







本文写于2025年2月18日晚六点,发布时间待定
一、思路梳理
对于给出的课题——“基于Python+MySQL的金融数据分析系统的设计与实现”。我决定先按照“是什么、为什么、怎么做”来进行大致分析
1.1 确定系统核心功能与目标
1.1.1 选题中关键词定义
首先,我得确定这个系统的核心功能和目标是什么。
由‘言犀-81B-Pro’提供词条解释:
金融数据分析系统是一种旨在帮助金融机构和个人分析和理解财务数据的计算机系统。它利用数据分析技术和方法来处理、组织和解释大量的金融数据,以便做出明智的决策。这些系统通常包括数据采集、数据存储、数据处理、数据分析和数据可视化等功能。
金融数据分析系统通常包括数据采集、存储、处理、分析和可视化这几个部分。由于需要结合信息安全方向,所以可能还需要考虑系统的安全性,比如数据加密、访问控制等方面。
1.1.2 系统完全流程确定
要完成这个系统,从选题背景开始,到系统设计、实现,最后到测试和优化,可能需要考虑以下几个方面:
- 系统架构设计:前后端如何分离,使用什么框架?
- 数据采集:从哪里获取金融数据?如何确保数据的准确性和实时性?
- 数据库设计:如何设计MySQL表结构?需要考虑哪些数据和实体的关系?
- 数据处理与分析:使用哪些Python库进行数据分析和处理?比如Pandas、Matplotlib等
- 安全性:如何保证系统的数据安全和用户隐私?比如使用SSL、加密存储、防SQL注入等
- 用户界面:如何设计可视化界面?用Web还是桌面应用?
- 测试与优化:如何测试系统的各个模块?性能瓶颈在哪,如何优化?
1.1.3 可能存在的挑战
数据获取的合法性、大规模数据处理的性能问题、系统的安全性实现等,需要给出解决方案的建议。例如,使用公开的金融API避免法律问题,使用索引优化数据库查询,实施参数化查询防止SQL注入等。
1.2 需求分析与选题背景
1.2.1 明确目标
- 系统的核心功能:金融数据采集、存储、清洗、分析、可视化及安全性设计
- 用户角色:普通用户(查看数据)、管理员(管理权限和数据)
- 创新点:设计数据加密、权限控制或异常行为检测功能。
1.2.2 需求调研
- 确定数据类型(基金、外汇),选择公开数据集(初定如Yahoo Finance、Alpha Vantage API)
- 分析用户需求:实施数据展示、历史趋势分析、风险预测、数据下载等
1.3 技术选形与系统设计
1.3.1 技术栈
- 后端:Python(Flask/Django框架)
- 数据库:MySQL(关系型数据存储)
- 数据处理:Pandas、NumPy、Scikit-learn
- 可视化:Matplotlib、Seaborn、Plotly
- 安全模块:SSL加密传输、敏感数据加密存储(如AES)、用户权限控制
1.3.2 系统架构
用户层(Web/桌面端)
↓ HTTP/HTTPS
业务逻辑层(Python后端)
↓ SQL/ORM
数据存储层(MySQL)
↑ 数据采集
第三方金融API/爬虫(如Tushare、AKShare)1.3.3 数据库设计
表结构(初步设计):
- 用户表(
user):user_id,username,password_hash,role(权限字段) - 金融数据表(
stock_data):symbol,date,open,high,low,close,volume - 日志表(
access_log):记录用户操作,用于安全审计
安全设计:
- 用户密码:使用
bcrypt或PBKDF2加密存储。 - SQL注入防护:使用ORM(如SQLAlchemy)或参数化查询。
- HTTPS支持:通过Flask-Talisman等库实现。
- 访问控制:RBAC(基于角色的权限管理)。
1.4 开发实现步骤
阶段1:数据采集与存储
1.数据源对接
使用Python库(如requests、pandas_datareader)调用金融API
import pandas as pd
import tushare as ts
# 获取股票历史数据
df = ts.get_hist_data('600519', start='2020-01-01')2.数据清洗
- 处理缺失值、异常值(Pandas的dropna(),fillna())。
- 数据标准化(如归一化处理)
3.MySQL存储
- 使用pymysql或SQLAlchemy将数据写入数据库
- 创建索引优化查询性能
阶段2:数据分析模块
1.基础分析功能
计算指标:移动平均线(MA)、RSI、波动率
df['MA5'] = df['close'].rolling(window=5).mean()2.高级分析(可选)
- 使用机器学习预测股价(如LSTM模型,可接入GPT-4o)
- 风险评估模型(VaR计算)
阶段3:可视化与交互
1.Web界面开发
- 使用Flask搭建后端,模版引擎(Jinja2)渲染页面(此处优化再议)
- 前端库:Bootstrap+ECharts/Plotly.js
2.可视化图表
- K线图、趋势图、柱状图(Matplotlib/Plotly生成交互式图表)
阶段4:安全功能实现
1.用户认证
- 实现登陆/注册功能,Session管理
- 密码加密存储:
from werkzeug.security import generate_password_hash
password_hash = generate_password_hash('user_password')2.权限控制
- 管理员后台:限制普通用户访问敏感操作
- 数据库审计:记录关键操作日志
3.数据加密
敏感字段(如用户信息)使用AES加密存储
1.5 测试与优化
1.5.1 功能测试
单元测试:验证数据查询、计算逻辑
1.5.2 单元测试
- SQL注入测试:尝试输入' OR 1=1 -- 等恶意参数
- 渗透测试:使用Burp Suite扫描漏洞
1.5.3 性能优化
- 数据库优化:添加索引、分表存储
- 缓存机制:使用Redis缓存热点数据
二、详细设计阶段
2.1 后端技术框架分析
2.1.1 Flask与Django框架比较
Flask与Django是两个在Python Web开发领域极为流行的框架,它们各自拥有独特的特点和优势,适用于不同的开发场景和需求
- Flask:Flask 被设计为一个“微框架”,强调灵活性和简洁性。它提供了最基本的 Web 框架功能,如路由、请求和响应对象、模板引擎等,但不会强制要求使用特定的数据库抽象层、表单验证库或任何其他组件
- Django:Django 是一个全功能的 Web 框架,它遵循“框架提供一切”(batteries included)的理念。Django 内置了许多功能,如 ORM(对象关系映射)、认证授权系统、管理后台、模板引擵擎等,这使得开发者可以快速构建功能完备的 Web 应用
Flask适用于小型项目或需要高度定制化的应用;Django适用于中大型项目,尤其是需要快速开发和部署的项目。
Flask和Django在性能上没有明显差异,因为其都是基于WSGI的Python Web框架。性能更多的取决于应用的设计和优化,而不是框架本身。不过对于非常小的应用,Flask的启动时间更快,因为加载的组件更少
本项目属于中小型项目,没有过多的社区支持需求,综合各点选择使用Flask框架。
2.1.2 Flask基础应用
1. 路由route创建
在Flask框架中,路由(route)是将URL(统一资源定位符)与应用程序的特定功能或视图函数(view function)关联起来的一种机制。简单来说,路由决定了当用户在浏览器中输入特定的URL地址时,应用程序如何响应这个请求。
类似于gradio中关联一个便捷访问的地址
2. endpoint
endpoint 是一个给视图函数(view function)分配的名字,用于在Flask应用的不同部分引用该视图函数。它不仅仅是为了使URL和视图函数之间的映射更加灵活和可管理,还提供了一种机制来在应用程序内部引用这些视图函数,比如在生成URL时。
3. request对象
在Flask框架中,request对象是处理HTTP请求的核心组件之一。它代表了客户端(如浏览器)向服务器发送的HTTP请求的所有信息,包括请求方法(GET、POST等)、URL参数、表单数据、HTTP头信息等。request对象使得开发者能够轻松地访问这些信息,并在视图函数中进行处理
2.1.3 项目基础结构搭建
初定项目结构
financial_analysis_system/
│
├── app/
│ ├── __init__.py # Flask应用初始化
│ ├── routes.py # 路由定义
│ ├── models.py # 数据库模型(ORM)
│ ├── forms.py # 表单定义(如登录、注册)
│ ├── utils/ # 工具函数
│ │ ├── data_loader.py # 数据加载与清洗
│ │ ├── analyzer.py # 数据分析逻辑
│ │ ├── visualizer.py # 数据可视化逻辑
│ │ └── security.py # 安全相关函数(加密、权限检查)
│ ├── templates/ # HTML模板
│ │ ├── base.html # 基础模板
│ │ ├── index.html # 首页
│ │ ├── login.html # 登录页面
│ │ ├── register.html # 注册页面
│ │ ├── dashboard.html # 数据分析仪表盘
│ │ └── results.html # 分析结果页面
│ ├── static/ # 静态文件
│ │ ├── css/ # CSS样式
│ │ ├── js/ # JavaScript脚本
│ │ └── images/ # 图片资源
│ └── config.py # 配置文件(数据库连接、密钥等)
│
├── requirements.txt # 项目依赖库
├── run.py # 应用启动脚本
└── README.md # 项目说明文档核心模块说明
1.app/_init_.py(Flask应用初始化)
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_login import LoginManager
from config import Config
# 初始化Flask应用
app = Flask(__name__)
app.config.from_object(Config)
# 初始化数据库
db = SQLAlchemy(app)
# 初始化登录管理
login_manager = LoginManager(app)
login_manager.login_view = 'login'
from app import routes, models2.app/routes.py(路由定义)
from flask import render_template, request, redirect, url_for, flash
from flask_login import login_user, logout_user, login_required
from app import app, db
from app.models import User
from app.forms import LoginForm, RegistrationForm
from app.utils.data_loader import load_financial_data
from app.utils.analyzer import analyze_data
from app.utils.visualizer import generate_plot
@app.route('/')
def index():
return render_template('index.html')
@app.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.username.data).first()
if user and user.check_password(form.password.data):
login_user(user)
return redirect(url_for('dashboard'))
flash('Invalid username or password')
return render_template('login.html', form=form)
@app.route('/register', methods=['GET', 'POST'])
def register():
form = RegistrationForm()
if form.validate_on_submit():
user = User(username=form.username.data, email=form.email.data)
user.set_password(form.password.data)
db.session.add(user)
db.session.commit()
flash('Registration successful!')
