







本文将从底层原理和源代码的角度详细解释 HashMap 的头插法和尾插法,尽量用通俗易懂的语言,确保初学者也能理解。我们会一步步推导,涵盖原理、代码、优缺点,以及为什么会有这样的设计变化(尤其是在 Java 8 中从头插法改为尾插法的原因)。
1. HashMap 的基本概念
为了理解头插法和尾插法,我们先快速回顾一下 HashMap 的核心原理。
1.1 HashMap 是什么?
HashMap 是 Java 中的一种键值对存储结构,底层基于 哈希表 实现。简单来说,它像一个有很多抽屉的柜子:
- 每个抽屉(称为“桶”,英文是 bucket)可以通过键(key)的哈希值快速定位。
- 同一个抽屉里可能存多个键值对(因为哈希冲突),这些键值对组成一个链表(Java 8 以后,链表可能转为红黑树以优化性能)。
1.2 哈希表的核心
- 哈希函数:将键(key)映射到一个整数(哈希值),再通过这个整数找到对应的桶。
- 哈希冲突:不同的键可能映射到同一个桶(哈希值相同或取模后相同)。
- 解决冲突:通过链表(或红黑树)将同一个桶中的多个键值对串起来。
1.3 插入操作
当我们调用 put(key, value) 方法时,HashMap 会:
- 计算 key 的哈希值,确定它应该放在哪个桶。
- 如果桶是空的,直接放入键值对。
- 如果桶里已经有数据(冲突),需要将新键值对插入到这个桶的链表中。插入时,有两种方式:头插法(插到链表头部)和 尾插法(插到链表尾部)。
头插法和尾插法的区别就在于新节点插入链表的位置不同,接下来我们详细分析。
2. 头插法(Head Insertion)
2.1 什么是头插法?
头插法是指将新插入的键值对节点放在链表的头部。在 Java 7 及更早版本的 HashMap 中,插入新节点时使用的是头插法。
所谓头插法,就是在创建链表的时候,每次拿到一个新的节点就插在Head之后。即如果用3个整形数1,2,3来创建链表,如果按照数字升序输入数据,那么用头插法创建后得到的链表则为3->2->1
头插法的步骤如下图:
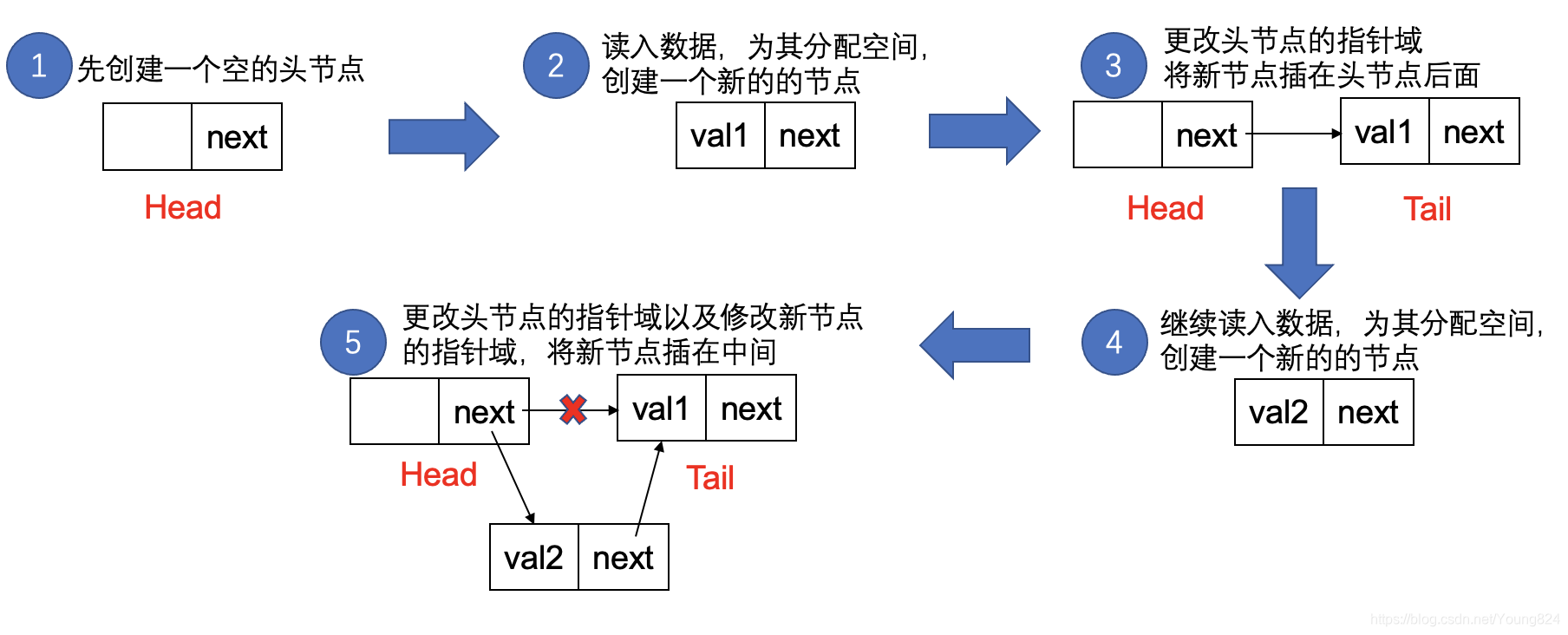
2.2 为什么用头插法?
