是一种新的CSPNet变体,旨在提高计算效率和准确性。
3.更准确的检测:YOLOv6在多个目标检测基准上展示了比前代更高的准确性,特别是在小目标的检测上有所改进。
4.简化的训练过程:YOLOv6简化了训练流程,使得模型的训练和调整更加容易。
5.更好的部署能力:YOLOv6支持多种部署平台,包括移动设备和边缘设备,这使得它在实际应用中更加灵活。
6.端到端优化:YOLOv6采用了端到端的优化策略,包括改进的标签分配和损失函数,以提高检测性能。
局限性
1.小目标检测:尽管YOLOv6在小目标检测上有所改进,但在一些极端情况下,特别是在高分辨率图像中,小目标的检测仍然是一个挑战。
2.计算资源需求:YOLOv6在某些情况下可能需要更多的计算资源,尤其是在使用较大的模型版本时。
3.训练数据需求:YOLOv6的性能在很大程度上依赖于大量的训练数据,对于一些特定的应用领域,可能需要大量的标注数据来获得最佳性能。
4.上下文信息的利用:虽然YOLOv6在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
5.模型大小:YOLOv6模型的大小可能比前代更大,这可能会影响到在一些资源受限的环境中的部署。
YOLOV7
YOLOv7由YOLOv4和YOLOR的同一作者于2022年7月发表在ArXiv。与YOLOv4一样,它只使用MS COCO数据集进行训练,没有预训练的骨干。YOLOv7提出了一些架构上的变化和一系列的免费包,在不影响推理速度的情况下提高了准确率,只影响了训练时间。
网络结构
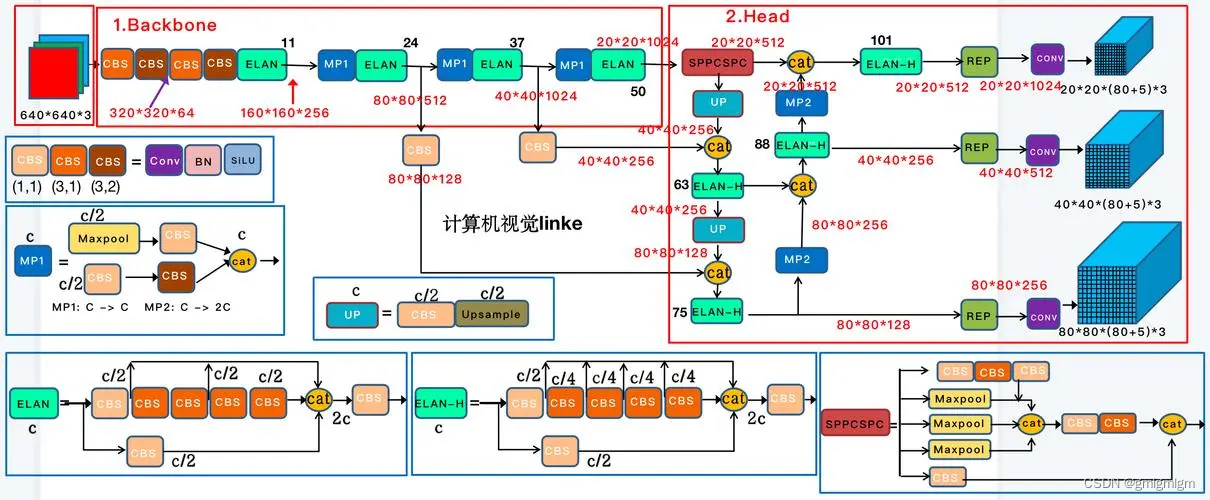
优点
1.更快的检测速度:YOLOv7通过优化网络结构和训练流程,实现了比前代更快的检测速度,这使得它在实时应用中更具优势。
2.更高的准确性:YOLOv7在多个目标检测基准上展示了比前代更高的准确性,特别是在小目标的检测上有所改进。