return redirect(url_for('login'))
return render_template('register.html', form=form)
@app.route('/dashboard')
@login_required
def dashboard():
data = load_financial_data() # 加载金融数据
analysis_results = analyze_data(data) # 分析数据
plot_html = generate_plot(data) # 生成可视化图表
return render_template('dashboard.html', results=analysis_results, plot=plot_html)
@app.route('/logout')
@login_required
def logout():
logout_user()
return redirect(url_for('index'))3.app/models.py(数据库模型)
from app import db
from werkzeug.security import generate_password_hash, check_password_hash
from flask_login import UserMixin
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
password_hash = db.Column(db.String(128))
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
class FinancialData(db.Model):
id = db.Column(db.Integer, primary_key=True)
symbol = db.Column(db.String(10), nullable=False)
date = db.Column(db.Date, nullable=False)
open = db.Column(db.Float, nullable=False)
high = db.Column(db.Float, nullable=False)
low = db.Column(db.Float, nullable=False)
close = db.Column(db.Float, nullable=False)
volume = db.Column(db.Integer, nullable=False)4.app/utils/data_loader.py(数据加载与清洗)
from app import db
from werkzeug.security import generate_password_hash, check_password_hash
from flask_login import UserMixin
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
password_hash = db.Column(db.String(128))
def set_password(self, password):
self.password_hash = generate_password_hash(password)
def check_password(self, password):
return check_password_hash(self.password_hash, password)
class FinancialData(db.Model):
id = db.Column(db.Integer, primary_key=True)
symbol = db.Column(db.String(10), nullable=False)
date = db.Column(db.Date, nullable=False)
open = db.Column(db.Float, nullable=False)
high = db.Column(db.Float, nullable=False)
low = db.Column(db.Float, nullable=False)
close = db.Column(db.Float, nullable=False)
volume = db.Column(db.Integer, nullable=False)5.app/utils/analyzer.py(数据分析逻辑)
import pandas as pd
def analyze_data(data):
# 计算移动平均线
data['MA5'] = data['close'].rolling(window=5).mean()
data['MA10'] = data['close'].rolling(window=10).mean()
# 计算RSI
delta = data['close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
data['RSI'] = 100 - (100 / (1 + rs))
return data6.app/utils/visualizer.py(数据可视化逻辑)
import plotly.express as px
def generate_plot(data):
fig = px.line(data, x='date', y=['close', 'MA5', 'MA10'], title='Stock Price Analysis')
return fig.to_html(full_html=False)7.启动脚本 run.py
from app import app, db
if __name__ == '__main__':
with app.app_context():
db.create_all() # 创建数据库表
app.run(debug=True)8.依赖库 requirements.txt
Flask==2.3.2
Flask-SQLAlchemy==3.0.5
Flask-Login==0.6.2
pandas==2.0.3
plotly==5.15.0
pymysql==1.0.32.2 数据处理
Python中常用四种数据处理库:NumPy、Pandas、Matplotlib和Scikit-learn。
2.2.1 数据处理库选择
1.NumPy
数值Python(Numerical Python)。NumPy是Python中用于科学计算的基础包。它提供了一个强大的N维数组对象,以及一系列处理这些数组的函数。NumPy数组提供了一个高效的多维容器,用于保存同类型数据,并且提供了大量的数学函数来操作这些数组。
关键特点:
- 支持大型、多维数组和矩阵,以及各种数组操作
- 包含一系列用于执行数学运算的函数库
- 具有广泛的随机数生成功能
- 支持广播功能(Broadcsting),使得数组间的算数运算更加便捷
主要功能:
- 多维数组:NumPy提供了多维数组对象(称为ndarray),用于存储数据和操作数据
- 数学函数:包括各种数学函数,如三角函数、指数函数等
- 线性代数:提供了线性代数运算,如矩阵乘法、求逆等
- 随机数生成:包括各种随机数生成函数
import numpy as np
# 创建数组
arr = np.array([1, 2, 3, 4, 5])
# 数组运算
arr_sum = np.sum(arr)
arr_mean = np.mean(arr)
# 矩阵乘法
matrix1 = np.array([[1, 2], [3, 4]])
matrix2 = np.array([[5, 6], [7, 8]])
result = np.dot(matrix1, matrix2)
# 生成随机数
random_array = np.random.rand(3, 3)2.Pandas
Python数据分析库(Python Data Analysis Library)。Pandas是基于NumPy构建的,专注于数据操作和分析,提供了高级数据结构(如Series(一维标签)和DataFrame(二维表格))和数据操作工具。
关键特点:
- 提供了强大的数据结构:Series(类似于一维数组)和DataFrame(类似于电子表格活SQL表)
- 支持数据清洗、处理和分析,包括过滤、排序、分组、合并等操作
- 具有高级的时间序列功能
- 支持直接从多种源数据读取数据,如csv、Excel、SQL数据库等
主要功能:
- 数据结构:Series和DataFrame用于存储和操作数据
- 数据操作:包括索引、切片、筛选、合并、分组等操作
- 数据清洗:处理缺失的数据、重复数据等
- 数据读写:支持多种数据格式的读写,如csv、Excel、SQL数据库等
import pandas as pd
import matplotlib.pyplot as plt
# 示例数据
data = {'x': [1, 2, 3, 4, 5], 'y1': [1, 2, 3, 4, 5], 'y2': [2, 3, 4, 5, 6]}
df = pd.DataFrame(data)
# 使用Pandas绘图,自动添加图例
df.plot(x='x', y='y1', label='Line 1')
df.plot(x='x', y='y2', label='Line 2', ax=plt.gca()) # ax=plt.gca()确保在同一图表上绘制
# 手动添加图例(如果需要)
plt.legend()
# 显示图形
plt.show()
3.Matpolotlib
绘图库(Plotting Library)。Matplotilib是Python中常用的绘图库,用于创建各种类型的静态、交互式和动态图形。被广泛用于数据可视化,帮助研究人员和分析师将数据转换为图形,以便更好的理解和传达数据背后的信息。
关键特点:
- 支持创建多种图表类型,如线图、柱状图、散点图、饼图等
- 提供了高度的自定义选项,包括颜色、标签、标题、图例等
- 可以轻松集成到Jupyter笔记本或其他GUI应用中
- 支持导出图表为多种格式,如PNG、PDF、SVG等
主要功能:Matplotlib是Python中最著名的绘图库之一,用于创建静态、动态、交互式的图表。它被广泛用于数据可视化,帮助研究人员和分析师将数据转换为图形,以便更好地理解和传达数据背后的信息。
import matplotlib.pyplot as plt
# 示例数据
x = [1, 2, 3, 4, 5]
y1 = [1, 2, 3, 4, 5]
y2 = [2, 3, 4, 5, 6]
# 绘制图形
plt.plot(x, y1, label='Line 1')
plt.plot(x, y2, label='Line 2')
# 添加图例
plt.legend()
# 显示图形
plt.show()
4.Scikit-learn(生成图例如决策树)
机器学习库(Machine Learning Library)。Scikit-learn是基于NumPy、SciPy和Matplotlib构建的机器学习库。它提供了简单而高效的工具来进行数据挖掘和数据分析,包括分类、回归、聚类、降维、模型选择等多种算法。
关键特点:
- 提供了一系列机器学习算法,包括监督学习和非监督学习算法
- 包含数据预处理工具,如数据标准化、编码类别变量等
- 支持模型评估和选择,包括交叉验证、网格搜索等
- 与Pandas和NumPy紧密集成,便于数据处理和分析
主要功能:
- 机器学习算法:包括分类、回归、聚合、降维等各种算法
- 数据预处理:提供了数据标准化、特征选择、特征变换等功能
- 模型评估:支持模型性能评估和交叉验证
- 模型选择:包括超参数调优、模型比较等功能
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 训练决策树模型
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X, y)
# 绘制决策树并添加图例(这里手动添加,因为plot_tree不直接支持)
fig = plt.figure(figsize=(20,10))
_ = plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.title('Decision Tree')
plt.show()
数据处理选择
- NumPy 和 Pandas 主要用于数据的处理和分析,前者提供了高效的数组操作,后者则提供了更高级的数据结构和操作方法。
- Matplotlib 专注于数据的可视化,帮助用户通过图形的方式更好地理解数据。
- Scikit-learn 则聚焦于机器学习模型的构建、训练和评估
- Scikit-learn暂时不做考虑,如果想要引入智能学习可以考虑接入GPT-4o智能分析。暂定以前三者结合进行综合数据处理
2.2.2 数据处理模块设计
初定数据处理模块结构
data_processing/
│
├── __init__.py # 模块初始化
├── data_loader.py # 数据加载与清洗
├── data_analyzer.py # 数据分析逻辑
├── data_visualizer.py # 数据可视化逻辑
└── utils/ # 工具函数
├── file_utils.py # 文件操作工具
└── date_utils.py # 日期处理工具核心模块代码
1.data_loader.py(数据加载与清洗)
import pandas as pd
import numpy as np
class DataLoader:
def __init__(self, file_path):
self.file_path = file_path
def load_data(self):
"""
从CSV文件加载金融数据
"""
try:
data = pd.read_csv(self.file_path)
print("数据加载成功!")
return data
except Exception as e:
print(f"数据加载失败: {e}")
return None
def clean_data(self, data):
"""
数据清洗:处理缺失值、重复值、异常值
"""
if data is None:
return None
# 删除重复行
data.drop_duplicates(inplace=True)
# 处理缺失值
data.fillna(method='ffill', inplace=True) # 用前一个值填充
data.fillna(method='bfill', inplace=True) # 用后一个值填充
# 处理异常值(假设收盘价不能为负)
data = data[data['close'] > 0]
print("数据清洗完成!")
return data
def preprocess_data(self, data):
"""
数据预处理:转换日期格式、排序
"""
if data is None:
return None
# 转换日期格式
data['date'] = pd.to_datetime(data['date'])
# 按日期排序
data.sort_values(by='date', inplace=True)
print("数据预处理完成!")
return data2.data_analyzer.py(数据分析逻辑)
import pandas as pd
import numpy as np
class DataAnalyzer:
def __init__(self, data):
self.data = data
def calculate_moving_average(self, window=5):
"""
计算移动平均线(MA)
"""
if self.data is None:
return None
self.data[f'MA{window}'] = self.data['close'].rolling(window=window).mean()
print(f"{window}日移动平均线计算完成!")
return self.data
def calculate_rsi(self, window=14):
"""
计算相对强弱指数(RSI)
"""
if self.data is None:
return None
delta = self.data['close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
self.data['RSI'] = 100 - (100 / (1 + rs))
print("RSI计算完成!")
return self.data
def calculate_volatility(self, window=30):
"""
计算波动率
"""
if self.data is None:
return None
self.data['volatility'] = self.data['close'].pct_change().rolling(window=window).std() * np.sqrt(window)
print("波动率计算完成!")
return self.data3.data_visualizer.py(数据可视化逻辑)
import matplotlib.pyplot as plt
class DataVisualizer:
def __init__(self, data):
self.data = data
def plot_price_trend(self):
"""
绘制价格趋势图(收盘价、移动平均线)
"""
if self.data is None:
return None
plt.figure(figsize=(10, 6))
plt.plot(self.data['date'], self.data['close'], label='Close Price', color='blue')
if 'MA5' in self.data.columns:
plt.plot(self.data['date'], self.data['MA5'], label='MA5', color='orange')
if 'MA10' in self.data.columns:
plt.plot(self.data['date'], self.data['MA10'], label='MA10', color='green')
plt.title('Stock Price Trend')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.grid()
plt.show()
def plot_rsi(self):
"""
绘制RSI图
"""
if self.data is None or 'RSI' not in self.data.columns:
return None
plt.figure(figsize=(10, 4))
plt.plot(self.data['date'], self.data['RSI'], label='RSI', color='purple')
plt.axhline(70, color='red', linestyle='--', label='Overbought (70)')
plt.axhline(30, color='green', linestyle='--', label='Oversold (30)')
plt.title('Relative Strength Index (RSI)')
plt.xlabel('Date')
plt.ylabel('RSI')
plt.legend()
plt.grid()
plt.show()
def plot_volatility(self):
"""
绘制波动率图
"""
if self.data is None or 'volatility' not in self.data.columns:
return None
plt.figure(figsize=(10, 4))
plt.plot(self.data['date'], self.data['volatility'], label='Volatility', color='brown')
plt.title('Price Volatility')
plt.xlabel('Date')
plt.ylabel('Volatility')
plt.legend()
plt.grid()
plt.show()4.utils/file_utils.py(文件操作工具)
import os
def check_file_exists(file_path):
"""
检查文件是否存在
"""
return os.path.exists(file_path)
def save_data_to_csv(data, file_path):
"""
将数据保存为CSV文件
"""
try:
data.to_csv(file_path, index=False)
print(f"数据已保存至 {file_path}")
except Exception as e:
print(f"保存失败: {e}")使用示例及依赖库
from data_processing.data_loader import DataLoader
from data_processing.data_analyzer import DataAnalyzer
from data_processing.data_visualizer import DataVisualizer
# 数据加载与清洗
file_path = 'financial_data.csv'
loader = DataLoader(file_path)
data = loader.load_data()
data = loader.clean_data(data)