- 效率高:头插法只需要修改链表头部的指针,无需遍历整个链表,时间复杂度是 O(1)。
- 简单:只需要将新节点的
next指针指向原来的头部节点,再更新桶的引用指向新节点即可。
2.3 头插法的步骤(以代码推导)
假设我们有一个 HashMap,某个桶的链表如下:
桶 i: [Node1(key1, value1) -> Node2(key2, value2) -> null]
现在我们要插入一个新节点 Node3(key3, value3),步骤如下:
-
计算哈希值:
- 通过
key3的哈希值,确定它应该放入桶 i。 - 假设
hash(key3)映射到桶 i。
- 通过
-
找到桶的链表头:
- 桶 i 的当前链表头是
Node1。
- 桶 i 的当前链表头是
-
创建新节点:
- 新节点
Node3包含key3和value3,其next指针暂时为 null。
- 新节点
-
插入到头部:
- 将
Node3的next指针指向当前的链表头Node1。 - 更新桶 i 的引用,使其指向
Node3。
- 将
最终链表变为:
桶 i: [Node3(key3, value3) -> Node1(key1, value1) -> Node2(key2, value2) -> null]
2.4 部分代码(Java 7 的头插法)
以下是 Java 7 中 put 方法的核心逻辑(简化版):
void put(K key, V value) {
// 计算哈希值,找到桶索引
int hash = hash(key);
int index = hash % table.length;
// 获取桶的链表头
Entry<K,V> bucketHead = table[index];
// 创建新节点
Entry<K,V> newEntry = new Entry<>(key, value, null);
// 头插法:新节点的 next 指向原链表头
newEntry.next = bucketHead;
// 更新桶的引用,指向新节点
table[index] = newEntry;
}
2.5 头插法的优点
- 插入快:无需遍历链表,时间复杂度 O(1)。
- 简单:代码实现简洁,逻辑清晰。
2.6 头插法的缺点
头插法在 多线程环境下 和 扩容(resize) 时会有问题:
问题 1:多线程并发问题
在 Java 7 中,HashMap 不是线程安全的。如果多个线程同时操作 HashMap(比如 put 或 resize),可能导致:
- 数据丢失:线程 A 和线程 B 同时插入新节点,可能覆盖彼此的操作。
- 死循环:在扩容时,头插法可能导致链表形成环(后面会详细解释)。
问题 2:扩容时的死循环
HashMap 在容量不足时会触发扩容(resize),即将所有节点重新分配到新的桶中。由于头插法在重新插入节点时会反转链表顺序,在多线程环境下可能导致链表形成环。
扩容过程:
- 创建一个更大的数组(通常是原来的两倍)。
- 将旧数组中的每个节点重新计算哈希值,放入新数组的对应桶。
- 由于头插法,新链表的顺序会与旧链表相反。
举例:
假设旧数组的桶 i 有一个链表:
桶 i: [A -> B -> C]
扩容后,节点按头插法插入新数组,可能变成:
新桶 j: [C -> B -> A]
在多线程环境下,线程 A 和线程 B 可能同时操作链表,导致指针混乱,最终形成环,例如:
[A -> B -> A]
这种环会导致 get 或其他操作陷入死循环,CPU 使用率飙升。
3. 尾插法(Tail Insertion)
3.1 什么是尾插法?