3.改进的网络架构:YOLOv7采用了EfficientCSpod网络架构,这是一种新的CSPNet变体,旨在提高计算效率和准确性。
4.简化的训练过程:YOLOv7简化了训练流程,使得模型的训练和调整更加容易。
5.更好的部署能力:YOLOv7支持多种部署平台,包括移动设备和边缘设备,这使得它在实际应用中更加灵活。
6.端到端优化:YOLOv7采用了端到端的优化策略,包括改进的标签分配和损失函数,以提高检测性能。
局限性
1.小目标检测:尽管YOLOv7在小目标检测上有所改进,但在一些极端情况下,特别是在高分辨率图像中,小目标的检测仍然是一个挑战。
2.计算资源需求:YOLOv7在某些情况下可能需要更多的计算资源,尤其是在使用较大的模型版本时。
3.训练数据需求:YOLOv7的性能在很大程度上依赖于大量的训练数据,对于一些特定的应用领域,可能需要大量的标注数据来获得最佳性能。
4.上下文信息的利用:虽然YOLOv7在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
5.模型大小:YOLOv7模型的大小可能比前代更大,这可能会影响到在一些资源受限的环境中的部署。
YOLOV8网络结构
YOLOv8 与YOLOv5出自同一个团队,是一款前沿、最先进(SOTA)的模型,基于先前 YOLOv5版本的成功,引入了新功能和改进,进一步提升性能和灵活性。
YOLOv8是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,这也使其成为对象检测、图像分割和图像分类任务的绝佳选择。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,还支持YOLO以往版本,方便不同版本切换和性能对比。
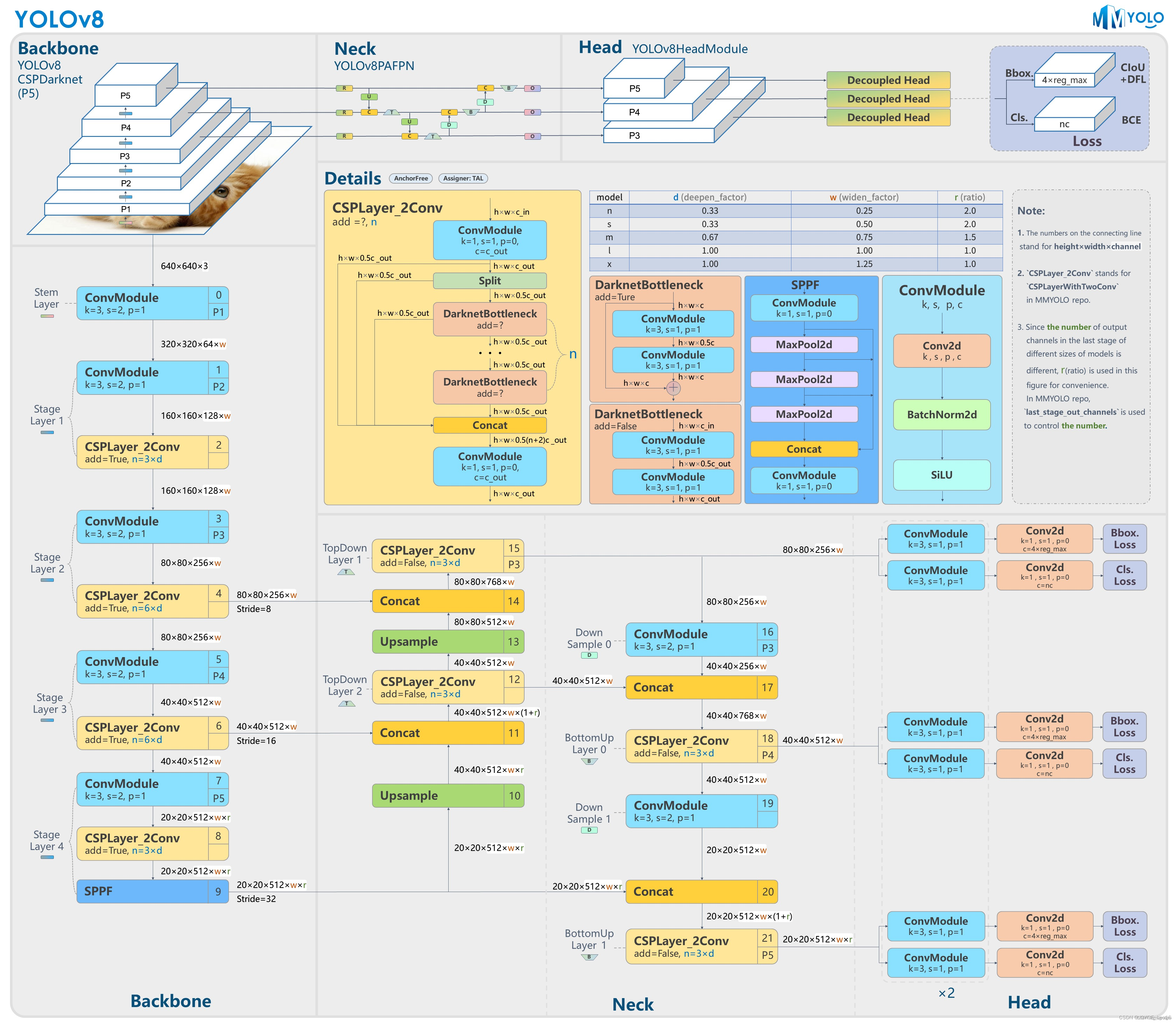