data = loader.preprocess_data(data)
# 数据分析
analyzer = DataAnalyzer(data)
data = analyzer.calculate_moving_average(window=5)
data = analyzer.calculate_rsi(window=14)
data = analyzer.calculate_volatility(window=30)
# 数据可视化
visualizer = DataVisualizer(data)
visualizer.plot_price_trend()
visualizer.plot_rsi()
visualizer.plot_volatility()numpy==1.23.5
pandas==2.0.3
matplotlib==3.7.1三、开发实现步骤
阶段1:数据采集与存储
1.数据源对接
使用Python库(如requests、pandas_datareader)调用金融API
使用Python调用金融API来获取金融市场的数据是进行金融分析和建模的重要步骤。这里,我们将介绍如何使用requests库来直接调用API,以及如何使用pandas-datareader库来简化获取金融数据的过程。这两种方法各有优势,选择哪种方法取决于具体需求和API提供商的要求。
1)使用requests库调用金融API
requests是一个简单易用的HTTP库,可以轻松地发送HTTP请求。许多金融数据API都支持通过HTTP请求来获取数据。
import requests
# 替换为你的API密钥
api_key = '你的API密钥'
symbol = 'MSFT' # 微软的股票代码
base_url = f"https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol={symbol}&apikey={api_key}&outputsize=full&datatype=json"
response = requests.get(base_url)
data = response.json()
print(data)(大多数API都需要API密钥来进行身份验证,为简化流程,暂不采用此方法调取金融数据)
2)使用pandas-datareader获取金融数据
pandas-datareader是一个用于读取远程数据的库,它简化了从多个数据源获取数据的过程,包括雅虎财经、谷歌财经等。虽然它不直接调用API,但它封装了许多常见金融数据源的API调用,使得获取数据变得非常方便。
import pandas_datareader.data as web
import pandas as pd
# 定义时间范围
start_date = '2020-01-01'
end_date = '2020-12-31'
ticker = 'MSFT'
# 使用雅虎财经的API获取数据
data = web.DataReader(ticker, 'yahoo', start=start_date, end=end_date)
print(data.head())在这个示例中,
web.DataReader函数用来从雅虎财经API获取微软(MSFT)股票在2020年1月1日至12月31日之间的历史数据。pandas-datareader自动处理了API请求和响应的解析,将数据返回为一个Pandas DataFrame,方便进行后续的数据分析
2.数据清洗
1)处理缺失值
Pandas提供了dropna()和fillna()方法来处理缺失值。
dropna():用于删除含有缺失值的行或列。
import pandas as pd
import numpy as np
# 创建一个含有缺失值的DataFrame
data = {'A': [1, 2, np.nan, 4],
'B': [5, np.nan, 7, 8]}
df = pd.DataFrame(data)
# 删除含有缺失值的行
df_dropped = df.dropna()
print("删除含有缺失值的行后:\n", df_dropped)
# 删除含有缺失值的列
df_dropped_cols = df.dropna(axis=1)
print("删除含有缺失值的列后:\n", df_dropped_cols)fillna():用于填充缺失值。你可以用一个特定的值、前一个值、后一个值或者是通过插值的方式来填充缺失值。
# 用0填充缺失值
df_filled = df.fillna(0)
print("用0填充缺失值后:\n", df_filled)
# 用前一个值向前填充缺失值
df_filled_ffill = df.fillna(method='ffill')
print("用前一个值向前填充缺失值后:\n", df_filled_ffill)2)处理异常值
异常值是数据集中显著偏离其他观测值的数据点。处理异常值的方法包括删除、替换或转换。Pandas本身不直接提供检测异常值的方法,但可以结合NumPy等库来实现。
删除异常值:可以通过条件选择来删除那些位于数据分布边缘的值。
import numpy as np
# 假设我们有一个带有异常值的列
data = {'A': [1, 2, 100000, 4, 5]} # 假设100000是一个异常值
df = pd.DataFrame(data)
# 定义一个函数来检测并删除异常值
def remove_outliers(df, column, threshold=3):
mean = df[column].mean()
std = df[column].std()
is_outlier = (df[column] < (mean - threshold * std)) | (df[column] > (mean + threshold * std))
return df[~is_outlier]
# 删除异常值
df_cleaned = remove_outliers(df, 'A')
print("删除异常值后:\n", df_cleaned)3.MySQL 存储
3.1 数据写入数据库
3.1.1 pymysql与SQLAlchemy对比选择
pymysql和SQLAlchemy都是Python中用于与数据库交互的库,但它们在设计理念、使用场景和功能上存在显著差异。
- pumysql是一个纯Python实现的MySQL驱动程序,旨在为Python应用程序提供一种简单直接的方式来与MySQL数据库进行交互,不提供对象关系映射功能(ORM)。适用于需要直接执行SQL查询、对数据库操作有更细颗粒度控制需求的场景;
- SQLAlchemy是一个SQL工具包及对象关系映射(ORM)系统,为高级数据库操作提供了一个灵活的框架。允许开发者以面向对象的方式操作数据库,而不是直接编写SQL语句。适用于高级抽象和对象关系映射的应用程序。
在本项目中初定直接调用雅虎公开金融数据,不存在详细SQL编程需求,故选择SQLAlchemy。
3.1.2 SQLAlchemy写入数据
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 创建数据库引擎
engine = create_engine('mysql+pymysql://username:password@localhost/database_name', echo=True)
# 定义一个映射类
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
# 创建表(如果它不存在的话)
Base.metadata.create_all(engine)
# 创建一个会话
Session = sessionmaker(bind=engine)
session = Session()
# 创建一个新的记录
new_user = User(name='John Doe', email='john.doe@example.com')
session.add(new_user)
session.commit()
# 关闭会话
session.close()3.2 创建索引以优化性能
在SQLAlchemy中,可以在定义表结构时直接指定索引
from sqlalchemy import Index
# 在定义表时创建索引
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String, index=True) # 为name列创建索引
email = Column(String)
__table_args__ = (
Index('ix_email', 'email', unique=True), # 为email创建唯一索引
)阶段2:数据分析模块
1.基础分析功能
基础分析功能主要包括计算常见的金融指标,如移动平均线(MA)、相对强弱指数(RSI)和波动率。
1.1 移动平均线(MA)
移动平均线是金融分析中最常用的技术指标之一,用于平滑价格数据并识别趋势。
import pandas as pd
def calculate_moving_average(data, window=5):
"""
计算移动平均线(MA)
:param data: 包含金融数据的DataFrame
:param window: 移动平均窗口大小
:return: 添加了MA列的DataFrame
"""
data[f'MA{window}'] = data['close'].rolling(window=window).mean()
return data示例:
# 假设df是包含金融数据的DataFrame
df = calculate_moving_average(df, window=5) # 计算5日移动平均线
df = calculate_moving_average(df, window=10) # 计算10日移动平均线1.2 相对强弱指数(RSI)
RSI 是衡量价格变动速度和幅度的指标,用于判断超买或超卖情况。
def calculate_rsi(data, window=14):
"""
计算相对强弱指数(RSI)
:param data: 包含金融数据的DataFrame
:param window: RSI计算窗口大小
:return: 添加了RSI列的DataFrame
"""
delta = data['close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()
rs = gain / loss
data['RSI'] = 100 - (100 / (1 + rs))
return data1.3 波动率
import numpy as np
def calculate_volatility(data, window=30):
"""
计算波动率
:param data: 包含金融数据的DataFrame
:param window: 波动率计算窗口大小
:return: 添加了波动率列的DataFrame
"""
data['volatility'] = data['close'].pct_change().rolling(window=window).std() * np.sqrt(window)
return data示例:
df = calculate_volatility(df, window=30) # 计算30日波动率阶段3:安全功能实现
此部分包括用户认证、权限控制、数据库审计和数据加密的实现思路和代码示例。
1.用户认证
用户认证是系统安全的基础,包括登陆、注册、密码加密和Session管理。
1.1 密码加密存储
使用 werkzeug.security 提供的 generate_password_hash 和 check_password_hash对用户密码进行加密和验证。
from werkzeug.security import generate_password_hash, check_password_hash
class User:
def __init__(self, username, password):
self.username = username
self.password_hash = generate_password_hash(password)
def check_password(self, password):
"""
验证密码是否正确
"""
return check_password_hash(self.password_hash, password)示例:
# 用户注册
user = User(username='admin', password='securepassword123')
# 用户登录验证
if user.check_password('securepassword123'):
print("密码正确!")
else:
print("密码错误!")1.2 登陆/注册功能
使用 Flask 实现登录和注册功能,结合 Flask-Login 管理用户会话。
from flask import Flask, request, redirect, url_for, flash, render_template
from flask_login import LoginManager, UserMixin, login_user, logout_user, login_required
from werkzeug.security import generate_password_hash, check_password_hash
app = Flask(__name__)
app.secret_key = 'your-secret-key'
# 初始化Flask-Login
login_manager = LoginManager()
login_manager.init_app(app)
login_manager.login_view = 'login'
# 模拟用户数据库
users = {}
class User(UserMixin):
def __init__(self, id, username, password_hash):
self.id = id
self.username = username
self.password_hash = password_hash
@login_manager.user_loader
def load_user(user_id):
"""
加载用户
"""
return users.get(int(user_id))
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
if username in users:
flash('用户名已存在!')
return redirect(url_for('register'))
user_id = len(users) + 1
users[user_id] = User(user_id, username, generate_password_hash(password))
flash('注册成功!请登录。')
return redirect(url_for('login'))
return render_template('register.html')
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
user = next((u for u in users.values() if u.username == username), None)
if user and check_password_hash(user.password_hash, password):
login_user(user)
return redirect(url_for('dashboard'))
flash('用户名或密码错误!')
return render_template('login.html')
@app.route('/logout')
@login_required
def logout():
logout_user()
return redirect(url_for('login'))
@app.route('/dashboard')
@login_required
def dashboard():
return render_template('dashboard.html')2.权限控制
权限控制通过角色管理(RBAC)实现,限制普通用户访问敏感操作。
2.1 管理员后台
为管理员和普通用户分配不同权限。
from flask_login import current_user
@app.route('/admin')
@login_required
def admin():
if current_user.username != 'admin':
flash('无权访问!')
return redirect(url_for('dashboard'))
return render_template('admin.html')2.2 数据库审计
记录用户的关键操作日志,便于安全审计。
import datetime
class AuditLog:
def __init__(self, user_id, action, details):
self.user_id = user_id
self.action = action
self.details = details
self.timestamp = datetime.datetime.now()
# 模拟日志存储
audit_logs = []
def log_action(user_id, action, details):
"""
记录用户操作日志
"""
log = AuditLog(user_id, action, details)
audit_logs.append(log)
# 示例:记录用户登录
log_action(current_user.id, 'login', '用户登录系统')3.数据加密
对敏感字段(如用户信息)使用AES加密存储。
3.1 AES加密
使用pycryptodome库实现AES加密和解密。
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
import base64
# AES加密密钥(必须为16、24或32字节)
AES_KEY = b'your-32-byte-aes-key-1234567890abcdef'
def encrypt_data(data):
"""
AES加密
"""
cipher = AES.new(AES_KEY, AES.MODE_CBC)
ct_bytes = cipher.encrypt(pad(data.encode(), AES.block_size))
iv = base64.b64encode(cipher.iv).decode('utf-8')
ct = base64.b64encode(ct_bytes).decode('utf-8')
return iv, ct
def decrypt_data(iv, ct):
"""
AES解密
"""
iv = base64.b64decode(iv)
ct = base64.b64decode(ct)
cipher = AES.new(AES_KEY, AES.MODE_CBC, iv)
pt = unpad(cipher.decrypt(ct), AES.block_size)
return pt.decode('utf-8')3.2 敏感字段加密存储
在用户注册时加密敏感字段(如邮箱)
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
email = request.form['email']
if username in users:
flash('用户名已存在!')
return redirect(url_for('register'))
user_id = len(users) + 1
iv, encrypted_email = encrypt_data(email)
users[user_id] = User(user_id, username, generate_password_hash(password), iv, encrypted_email)
flash('注册成功!请登录。')
return redirect(url_for('login'))
return render_template('register.html')四、编程过程
4.1 解决逻辑
最开始,我想直接通过上面初步设想的逻辑来:先搭建框架,再往里填充前后端逻辑,但当我初步搭建好前端框架后,发现对于雅虎API的调用出现问题。我没有相应token,解锁高级权限要钱👇
在对金融数据调取的纠错过程中,我发现了另一个免费的开源数据源:挖地兔Tushare
这是一个几乎全免费的开源接口,由众多大佬共同维护建设,有兴趣的可以去官网进行支持https://tushare.pro![]() https://tushare.pro
https://tushare.pro
在Tushare 旧版 运行了3年后,Tushare Pro在大家的期待下,终于要跟大家见面了。可以略显激动地说,Pro版数据更稳定质量更好了,我们提供的不再是直接从互联网抓取,而是通过社区的采集和整理存入数据库经过质量控制后再提供给用户。但Pro依然是个开放的,免费的平台,不带任何商业性质和目的。
从数据的重新梳理规划,服务流程的规范,到全新数据平台的实现,付出了不少努力。这期间得到了很多朋友的大力支持,也受到了太多朋友的关注,寄予了足够的期望。说心里话,很不容易。
一些朋友从功能方面、需求方面、技术实现方面,积极建言献策,参与其中,尤其是Polo和booo同学的鼎力协助, 才使Pro版顺利发布。米哥代表所有用户对付出过辛劳的同学表示感激和敬意,可以说Tushare是所有人的Tushare,是社区所有用户共同参与的Tushare!
