







深度学习的经典检测方法有两种方式:two-stage和one-stage,属于two-stage的有Mask-Rcnn等,而YOLO(You Only Look Once)属于one-stage,这两者的主要区别是two-stage多了一步预选,因此two-stage的准确度要高一些,速度相对one-stage慢得多。
YOLO-V1


YOLOV1核心思想,简单的说就是在每个监测点上产生横竖两个框,再将置信度大于阈值的作为物体,其他的作为背景。接着在两个框中选出Iou大的,算出x,y,w,h,画出预测框。
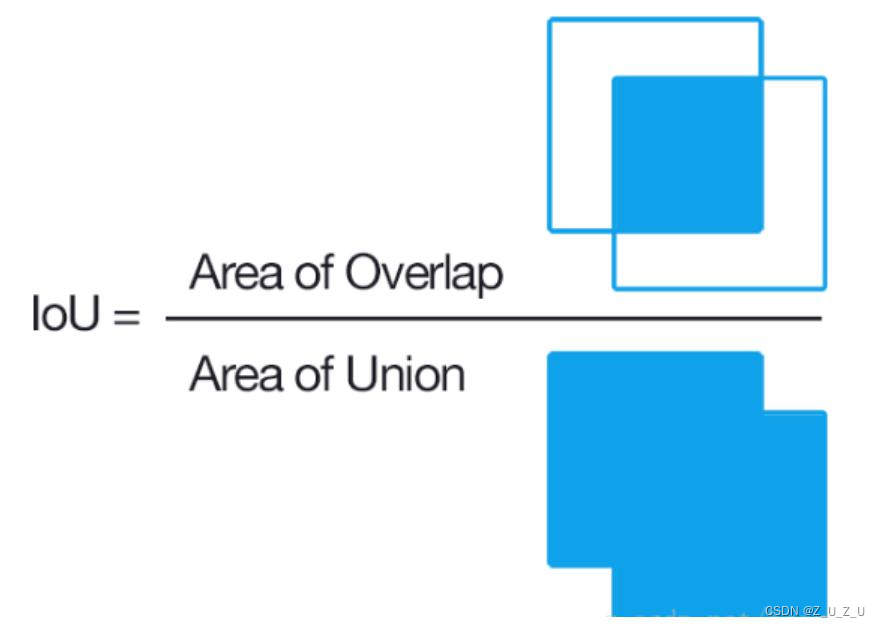
Iou(Intersection over union)即真值与预测值的交集比上真值与预测值的并集,在物体检测中一般Iou值越大越好,具体如下图所示:
网络结构中reshape后得到的7×7×30含义:7×7为最终网格大小,30分为B1(x,y,w,h,c共5个)+B2(x,y,w,h,c共5个)+20分类。

YOLOV1为物体检测领域带来了很多新思想,但是它的缺点也十分明显,每个cell只能预测一个类别,并且无法解决物体重叠的问题。此外,YOLOV1对小物体的检测效果也不理想。 因此更强的YOLOV2来了。
YOLO-V2
YOLOV2与V1相比舍弃了dropout(dropout的作用是防止过拟合),而采用了卷积后进行Batch Normalization,将网络的每一层都做了归一化,让收敛相对更容易。
V1训练时用的分辨率是224×224,测试时是448×448。V2在训练时额外进行了十次448×448的微调。
V2在网络结构中的实际输入为416×416,但在网络中没有设置全连接(FC)层,而是使用了五次降采样来减少输出的大小。
V2引入了anchor boxes使预测的box数更多。需要注意的是,V2中的预测框采用了相对位置来表示,其计算公式如下
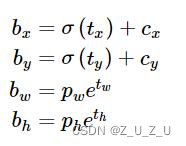

其中σ为sigmoid函数,关于这个函数网上有很多科普与解析,这里不在赘述。在上图中,原点为(Cx,Cy),而bbox原点为(bx,by),是原点相对偏移后的结果。
YOLO-V3
讲V3前先放一张图