优点
1.更快的检测速度:YOLOv8通过优化网络结构和训练流程,实现了比前代更快的检测速度,这使得它在实时应用中更具优势。
2.更高的准确性:YOLOv8在多个目标检测基准上展示了比前代更高的准确性,特别是在小目标的检测上有所改进。
3.改进的网络架构:YOLOv8采用了EfficientCSpod网络架构,这是一种新的CSPNet变体,旨在提高计算效率和准确性。
4.简化的训练过程:YOLOv8简化了训练流程,使得模型的训练和调整更加容易。
5.更好的部署能力:YOLOv8支持多种部署平台,包括移动设备和边缘设备,这使得它在实际应用中更加灵活。
6.端到端优化:YOLOv8采用了端到端的优化策略,包括改进的标签分配和损失函数,以提高检测性能。
局限性
1.小目标检测:尽管YOLOv8在小目标检测上有所改进,但在一些极端情况下,特别是在高分辨率图像中,小目标的检测仍然是一个挑战。
2.计算资源需求:YOLOv8在某些情况下可能需要更多的计算资源,尤其是在使用较大的模型版本时。
3.训练数据需求:YOLOv8的性能在很大程度上依赖于大量的训练数据,对于一些特定的应用领域,可能需要大量的标注数据来获得最佳性能。
4.上下文信息的利用:虽然YOLOv8在全局上下文理解方面有所改进,但在一些复杂的场景中,它可能仍然无法充分利用局部上下文信息。
5.模型大小:YOLOv8模型的大小可能比前代更大,这可能会影响到在一些资源受限的环境中的部署。
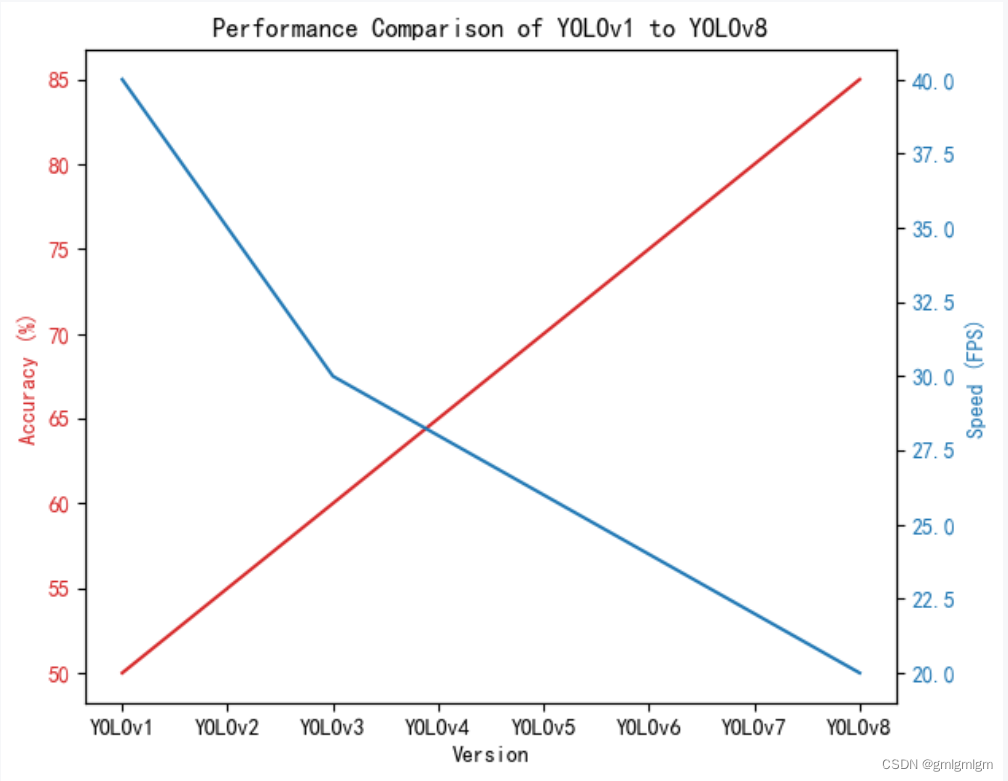
yolov1-yolov8性能对比图
此图针对准确率和速度进行对比,图表中展示了不同版本在准确性和速度方面的表现。准确性以百分比表示,速度以每秒帧数(FPS)表示。















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