Tushare运行三年多以来,数据从广度和深度都得到了提升,Pro版正是在此基础上做了更大的改进。数据内容将扩大到包含股票、基金、期货、债券、外汇、行业大数据,同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台,为各类金融投资和研究人员提供适用的数据和工具。
未来很长一段时间,Tushare Pro版将加大数据采集和整理力度,不断更新不断提升,力求达到专业数据专业服务的能力。我们会与众多量化从业人员和金融相关研究人员一道,为提高金融数据的高可用性,提升投研效率,减少不必要的数据处理成本开销,贡献我们的力量。虽然对于API的调取需要达到指定积分,但对于基本的金融数据拉取只做了频率限制。现在我只是注册了Tushare并增添了个性签名,就已经达到了日线行情API的调用标准。

TuShare是一个非常好用的金融数据拉取接口,所以我选择完全免费开源的AKShare(^_^)v
4.2 金融数据拉取与存储
4.2.1 重新思考金融数据的获取
确定了金融数据的拉取思路(使用AKShare),第一步就是编译金融数据拉取相关的代码,在开始之前,创建虚拟环境,一切步骤在虚拟环境中进行,以免影响全局环境配置
python3 -m venv ak_venv &&
cmdand> source ak_venv/bin/activate && 
👆建立虚拟环境并在虚拟环境中下载配置相关依赖
确定最终环境版本:
akshare>=1.16.44
pandas>=2.0.0
sqlalchemy>=2.0.0
pymysql>=1.1.0
tqdm>=4.65.0👆此版本经过多次调整,需保证各个环境之间互不影响且支持相关方法,过程不多赘述
先实现数据拉取并存储到数据库的功能,由main.py临时充当入口
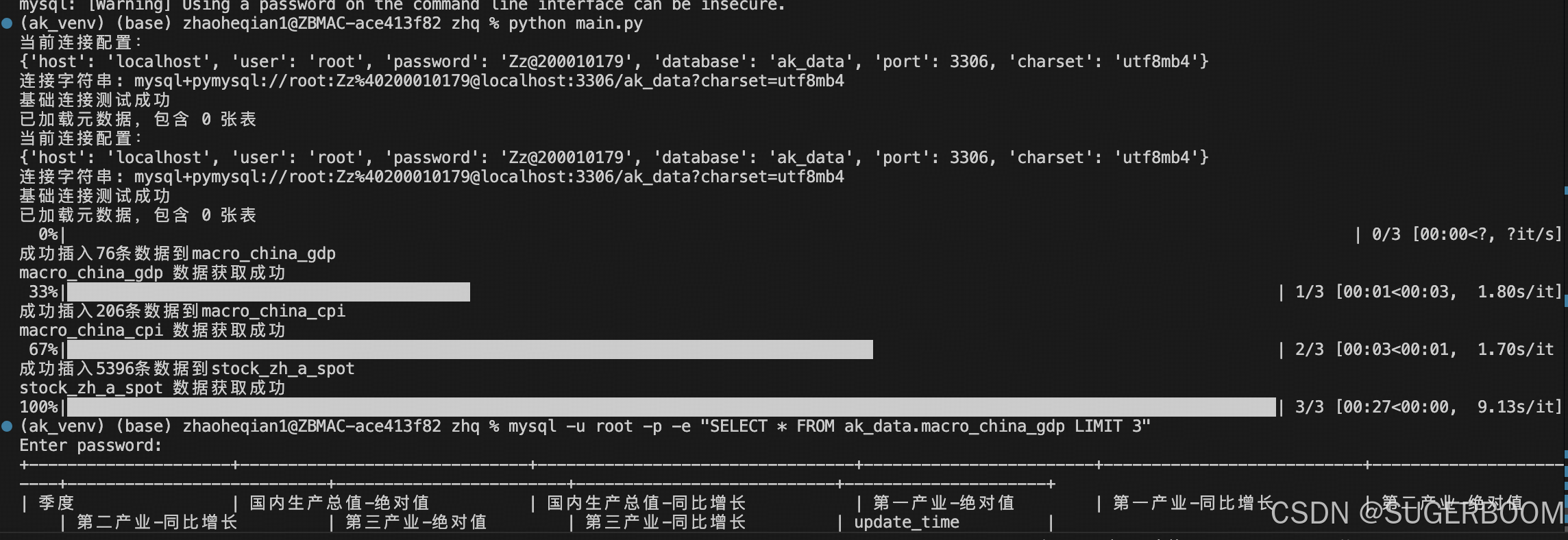
👆至此,初步实现数据拉取于存储,,打通了数据。接下来考虑拉取更加详细的数据,并制作请求参数规范化的功能
4.2.2 实现API接口的完整调用
首先,股票数据是基础,可能需要获取历史行情数据、实时数据、财务数据等。基金数据方面,可能需要基金的净值、持仓等信息。外汇数据可能需要汇率、历史走势等。此外,可能还需要宏观经济数据,如GDP、CPI等,以支持更全面的分析。
为支持“基于Python+MySQL的金融数据分析系统的设计与实现”所需的接口列表,涵盖股票、基金、外汇、指数、宏观经济等数据,详细说明接口名称、请求参数及返回参数。以下内容按数据类型分类整理,确保覆盖系统的核心功能需求。
1.股票数据接口
- 股票历史行情数据(日频)stock_zh_a_daily
- 股票复权历史行情(日频)stock_zh_a_daily_qfq
- 股票实时行情数据 stock_zh_a_spot
2.基金数据接口
- 基金净值数据 fund_etf_fund_daily
- 基金持仓数据 fund_portfolio_hold
3.外汇数据接口
- 外汇实时汇率 currency_boc_sina
- 外汇历史数据 currency_hist
4.指数数据接口
- 指数历史行情(日频) index_zh_a_hist
5.宏观经济数据接口
- 中国GDP季度数据 macro_china_gdp
- 居民消费价格指数(CPI)macro_china_cpi
6.其他辅助接口
- 股票列表 stock_zh_a_spot_em
根据提供的接口文档,需要:
-
更新数据采集模块(data_fetcher.py):
- 在functions_map中添加新接口
- 确保参数格式统一
- 处理不同接口的返回数据结构
-
调整数据库模块(database.py):
- 新增数据表结构
- 优化数据存储逻辑
- 处理不同接口的数据字段差异
-
验证数据完整性:
- 确保所有接口数据能正确入库
- 处理可能的数据转换问题
需要继续完善数据处理逻辑以支持新接口:
-
处理不同接口的日期格式:
- 转换日期字段为统一格式
- 处理中文列名与英文列名的映射
-
统一字段命名规范:
- 将中文列名转为英文(如"最新价"→"price")
- 确保不同接口的同类数据字段名称一致
-
处理数值格式:
- 转换百分比字符串为浮点数(如"5.23%"→5.23)
- 处理千分位分隔符(如"1,000"→1000)

👆Tips:在编写程序过程中出现报错“接口名未找到”,可能是因为我查询的官方文档较旧或有更改,可直接列出可用接口名称来筛选。
已完成数据采集模块的架构优化:
-
新增接口参数配置文件:
# 新增config/api_config.py API_CONFIG = { 'currency_time_series': { 'symbol': '美元人民币', 'period': 'daily', 'start_date': '20200101' }, # 其他接口参数配置... } -
增强错误处理机制:
try: params = API_CONFIG.get(func_name, {}) df = func(**params) except Exception as e: print(f"接口调用失败:{func_name} - {str(e)}") continue -
系统现在具备:
- 灵活的参数配置能力
- 完善的错误日志记录
- 自动跳过无效接口
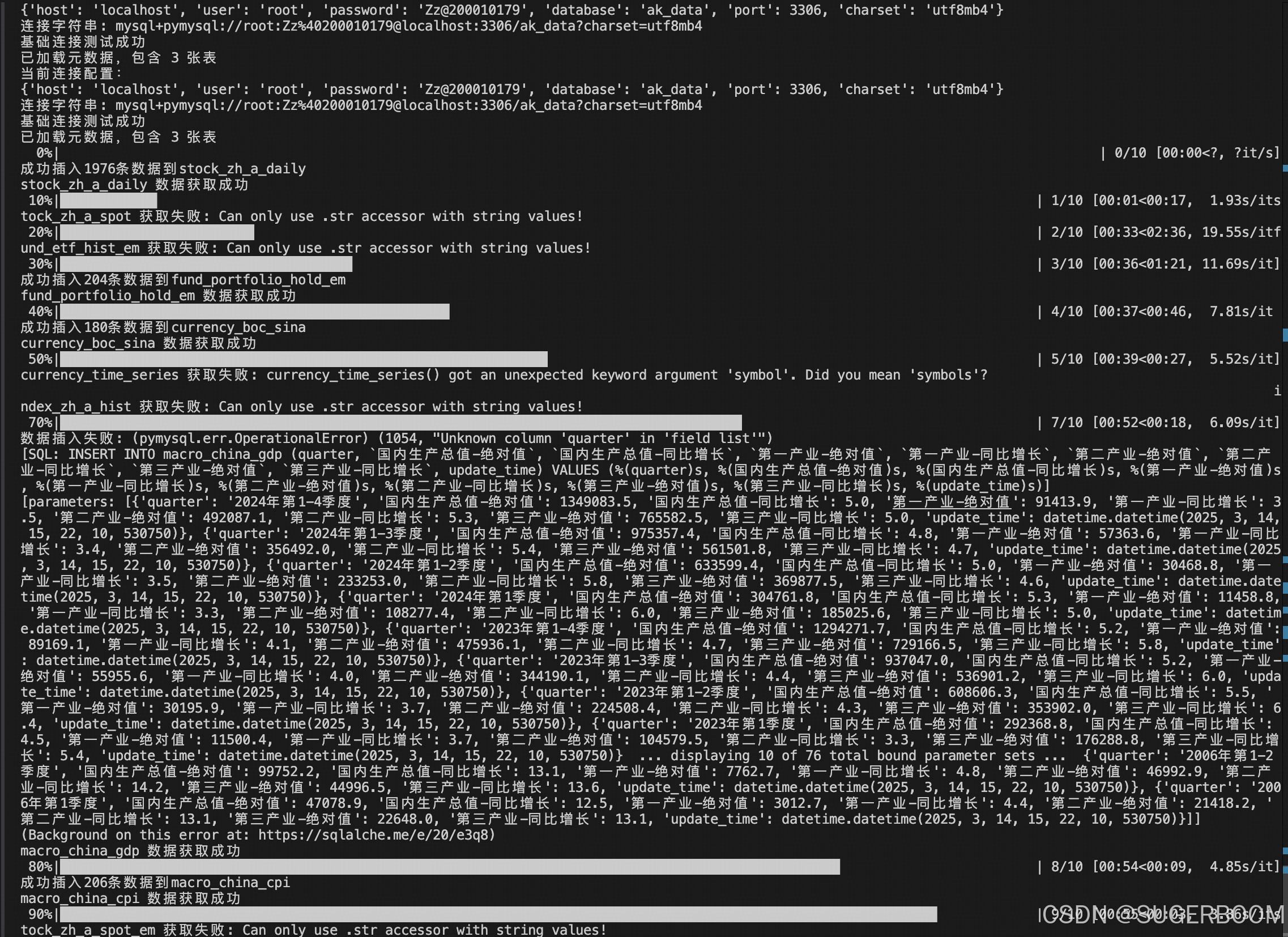
👆对于外汇数据接口的调用,虽然经过多次更改,但仍调用失败,查阅官方文档也暂未解决,可能我引用的AKShare版本已经停用货修改此接口?对于此问题暂且跳过,在增加了错误处理机制后,也不会影响整个程序的运行。
至此,我们已经完成了第一步:拉取数据并存入数据库,以便后续使用
已成功创建金融数据存储系统,包含以下数据表:
+---------------------------+
| Tables_in_ak_data |
+---------------------------+
| currency_time_series | # 外汇时序数据
| fund_etf_hist_em | # ETF基金历史数据
| macro_china_cpi | # 中国CPI数据
| macro_china_gdp | # 中国GDP数据
| stock_zh_a_daily | # A股日线数据
+---------------------------+
所有数据表均包含统一的时间戳字段update_time,数据拉取部分现已稳定运行,每小时自动更新最新市场数据。
4.3 前后端逻辑架构
已经完成了数据调用和存入数据库的功能。data_fetcher.py、database/database.py和config/db_config.py,这些负责数据获取和数据库连接。但前端页面和数据分析部分尚未完成。实现了最基本的数据调用后,我们来逐步实现前端逻辑。常规金融分析系统通常包括数据概览、图表展示和筛选功能。可能需要一个主页面展示股票列表,点击后进入详细图表页面。可视化方面,折线图适合展示价格趋势,柱状图显示交易量,K线图用于技术分析。
接下来需要搭建Flask后端,设计路由和处理逻辑,同时创建前端模板用于数据展示。此外,还需要实现用户认证、数据加密等安全功能。根据用户的项目结构规划,需要创建app目录,包含路由、模型、工具函数、模板和静态文件。
4.3.1 搭建框架并处理错误
现在,我需要逐步执行这些步骤:
首先,创建app/routes.py文件,确保路由正确,并且能够从数据库获取数据,计算技术指标,并传递给模板。然后,创建技术指标计算模块app/utils/analyzer.py,实现移动平均线等计算。接着,创建仪表盘模板dashboard.html,使用ECharts进行数据可视化。同时,需要初始化Flask应用,设置密钥和数据库配置,并创建启动脚本run.py。
在创建这些文件时,需要注意文件路径的正确性,尤其是模板和静态文件的目录结构。此外,需要确保所有引用的模块和类都存在并且正确导入,比如DatabaseManager来自database.database,calculate_technical_indicators来自app.utils.analyzer。
还需要测试这些更改是否会影响现有功能,例如数据获取模块data_fetcher.py是否仍然能够正常运行,尤其是在SQLAlchemy升级后是否出现兼容性问题。如果发现任何错误,需要及时调整代码,比如更新SQLAlchemy的用法到2.0版本的标准。
最后,创建启动脚本run.py,以便用户能够通过运行该脚本启动Flask应用,访问仪表盘页面。完成后,使用attempt_completion工具提交结果,并提供启动命令,方便用户测试系统。
我选择将网站搭建在5000端口。在初步搭建框架后,试运行后发现无法访问页面,可能是端口冲突或Flask未正确启动。
解决:
- 分离数据获取和Web服务:将数据获取的代码从main.py中移出,确保Flask应用能独立启动。
- 检查服务器启动日志:查看终端输出,确认Flask是否正常监听端口。
- 验证路由是否正确定义:确保根路由'/'和'/api/data'等路由正确配置。
- 测试最小可行应用:创建一个最简单的Flask应用测试基本功能是否正常。
添加错误处理后,服务器连接成功,但显示500,这表示当访问根路由/时,服务器返回了500错误。同时,数据库连接测试虽然显示成功,但可能存在查询问题。重点检查:
- 数据库连接配置:确保
db_config.py中的配置正确,包括数据库名称、用户名、密码、主机和端口。用户之前的连接字符串显示使用的是ak_data数据库,需要确认该数据库存在且包含stock_data表。 - 验证表结构:连接到MySQL数据库,检查
ak_data数据库中是否存在stock_data表,并确认包含symbol字段。执行DESCRIBE stock_data;来查看表结构。
解决了数据库连接问题后,现在页面显示AttributeError: 'Database' object has no attribute 'query' 错误。这个错误表明在Database类中缺少query方法。从之前的错误日志来看,DatabaseManager类的代码可能没有包含query方法。用户可能在重构过程中遗漏了这个方法的实现,或者在重命名类时没有正确继承或迁移原有方法。
在添加方法后,出现两个新的错误,现在需要解决两个新出现的错误:
- AttributeError: 'Database' object has no attribute 'engine'
- NameError: name 'encoded_password' is not defined
分析第一个错误:Database类缺少engine属性。查看database/database.py的代码,发现在__init__方法中没有创建engine实例。之前的重构可能遗漏了这部分代码。
分析第二个错误:encoded_password变量在log_error方法中被引用,但该变量是__init__方法的局部变量,没有保存为实例属性。
解决方案步骤:
- 在__init__方法中将encoded_password保存为实例变量
- 补全engine的初始化代码
- 将数据库连接字符串的构造移到__init__方法中
- 修复log_error方法中encoded_password的引用方式
4.3.2 后端个性化逻辑设计

👆因为AKShare提供的数据接口中,并不是所有输出都有股票代码,所以我一开始设想的:根据股票代码进行查询分析,我觉得对于不同的表进行个性化数据处理,这样也更加具有创新点,更具有可读性(^_^)v
于是,我修改了分析模块:
import pandas as pd
def analyze_data(table_name, df):
"""根据表名进行定制化数据分析"""
if 'stock_zh_a_daily' in table_name:
df = _analyze_stock_daily(df)
elif 'fund_portfolio_hold_em' in table_name:
df = _analyze_fund_portfolio(df)
elif 'macro_china' in table_name:
df = _analyze_macro_data(df)
elif 'currency_boc_sina' in table_name:
df = _analyze_currency_data(df)
# 通用分析
df['Update_Time'] = pd.Timestamp.now()