尾插法是指将新插入的键值对节点放在链表的尾部。从 Java 8 开始,HashMap 改用尾插法来解决头插法在扩容时的死循环问题。
所谓尾插法,就是在创建链表的时候,每次拿到一个新的节点就插在Tail之后,然后将新插入的节点更新为尾节点。即如果用3个整形数1,2,3来创建链表,如果按照数字升序输入数据,那么用头插法创建后得到的链表则为1->2->3
尾插法的步骤如下图:
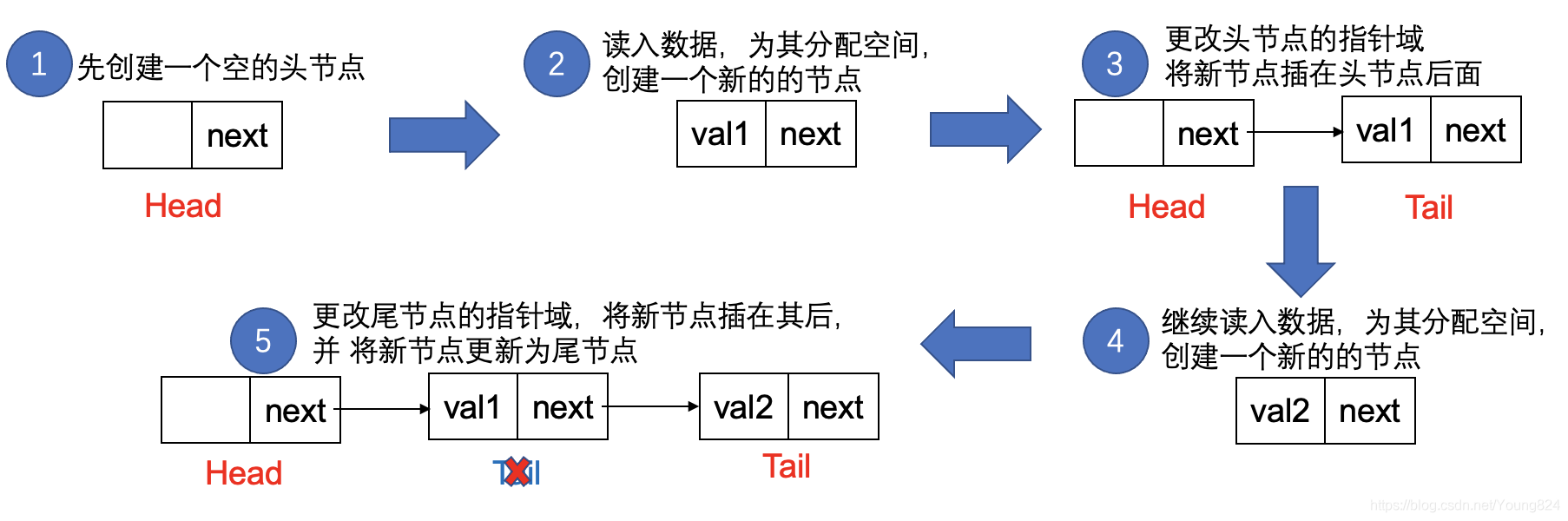
因为一开始都要先初始化列表并且读入第一个数据将其插在头节点后面,所以前4步与头插法相同,唯一有区别的就是第5步,因为是尾插法,所以新插入的节点不是插在头节点的后面,而是插在尾节点的后面,并且把新节点更新为尾节点。
3.2 为什么用尾插法?
- 避免死循环:尾插法在扩容时保持链表的相对顺序,避免了头插法导致的顺序反转,从而消除了多线程环境下链表成环的风险。
- 逻辑直观:插入到尾部更符合直觉,保持插入顺序。
3.3 尾插法的步骤(以代码推导)
继续用上面的例子,假设桶 i 的链表是:
桶 i: [Node1(key1, value1) -> Node2(key2, value2) -> null]
现在插入 Node3(key3, value3),步骤如下:
-
计算哈希值:
- 通过
key3的哈希值,确定它应该放入桶 i。
- 通过
-
找到链表尾部:
- 从
Node1开始,遍历到Node2,发现Node2.next是 null,说明Node2是尾节点。
- 从
-
创建新节点:
- 新节点
Node3包含key3和value3,其next指针为 null。
- 新节点
-
插入到尾部:
- 将
Node2的next指针指向Node3。 Node3成为新的尾节点。
- 将
最终链表变为:
桶 i: [Node1(key1, value1) -> Node2(key2, value2) -> Node3(key3, value3) -> null]
3.4 部分代码(Java 8 的尾插法)
以下是 Java 8 中 put 方法的核心逻辑(简化版):
void put(K key, V value) {
// 计算哈希值,找到桶索引
int hash = hash(key);
int index = hash % table.length;
// 获取桶的链表头
Node<K,V> bucketHead = table[index];
// 如果桶为空,直接插入
if (bucketHead == null) {
table[index] = new Node<>(key, value, null);
return;
}
// 遍历链表,找到尾节点
Node<K,V> current = bucketHead;
while (current.next != null) {
current = current.next;
}
// 尾插法:尾节点的 next 指向新节点
current.next = new Node<>(key, value, null);
}
3.5 尾插法的优点
- 线程安全改进:在扩容时,尾插法保持链表的相对顺序,避免了头插法导致的死循环问题。
- 逻辑清晰:插入顺序与遍历顺序一致,更符合直觉。
3.6 尾插法的缺点
- 插入稍慢:需要遍历链表找到尾节点,时间复杂度为 O(n)O(n),其中 nn 是链表长度。
- 不过,HashMap 的设计目标是让链表尽量短(通过好的哈希函数和扩容机制),所以实际影响较小。
- 在 Java 8 中,如果链表长度超过 8,链表会转为红黑树,进一步优化性能。
4. 头插法 vs 尾插法:详细对比
| 特性 | 头插法 (Java 7) | 尾插法 (Java 8) |
|---|---|---|
| 插入位置 | 链表头部 | 链表尾部 |
| 插入复杂度 | O(1) | O(n)(需遍历到尾部) |
| 扩容时顺序 | 链表顺序反转 | 链表顺序保持不变 |
| 多线程安全 | 可能导致死循环(链表成环) | 避免死循环 |
| 实现复杂度 | 简单 | 稍复杂(需遍历链表) |
| 适用场景 | 单线程环境下高效 | 更适合多线程和扩容场景 |
5. 为什么 Java 8 从头插法改为尾插法?
5.1 核心原因:解决死循环问题