这里将V3的曲线放到坐标轴外应该是作者整的活,意思大概是“我比你们厉害多了!”
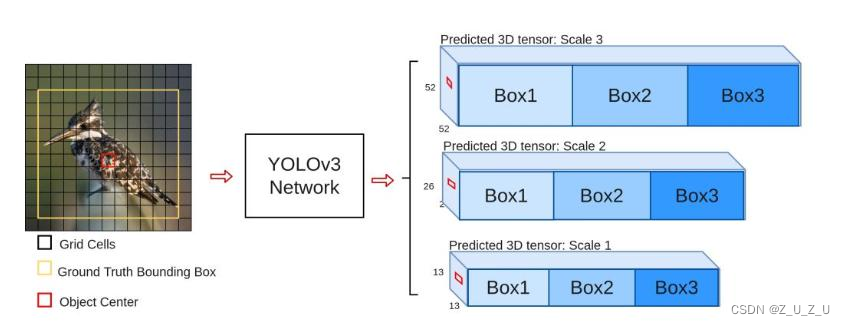
V3为了增加对小物体检测的准确度,用了三种scale,每种3个规格,一共9种先验框。
V3的核心思想之一是不同的特征图融合后进行预测,比如先进行上采样再进行融合。V3也运用了resnet的思想,堆叠了更多层来进行特征提取,其网络结构如下图所示
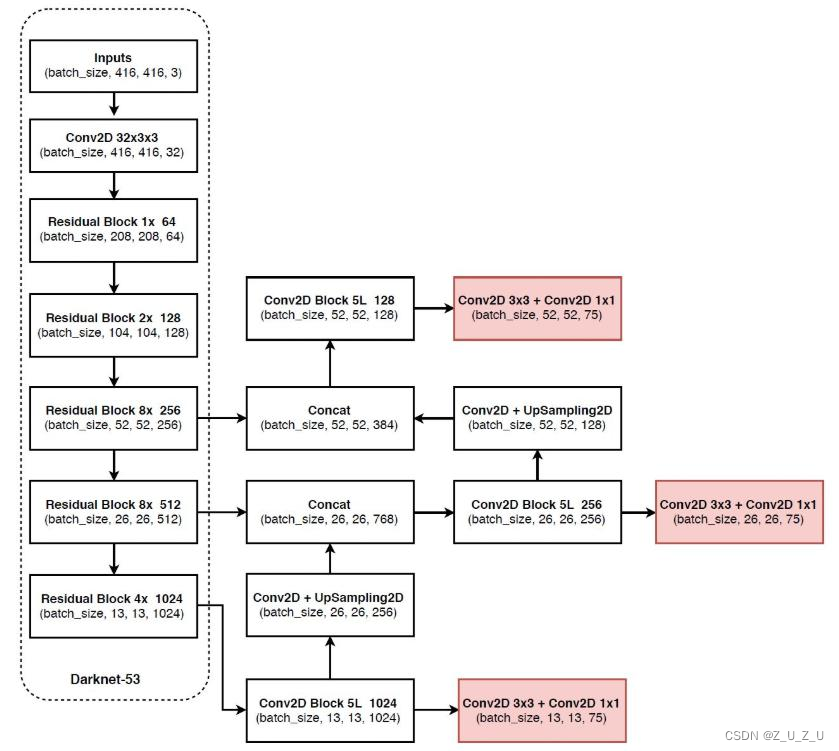
可以看到,V3的网络结构中没有池化和全连接层,下采样通过stride为2实现,并有三种大小的特征图和9种先验框,分别是在13*13特征图上:(116x90),(156x198),(373x326)三种尺寸;26*26特征图上:(30x61),(62x45),(59x119)三种尺寸;52*52特征图上:(10x13),(16x30),(33x23)三种尺寸。

















 886
886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