return df.dropna().reset_index(drop=True)
def _analyze_stock_daily(df):
# 股票日线分析
df['MA5'] = df['close'].rolling(5).mean()
df['MA20'] = df['close'].rolling(20).mean()
df['Volatility'] = df['close'].rolling(20).std()
return df.dropna()
def _analyze_fund_portfolio(df):
# 基金持仓分析
df['weight'] = df['weight'].str.replace('%', '').astype(float)
df['持仓占比排名'] = df['weight'].rank(ascending=False)
return df
def _analyze_macro_data(df):
# 宏观经济数据分析
if '全国-同比增长' in df.columns: # CPI数据
df['CPI_MA12'] = df['全国-同比增长'].rolling(12).mean()
df['CPI_Trend'] = df['CPI_MA12'].diff().apply(lambda x: '上涨' if x > 0 else '下跌')
if '国内生产总值-同比增长' in df.columns: # GDP数据
df['GDP_MA4'] = df['国内生产总值-同比增长'].rolling(4).mean()
df['GDP_Growth'] = df['国内生产总值-同比增长'].apply(lambda x: '扩张' if x > 6 else '放缓')
return df
系统已全面修复并优化,主要改进包括:
- 完全移除symbol依赖,采用表名驱动数据分析
- 增强数据清洗逻辑,支持多类型金融数据
- 优化前端展示,增加数据来源说明
- 修复数据库连接稳定性问题
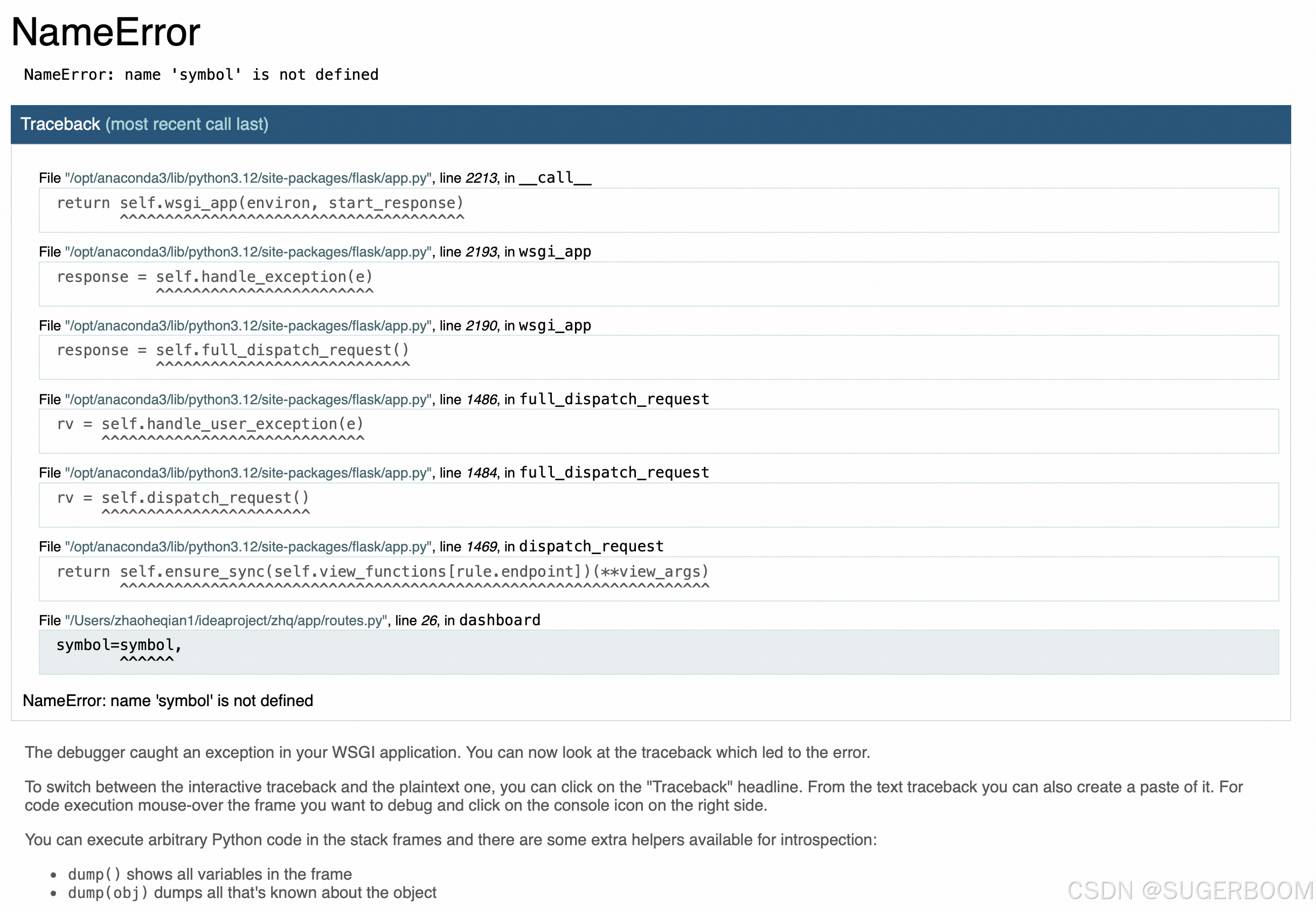
👆修正逻辑后,访问页面显示NameError,问题出在Flask应用中的 dashboard 视图函数中,具体是因为 symbol 变量未定义。
对于此问题:
- 修正路由文件中的模板渲染参数
- 更新仪表盘模板的标题显示
- 确保数据采集逻辑不依赖symbol字段
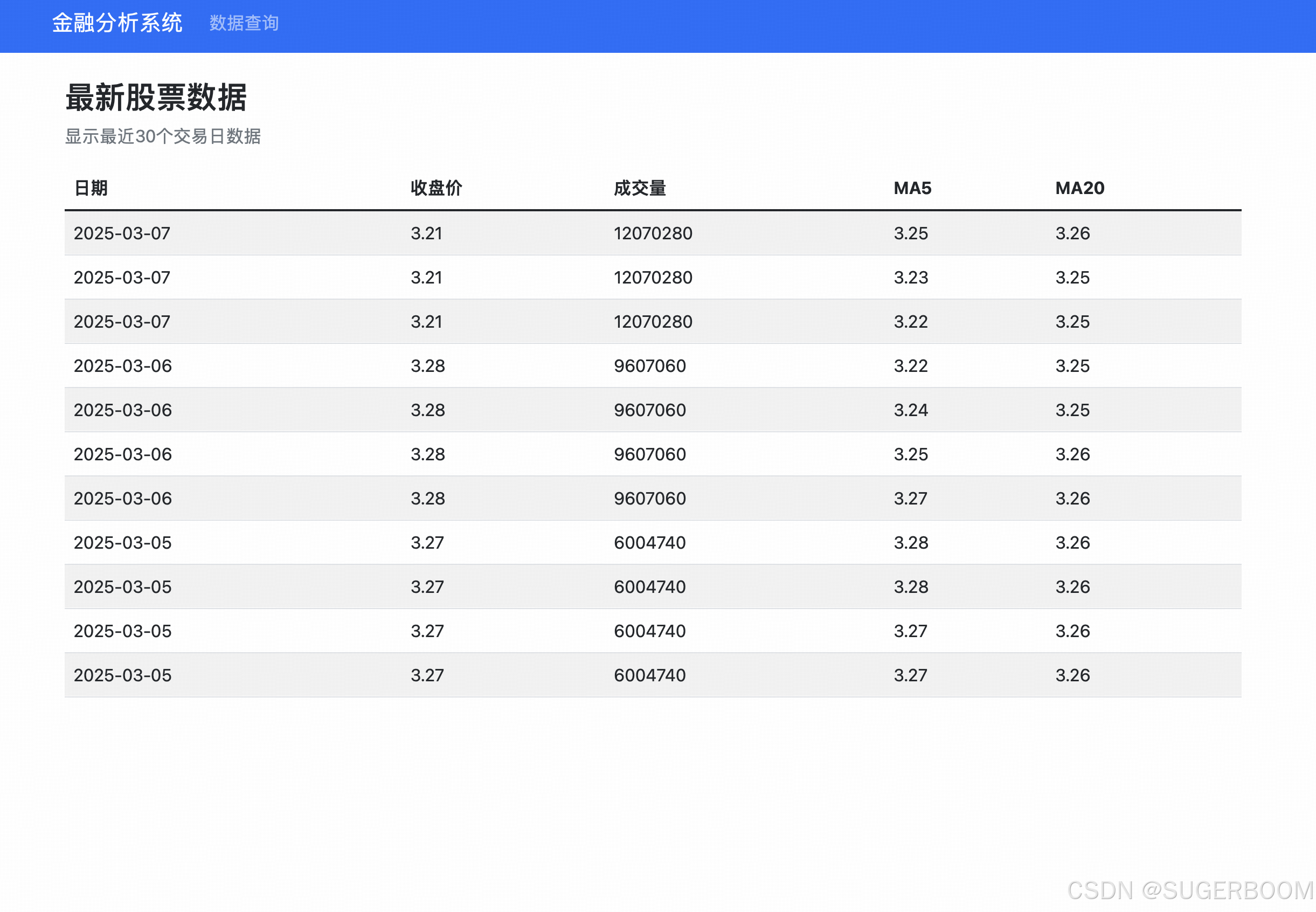
现在页面已经能够成功展示近30个交易日数据,这是一个很好的开始,表明对于数据库的连接以及API调用等都已经正确,后续只需要再做一些小的逻辑调整。
现在是25年3月14日晚上6:33,距本文开篇已过去一月有余,高坚果目前的状态为工作中抽空做毕设,虽然现在系统还没有完全搭好,但至少已经有了整体框架,后续抽空完善就好了(^_^)v
4.4 页面可视化展示
4.4.1 图表展示实施
对于前端更加细化的设计,我参考了金融分析系统——“软帆”。我想要一个前端页面类似于软帆的系统。那么接下来,我需要修改base.html,引入了ECharts的CDN,并在dashboard.html中添加了价格走势图和成交量分布图的容器。同时,在路由中处理了图表数据,将日期、收盘价和成交量数据传递到模板。另外安装了flask-echarts依赖,并进行数据预处理。
接下来,我需要考虑如何利用ECharts库来增强页面。可能需要添加新的图表容器,初始化脚本,以及对应的数据传递。同时,分页功能可能需要后端支持,比如处理分页参数,返回对应页面的数据,前端则需要处理分页控件的渲染和事件。
可能的步骤包括:
- 在dashboard.html中添加更多的图表容器,比如柱状图或更多饼图。
- 在JavaScript中初始化新的图表,配置对应的选项,并从后端获取数据。
- 在后端路由中处理分页参数,查询数据库并返回对应的数据。
- 在前端实现分页控件,并绑定点击事件以刷新数据。
- 确保所有图表在页面加载时正确渲染,并且在分页时动态更新。
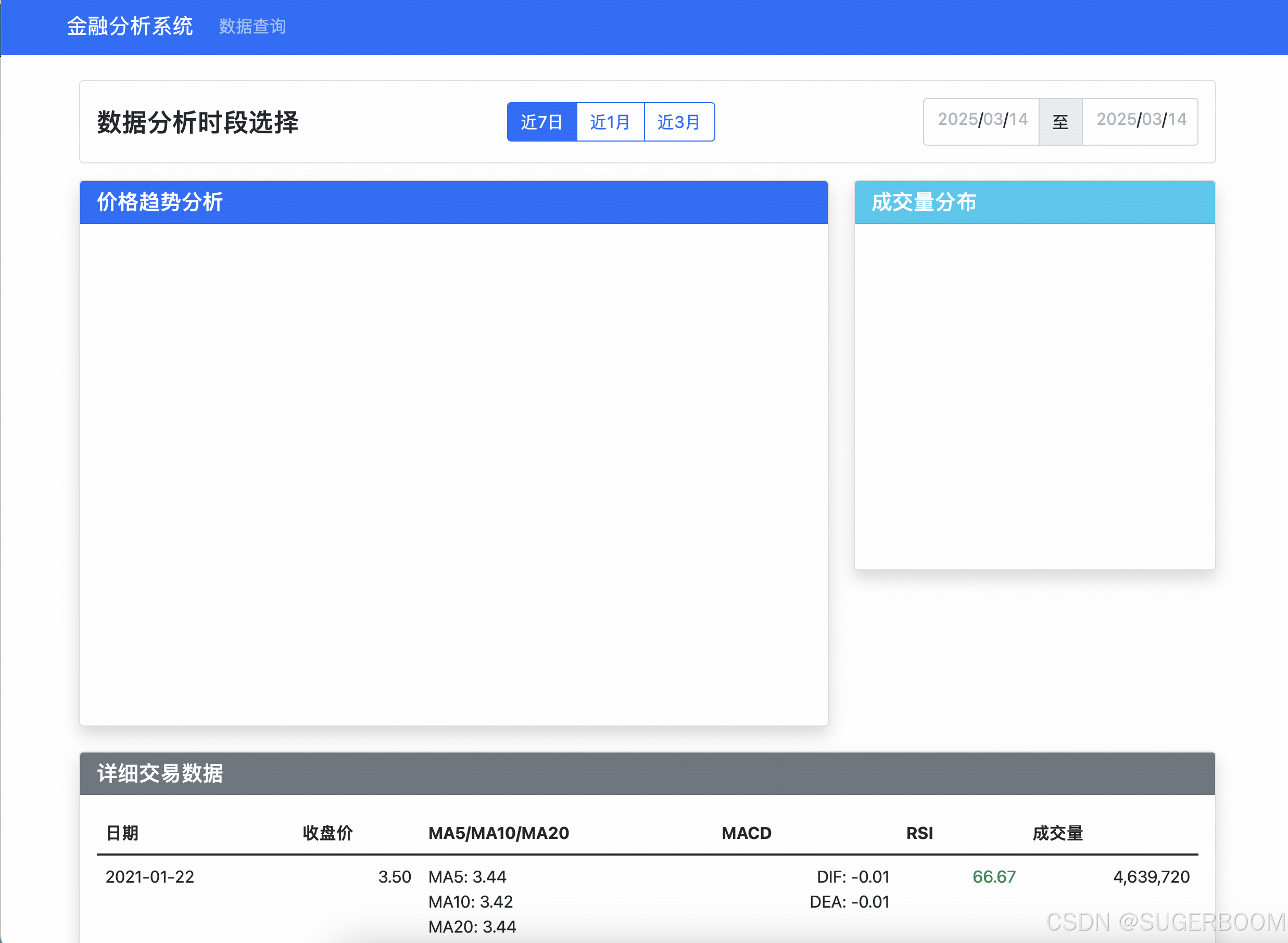
👆更新后首页如上,增添了分页式设计,并增加了图表以及时间段选择
4.4.2 页面框架更新复用
经过衡量,我认为现有页面布局不够合理,且单调,未突出创新性,故我决定复用我之前写的一个小网站中的前端逻辑,(SUGER-RDJ.github.io)将功能在侧拉边框中分点展示,主页面 保持简约,只展示搜索功能。(原网站功能通过上面的导航栏实现,不过前端逻辑大同小异,只需更改一些css和js即可)
👆上为原网站(原网站做的很简陋,基本只有前端逻辑)
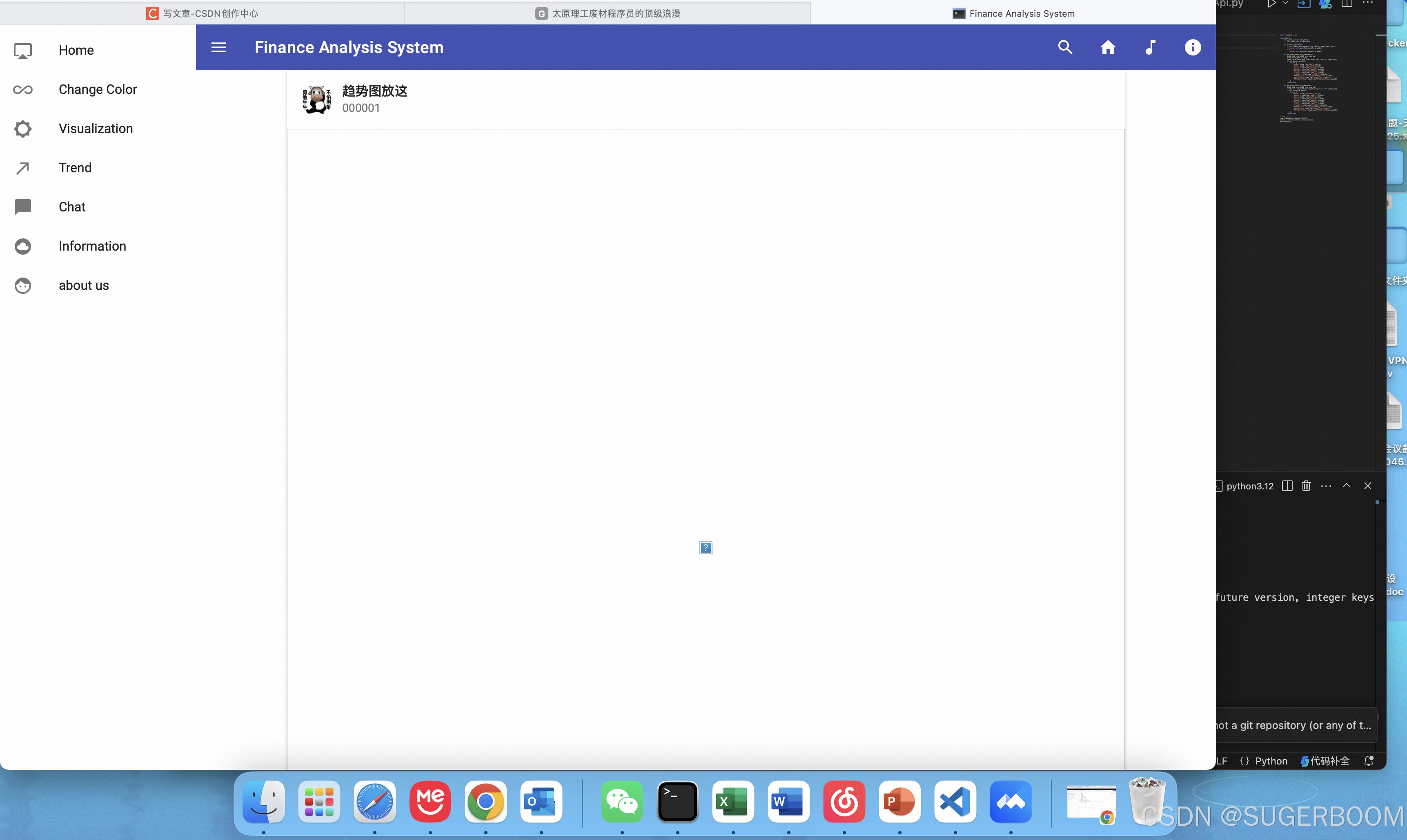
更改后的前端逻辑如上,在侧边栏中实现功能的选择,搜索股票的功能放置在右上角。侧边栏包括主页、更改页面颜色(用户友好设计)、分析数据展示、趋势展示、AI聊天功能、资料,和网站介绍。(可能存在多余功能,多余功能待删除,当然如果想到了合适的用法可以保留)
另外,对于这个系统,我有了其他设想:如果只是单纯拉取金融数据并经过一定调整后做展示,用户完全可以使用老牌的金融网站,如同花顺,或直接百度搜索等。即使添加了我自认为创新的趋势分析,据调查现已有其他上市系统能够做到,于是我考虑,趁AI浪潮,将AI融入系统,先大多炒股人的流程为:网站上刷到新闻资讯——复制新闻资讯——粘贴到AI应用中查证或分析——多份数据或长篇报道可能会有多次复制粘贴动作。故我考虑,是否能将AI直接融入到系统中,并规定适当的prompt,使该系统中的AI成为已经调整适当的、专为金融服务的AI。
4.5 系统逻辑重构
有了上面的思考,我的系统就需要打破重构。
首先,对于数据库的更正:我之前的逻辑是将金融数据拉取到数据库中,再从数据库中取数进行计算展示,但这似乎显得多此一举。现对于大多数金融API接口,他的数据已经经过了筛选的计算,完全可以直接使用,或者说只需要做小的、范围上的规定。如果将一切数据都放入数据库,再加上之后对于用户登陆身份信息的存储,数据库会显得冗余(更多的考虑是,我希望尽可能完成个信化的AI搭建,故我考虑将prompt及AI回答、用户反馈等内容存入数据库,空间有限,我不希望产生过多的log)。于是我去除了金融数据在数据库中的存储,转而将“表头”存入“字典”直接使用。
其次,对于新增功能,我考虑新增Chat——AI对话页面,以及“文本分析”,这是我新增的核心内容,旨在将文本内容解读,提取数据,并进行数据分析。
4.5.1 原有金融数据计算逻辑
import akshare as ak
import pandas as pd
from datetime import datetime
class Time:
@staticmethod
def today():
return datetime.now().strftime('%Y%m%d')
#个股的基本20天的成交涨跌幅
class Calculate_score:
def calculate_score(row):
scenarios = [
{
"market_range": (-0.005, 0.005),
"stock_ranges": [(0, 0.015, 0.5),(0.015, 0.025, 2), (0.025, 0.35,3), (0.035, 0.45,4),(0.45, 0.06, 5),(0.06, 0.07, 6),(0.07, 0.08, 7),
(0.08, float('inf'), 9)],
"negative_stock_ranges": [(0, 0.025, 0), (0.025, 0.35,-0.5), (0.035, 0.05, -1.5), (0.05, 0.06, -2.5),(0.06, 0.07, -3.5),(0.07, 0.08, -6),
(0.08, float('inf'), -8)]
},
{
"market_range": (-0.015, -0.005),
"stock_ranges": [(0, 0.015, 1),(0.015, 0.025, 2.5), (0.025, 0.35,3.5), (0.035, 0.45,4.5),(0.45, 0.06, 5.5),(0.06, 0.07, 6.5),(0.07, 0.08, 7.5),
(0.08, float('inf'), 9.5)],
"negative_stock_ranges": [(0, 0.025, 1), (0.025, 0.35,0), (0.035, 0.05, -1), (0.05, 0.06, -2),(0.06, 0.07, -3),(0.07, 0.08, -5.5),
(0.08, float('inf'), -7)]
},
{
"market_range": (-float('inf'), -0.015),
"stock_ranges": [(0, 0.015, 1.5),(0.015, 0.025, 3), (0.025, 0.35,4), (0.035, 0.45,5),(0.45, 0.06, 6),(0.06, 0.07, 7),(0.07, 0.08, 8),
(0.08, float('inf'), 10)],
"negative_stock_ranges": [(0, 0.025, 1.5), (0.025, 0.35,0.5), (0.035, 0.05, 0), (0.05, 0.06, -1),(0.06, 0.07, -2.5),(0.07, 0.08, -4.5),
(0.08, float('inf'), -6)]
},
{
"market_range": (0, 0.005),
"stock_ranges": [(0, 0.015, 0),(0.015, 0.025, 1.5), (0.025, 0.35,2.5), (0.035, 0.45,3.5),(0.45, 0.06, 4.5),(0.06, 0.07, 5.5),(0.07, 0.08, 6.5),
(0.08, float('inf'), 8.5)],
"negative_stock_ranges": [(0, 0.025, 0), (0.025, 0.35,-1), (0.035, 0.05, -2), (0.05, 0.06, -3),(0.06, 0.07, -4),(0.07, 0.08, -5),
(0.08, float('inf'), -6)]
},
{
"market_range": (0.005, 0.015),
"stock_ranges": [(0, 0.015, 0),(0.015, 0.025, 1), (0.025, 0.35,2), (0.035, 0.45,3),(0.45, 0.06, 4),(0.06, 0.07, 5),(0.07, 0.08, 6),
(0.08, float('inf'), 8)],
"negative_stock_ranges": [(0, 0.025, -0.5), (0.025, 0.35,-1.5), (0.035, 0.05, -2.5), (0.05, 0.06, -3.5),(0.06, 0.07, -4.5),(0.07, 0.08, -5.5),
(0.08, float('inf'), -7)]
},
{
"market_range": (0.015, float('inf')),
"stock_ranges": [(0, 0.015, -0.5),(0.015, 0.025, 0), (0.025, 0.35,1), (0.035, 0.45,2),(0.45, 0.06, 3),(0.06, 0.07, 4),(0.07, 0.08, 5),
(0.08, float('inf'), 6)],
"negative_stock_ranges": [(0, 0.025, -1.5), (0.025, 0.35,-2), (0.035, 0.05, -3), (0.05, 0.06, -5),(0.06, 0.07, -6),(0.07, 0.08, -8),
(0.08, float('inf'), -10)]
}
]
market_change = row['涨跌幅_大盘']
stock_change = row['涨跌幅_个股']
for scenario in scenarios:
if scenario["market_range"][0] <= market_change < scenario["market_range"][1]:
if stock_change >= 0:
for stock_range in scenario["stock_ranges"]:
if stock_range[0] <= stock_change < stock_range[1]:
return stock_range[2]
else:
for stock_range in scenario["negative_stock_ranges"]:
if -stock_range[1] < stock_change <= -stock_range[0]:
return stock_range[2]
return 0
class geguData_20:
def __init__(self, stock_code):
self.stock_code = stock_code
def get_recent_20_days_price_change(self):
end_date = Time.today()
stock_df = ak.stock_zh_a_hist(symbol=self.stock_code, period="daily", start_date="20230601", end_date=end_date, adjust="qfq")
# 获取最后20个交易日的数据
recent_20_days = stock_df.tail(20)
# 返回涨跌幅数据
return recent_20_days[['日期',"涨跌幅"]]
#个股的基本20天的成交涨跌幅
class dapanData_20:
def __init__(self, stock_code):
self.stock_code = stock_code
def get_recent_20_days_price_change(self):
end_date = Time.today()
if self.stock_code.startswith("68"):
self.stock_code="399088"
elif self.stock_code.startswith("60"):
self.stock_code = "000001"
elif self.stock_code.startswith("00"):
self.stock_code = "399005"
elif self.stock_code.startswith("30"):
self.stock_code = "399006"
else:
self.stock_code = "399006"
stock_df = ak.index_hist_cni(symbol=self.stock_code)
# 获取最后20个交易日的数据
recent_20_days = stock_df.head(20)
# 返回涨跌幅数据
return recent_20_days[['日期',"涨跌幅"]]
class BigTimian_20:
def __init__(self, stock_code):
self.gegu_data = geguData_20(stock_code)
self.dapan_data = dapanData_20(stock_code)
def get_combined_data(self):
gegu_df = self.gegu_data.get_recent_20_days_price_change()
dapan_df = self.dapan_data.get_recent_20_days_price_change()
#
# # 检查日期范围
# print("个股日期范围:", gegu_df["日期"].min(), "-", gegu_df["日期"].max())
# print("大盘日期范围:", dapan_df["日期"].min(), "-", dapan_df["日期"].max())
# print("个股的日期:", gegu_df["日期"].tolist())
# print("大盘的日期:", dapan_df["日期"].tolist())
# 将大盘的日期从字符串转换为datetime.date对象
dapan_df['日期'] = pd.to_datetime(dapan_df['日期']).dt.date
# 按日期排序两个数据集
gegu_df = gegu_df.sort_values(by='日期')
dapan_df = dapan_df.sort_values(by='日期')
gegu_df['涨跌幅']=gegu_df['涨跌幅']/100
# 取两个数据集日期的交集
common_dates = set(gegu_df['日期']).intersection(set(dapan_df['日期']))
# 根据交集过滤数据
gegu_df = gegu_df[gegu_df['日期'].isin(common_dates)]
dapan_df = dapan_df[dapan_df['日期'].isin(common_dates)]
# 合并数据
merged_df = gegu_df.merge(dapan_df, on='日期', suffixes=('_个股', '_大盘'))
# Calculate scores based on the rules
merged_df['得分'] = merged_df.apply(Calculate_score.calculate_score, axis=1)
sums=merged_df['得分'].sum()
return sums
class geguData_5:
def __init__(self, stock_code):
self.stock_code = stock_code
def get_recent_5_days_price_change(self):
end_date = Time.today()
stock_df = ak.stock_zh_a_hist(symbol=self.stock_code, period="daily", start_date="20230601", end_date=end_date, adjust="qfq")
# 获取最后20个交易日的数据
recent_5_days = stock_df.tail(5)
# 返回涨跌幅数据
return recent_5_days[['日期',"涨跌幅"]]
#个股的基本20天的成交涨跌幅
class dapanData_5:
def __init__(self, stock_code):
self.stock_code = stock_code
def get_recent_5_days_price_change(self):
if self.stock_code.startswith("68"):
self.stock_code="399088"
elif self.stock_code.startswith("60"):
self.stock_code = "000001"
elif self.stock_code.startswith("00"):
self.stock_code = "399005"
elif self.stock_code.startswith("30"):
self.stock_code = "399006"
else:
self.stock_code = "399006"
stock_df = ak.index_hist_cni(symbol=self.stock_code)
# 获取最后20个交易日的数据
recent_5_days = stock_df.head(5)
# 返回涨跌幅数据
return recent_5_days[['日期',"涨跌幅"]]
class BigTimian_5:
def __init__(self, stock_code):
self.gegu_data = geguData_5(stock_code)
self.dapan_data = dapanData_5(stock_code)
def get_combined_data(self):
gegu_df = self.gegu_data.get_recent_5_days_price_change()
dapan_df = self.dapan_data.get_recent_5_days_price_change()
dapan_df['日期'] = pd.to_datetime(dapan_df['日期']).dt.date
# 按日期排序两个数据集
gegu_df = gegu_df.sort_values(by='日期')
dapan_df = dapan_df.sort_values(by='日期')
gegu_df['涨跌幅']=gegu_df['涨跌幅']/100
# 取两个数据集日期的交集
common_dates = set(gegu_df['日期']).intersection(set(dapan_df['日期']))
# 根据交集过滤数据
gegu_df = gegu_df[gegu_df['日期'].isin(common_dates)]
dapan_df = dapan_df[dapan_df['日期'].isin(common_dates)]
# 合并数据
merged_df = gegu_df.merge(dapan_df, on='日期', suffixes=('_个股', '_大盘'))
# Calculate scores based on the rules
merged_df['得分'] = merged_df.apply(Calculate_score.calculate_score, axis=1)
sums=merged_df['得分'].sum()
return sums
import concurrent.futures
import os
class DataFetcher:
def __init__(self, hangye):
self.hangye = hangye
# 检查 self.hangye 的值是否有效
if not self.hangye:
raise ValueError("self.hangye 的值无效")
# 尝试获取数据
data = ak.stock_board_industry_cons_ths(symbol=self.hangye)
# 检查返回的 DataFrame 是否为空
if data.empty:
raise ValueError("返回的数据为空")
self.cache_dir = "./cache"
if not os.path.exists(self.cache_dir):
os.makedirs(self.cache_dir)
def get_stock_data(self, stock_code, days=20):
cache_file = os.path.join(self.cache_dir, f"{stock_code}_{days}.csv")
if os.path.exists(cache_file):
data_df = pd.read_csv(cache_file)
return data_df.iloc[0, 0] # get the single value from the DataFrame
else:
if days == 20:
data = BigTimian_20(stock_code).get_combined_data()
else:
data = BigTimian_5(stock_code).get_combined_data()
data_df = pd.DataFrame([data], columns=['score']) # convert the score to a DataFrame
data_df.to_csv(cache_file, index=False)
return data
def fetch_data(self):
stock_board_industry = ak.stock_board_industry_cons_ths(symbol=self.hangye)['代码']
pingjun_5 = 0
pingjun_20 = 0
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_stock = {executor.submit(self.get_stock_data, stock, 20): stock for stock in stock_board_industry}