在 Java 7 中,头插法在多线程环境下扩容时可能导致链表成环,引发死循环。这个问题在高并发场景下非常严重,可能导致程序崩溃。
Java 8 改用尾插法后:
- 扩容时链表的相对顺序保持不变,节点按原顺序插入新桶。
- 即使在多线程环境下,链表也不会形成环,极大提高了 HashMap 的健壮性。
5.2 其他优化
Java 8 还引入了其他优化,进一步弥补尾插法的性能开销:
- 红黑树:当链表长度超过 8 时,链表转为红黑树,查询和插入的复杂度从 O(n)降为 O(logn)。
- 更好的哈希函数:减少哈希冲突,使链表长度尽量短,降低尾插法的遍历开销。
5.3 注意事项
虽然尾插法解决了死循环问题,但 HashMap 仍然不是线程安全的。在多线程环境下,应该使用 ConcurrentHashMap 或通过 Collections.synchronizedMap 包装 HashMap。
6. 实际代码示例(Java 7 vs Java 8)
为了让初学者更直观地理解,我们提供一个完整的代码示例,展示头插法和尾插法的区别。
6.1 Java 7 头插法(简化版)
class HashMap7<K, V> {
static class Entry<K, V> {
K key;
V value;
Entry<K, V> next;
Entry(K key, V value, Entry<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
Entry<K, V>[] table = new Entry[16];
void put(K key, V value) {
int hash = key.hashCode();
int index = hash % table.length;
// 头插法
Entry<K, V> newEntry = new Entry<>(key, value, table[index]);
table[index] = newEntry;
}
}
6.2 Java 8 尾插法(简化版)
class HashMap8<K, V> {
static class Node<K, V> {
K key;
V value;
Node<K, V> next;
Node(K key, V value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
Node<K, V>[] table = new Node[16];
void put(K key, V value) {
int hash = key.hashCode();
int index = hash % table.length;
// 桶为空,直接插入
if (table[index] == null) {
table[index] = new Node<>(key, value, null);
return;
}
// 尾插法
Node<K, V> current = table[index];
while (current.next != null) {
current = current.next;
}
current.next = new Node<>(key, value, null);
}
}
6.3 运行对比
假设我们依次插入键值对 (k1, v1)、(k2, v2)、(k3, v3),它们都映射到同一个桶:
-
Java 7(头插法):
桶: [k3 -> k2 -> k1] -
Java 8(尾插法):
桶: [k 桶: [k1 -> k2 -> k3]
7. 总结
-
头插法(Java 7):
- 插入到链表头部,效率高 (O(1)),但在多线程扩容时可能导致死循环。
- 适合单线程场景,但不适合高并发环境。
-
尾插法(Java 8):
- 插入到链表尾部,稍微慢一些 (O(n)),但避免了死循环问题,适合现代多线程环境。
- 配合红黑树等优化,性能仍然高效。
-
为什么改用尾插法:
- 解决了头插法在扩容时的死循环问题,提高了 HashMap 的健壮性。
-
建议:
- 单线程用 HashMap 没问题。
- 多线程场景推荐用
ConcurrentHashMap。


















 2927
2927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