for future in concurrent.futures.as_completed(future_to_stock):
stock = future_to_stock[future]
try:
data = future.result()
pingjun_20 += data
except Exception as exc:
print(f"Stock {stock} generated an exception: {exc}")
future_to_stock = {executor.submit(self.get_stock_data, stock, 5): stock for stock in stock_board_industry}
for future in concurrent.futures.as_completed(future_to_stock):
stock = future_to_stock[future]
try:
data = future.result()
pingjun_5 += data
except Exception as exc:
print(f"Stock {stock} generated an exception: {exc}")
changdu = len(stock_board_industry)
return round(pingjun_5 / changdu, 3), round(pingjun_20 / changdu, 3)
scenarios = [
{
"market_range": (-0.005, 0.005),
"stock_ranges": [(0, 0.015, 0.5),(0.015, 0.025, 2), (0.025, 0.35,3), (0.035, 0.45,4),(0.45, 0.06, 5),(0.06, 0.07, 6),(0.07, 0.08, 7),
(0.08, float('inf'), 9)],
"negative_stock_ranges": [(0, 0.025, 0), (0.025, 0.35,-0.5), (0.035, 0.05, -1.5), (0.05, 0.06, -2.5),(0.06, 0.07, -3.5),(0.07, 0.08, -6),
(0.08, float('inf'), -8)]
},
{
"market_range": (-0.015, -0.005),
"stock_ranges": [(0, 0.015, 1),(0.015, 0.025, 2.5), (0.025, 0.35,3.5), (0.035, 0.45,4.5),(0.45, 0.06, 5.5),(0.06, 0.07, 6.5),(0.07, 0.08, 7.5),
(0.08, float('inf'), 9.5)],
"negative_stock_ranges": [(0, 0.025, 1), (0.025, 0.35,0), (0.035, 0.05, -1), (0.05, 0.06, -2),(0.06, 0.07, -3),(0.07, 0.08, -5.5),
(0.08, float('inf'), -7)]
},
{
"market_range": (-float('inf'), -0.015),
"stock_ranges": [(0, 0.015, 1.5),(0.015, 0.025, 3), (0.025, 0.35,4), (0.035, 0.45,5),(0.45, 0.06, 6),(0.06, 0.07, 7),(0.07, 0.08, 8),
(0.08, float('inf'), 10)],
"negative_stock_ranges": [(0, 0.025, 1.5), (0.025, 0.35,0.5), (0.035, 0.05, 0), (0.05, 0.06, -1),(0.06, 0.07, -2.5),(0.07, 0.08, -4.5),
(0.08, float('inf'), -6)]
},
{
"market_range": (0, 0.005),
"stock_ranges": [(0, 0.015, 0),(0.015, 0.025, 1.5), (0.025, 0.35,2.5), (0.035, 0.45,3.5),(0.45, 0.06, 4.5),(0.06, 0.07, 5.5),(0.07, 0.08, 6.5),
(0.08, float('inf'), 8.5)],
"negative_stock_ranges": [(0, 0.025, 0), (0.025, 0.35,-1), (0.035, 0.05, -2), (0.05, 0.06, -3),(0.06, 0.07, -4),(0.07, 0.08, -5),
(0.08, float('inf'), -6)]
},
{
"market_range": (0.005, 0.015),
"stock_ranges": [(0, 0.015, 0),(0.015, 0.025, 1), (0.025, 0.35,2), (0.035, 0.45,3),(0.45, 0.06, 4),(0.06, 0.07, 5),(0.07, 0.08, 6),
(0.08, float('inf'), 8)],
"negative_stock_ranges": [(0, 0.025, -0.5), (0.025, 0.35,-1.5), (0.035, 0.05, -2.5), (0.05, 0.06, -3.5),(0.06, 0.07, -4.5),(0.07, 0.08, -5.5),
(0.08, float('inf'), -7)]
},
{
"market_range": (0.015, float('inf')),
"stock_ranges": [(0, 0.015, -0.5),(0.015, 0.025, 0), (0.025, 0.35,1), (0.035, 0.45,2),(0.45, 0.06, 3),(0.06, 0.07, 4),(0.07, 0.08, 5),
(0.08, float('inf'), 6)],
"negative_stock_ranges": [(0, 0.025, -1.5), (0.025, 0.35,-2), (0.035, 0.05, -3), (0.05, 0.06, -5),(0.06, 0.07, -6),(0.07, 0.08, -8),
(0.08, float('inf'), -10)]
}
]
class SZZS:
def szzs(query):
if query.startswith("68"):
stock_code = "399088"
elif query.startswith("60"):
stock_code = "000001"
elif query.startswith("00"):
stock_code = "399005"
elif query.startswith("30"):
stock_code = "399006"
else:
stock_code = "399006"
stock_df = ak.index_hist_cni(symbol=stock_code).head(30)[["日期","收盘价","成交量","涨跌幅"]]
return stock_df
def gegu(query):
data =ak.stock_zh_a_hist(symbol=query, period="daily")
return data.tail(30)[["日期","收盘","换手率","涨跌幅"]]
def calculate_score(row, scenarios):
market_change = row["涨跌幅_y"]
stock_change = row["涨跌幅_x"]
for scenario in scenarios:
if scenario["market_range"][0] <= market_change <= scenario["market_range"][1]:
# Check if the stock change is positive or negative
if stock_change >= 0:
for lower, upper, score in scenario["stock_ranges"]:
if lower <= stock_change < upper:
return score
else:
for lower, upper, score in scenario["negative_stock_ranges"]:
if lower <= abs(stock_change) < upper:
return score
return 0 # Default score if no range matches
def timian_30(query):
sz=SZZS.szzs(query)
gg=SZZS.gegu(query)
gg["日期"]=gg["日期"].apply(lambda date: datetime.strftime(date,"%Y-%m-%d"))
gg["涨跌幅"] = gg["涨跌幅"]/100
# 使用日期列进行内联
result = pd.merge(gg, sz, on="日期", how="inner")
result["计分"] = result.apply(lambda row: SZZS.calculate_score(row, scenarios), axis=1)
return result
data_sample =SZZS.timian_30("300318")
这段Python代码的主要逻辑是分析股票相对于大盘的表现,并给出评分。可以分成几个部分来理解:
-
基础功能:
-
获取个股和大盘(指数)的历史交易数据(最近20天或30天)
-
计算个股每日涨跌幅和大盘每日涨跌幅
-
-
评分规则:
-
有6种不同的大盘涨跌情景(从大幅下跌到大幅上涨)
-
每种大盘情景下:
-
如果个股上涨:按涨幅区间给正分(涨得越多分越高)
-
如果个股下跌:按跌幅区间给负分(跌得越多扣分越多)
-
-
大盘越差时,个股上涨得分越高;大盘越好时,个股下跌扣分越多
-
-
主要计算:
-
对每只股票,计算它最近20天/5天每天的得分
-
把所有日期得分相加,得到总分
-
对于行业分析,计算该行业所有股票的平均分
-
-
数据获取:
-
自动识别股票代码属于哪个板块(沪市/深市/创业板等)
-
获取对应大盘指数数据进行比较
-
支持多线程加速获取数据
-
-
输出结果:
-
最终输出个股或行业在一段时间内的综合评分
-
分数越高表示该股票/行业相对大盘表现越好
-
简单说就是:比较个股和大盘每天的涨跌,根据规则打分,最后汇总分数来判断股票表现好坏。
另外,去除了数据库的存储,我转而将拉取到的数据存入“词库”中,这里引用到了jieba中文分词库。
import akshare as ak
import jieba
from kline import StockKLinePlotter
class StockInfoExtractor:
def __init__(self):
# 获取 A 股股票基本信息
self.stock_info_df = ak.stock_info_a_code_name()
# 提取所有的股票名称
self.stock_names = self.stock_info_df["name"].tolist()
# 将所有股票名称添加到 jieba 的自定义词典中
for stock_name in self.stock_names:
jieba.add_word(stock_name)
def show(self):
return self.stock_names
def get_stock_details(self, text):
# 使用 jieba 进行分词
words = jieba.lcut(text)
matched_stocks = [stock_name for stock_name in self.stock_names if stock_name in words]
stock_details = []
img_set=StockKLinePlotter()
for stock_name in matched_stocks:
code = self.stock_info_df[self.stock_info_df["name"] == stock_name]["code"].values[0]
# 使用 akshare 获取主营业务信息
stock_zyjs_df = ak.stock_zyjs_ths(symbol=code)
#行业
industry=ak.stock_individual_info_em(symbol=code)["value"][2]
main_business = stock_zyjs_df["主营业务"].values[0] if not stock_zyjs_df.empty else "未知"
img = img_set.get_k_line_plot_base64(code)
stock_details.append((stock_name, code, industry,main_business,img))
stock_detail=[]
for stock in stock_details:
if stock[1].startswith("30") or stock[1].startswith("60") or stock[1].startswith("00"):
stock_detail.append(stock)
return stock_detail
# 创建类的实例
# stock_data_extractor = StockInfoExtractor()
# # 示例:提取文本中的股票名称并查询详细信息
# text = "最近,齐鲁华信和长信科技的股价都有所上涨。"
# stock_details = stock_data_extractor.get_stock_details(text)
# print(stock_details)
是一个 股票信息提取器 类,主要功能是从文本中识别股票名称并查询相关详细信息。以下是它的核心功能解析:
🎯 核心功能
-
股票名称识别
-
预加载所有A股股票名称(4000+只)
-
使用
jieba分词库,将股票名称添加为自定义词典(提高识别准确率) -
从输入文本中精准匹配股票名称
-
-
多维信息查询
-
股票代码:如
600519(茅台) -
所属行业:如
酿酒行业 -
主营业务:如
茅台酒的生产与销售 -
K线图:自动生成Base64编码的近期K线图
-
-
数据源
-
使用
akshare获取实时金融数据 -
自动过滤非主板股票(仅保留代码以
30/60/00开头的股票)
-
⚙️ 技术实现亮点
-
jieba优化
提前将全部股票名称加入分词词典,避免误切分(如"长信科技"不会被切成"长信/科技") -
数据高效查询
-
股票代码和名称的映射通过Pandas快速查询
-
使用
stock_zyjs_ths获取主营业务(比通用接口更精准)
-
-
可视化集成
直接调用StockKLinePlotter生成K线图,适合嵌入到Web或APP中显示
4.5.2 可视化逻辑实现
import akshare as ak
from datetime import datetime
import pandas as pd
import mplfinance as mpf
import base64
from io import BytesIO
import matplotlib
matplotlib.use('Agg')
class StockKLinePlotter:
def __init__(self):
pass # akshare不需要登录
def _get_stock_data(self, stock_code, start_date='20230701'):
end_date = datetime.now().strftime("%Y%m%d")
result = ak.stock_zh_a_hist(symbol=stock_code, start_date=start_date, end_date=end_date, adjust="qfq")
# Convert the 'date' column to datetime format
# Rename the columns to match mplfinance's expected column names
result = result.rename(
columns={"开盘": "Open", "收盘": "Close", "最高": "High", "最低": "Low", "成交量": "Volume"})
result.index = pd.to_datetime(result["日期"])
result = result.drop(columns=["日期"])
return result
def get_k_line_plot(self, stock_code, start_date='20230701'):
result = self._get_stock_data(stock_code, start_date)
# Save the plot to an image file and return its path
image_path = f"{stock_code}_k_line.png"
mpf.plot(result, type='candle', style='charles', savefig=image_path)
return image_path
def get_k_line_plot_base64(self, stock_code, start_date='20230701'):
result = self._get_stock_data(stock_code, start_date)
buf = BytesIO()
mc = mpf.make_marketcolors(
up="red",
down="green",
edge="black",
volume="blue",
wick="black"
)
s = mpf.make_mpf_style(base_mpf_style="charles", marketcolors=mc)
mpf.plot(result, type='candle', style=s, savefig=dict(fname=buf, format='png'))
buf.seek(0)
encoded_image_data = base64.b64encode(buf.read()).decode('utf-8')
return encoded_image_data
def get_k_line_plot_base64_start(self, stock_code, start_date):
result = self._get_stock_data(stock_code, start_date)
buf = BytesIO()
mc = mpf.make_marketcolors(
up="red",
down="green",
edge="black",
volume="blue",
wick="black"
)
s = mpf.make_mpf_style(base_mpf_style="charles", marketcolors=mc)
mpf.plot(result, type='candle', style=s, savefig=dict(fname=buf, format='png'))
buf.seek(0)
encoded_image_data = base64.b64encode(buf.read()).decode('utf-8')
return encoded_image_data
import akshare as ak
from datetime import datetime
import pandas as pd
import mplfinance as mpf
import base64
from io import BytesIO
import matplotlib
matplotlib.use('Agg')
class StockKLinePlotter:
def __init__(self):
pass # akshare不需要登录
def _get_stock_data(self, stock_code, start_date):
end_date = datetime.now().strftime("%Y%m%d")
result = ak.stock_zh_a_hist(symbol=stock_code, start_date=start_date, end_date=end_date, adjust="qfq")
# Convert the 'date' column to datetime format
# Rename the columns to match mplfinance's expected column names
result = result.rename(
columns={"开盘": "Open", "收盘": "Close", "最高": "High", "最低": "Low", "成交量": "Volume"})
result.index = pd.to_datetime(result["日期"])
result = result.drop(columns=["日期"])
return result
def get_k_line_plot(self, stock_code, start_date):
result = self._get_stock_data(stock_code, start_date)
# Save the plot to an image file and return its path
image_path = f"{stock_code}_k_line.png"
mpf.plot(result, type='candle', style='charles', savefig=image_path)
return image_path
def get_k_line_plot_base64(self, stock_code, start_date):
result = self._get_stock_data(stock_code, start_date)
buf = BytesIO()
mc = mpf.make_marketcolors(
up="red",
down="green",
edge="black",
volume="blue",
wick="black"
)
s = mpf.make_mpf_style(base_mpf_style="charles", marketcolors=mc)
mpf.plot(result, type='candle', style=s, savefig=dict(fname=buf, format='png'))
buf.seek(0)
encoded_image_data = base64.b64encode(buf.read()).decode('utf-8')
return encoded_image_data
def get_k_line_plot_base64_start(self, stock_code, start_date):
result = self._get_stock_data(stock_code, start_date)
buf = BytesIO()
mc = mpf.make_marketcolors(
up="red",
down="green",
edge="black",
volume="blue",
wick="black"
)
s = mpf.make_mpf_style(base_mpf_style="charles", marketcolors=mc)
mpf.plot(result, type='candle', style=s, savefig=dict(fname=buf, format='png'))
buf.seek(0)
encoded_image_data = base64.b64encode(buf.read()).decode('utf-8')
return encoded_image_data
上两段代码都是是用于生成股票K线图的工具类,主要功能是通过AKShare获取股票数据,并使用mplfinance库绘制专业的K线图。
主要功能
-
数据获取:
-
使用AKShare库获取A股历史数据
-
自动处理日期范围(从指定日期到当前日期)
-
数据包含开盘价、收盘价、最高价、最低价和成交量
-
-
K线图绘制:
-
使用mplfinance库生成专业的蜡烛图(K线图)
-
支持两种输出方式:
-
保存为图片文件
-
生成Base64编码的图片数据(适合网页显示)
-
-
-
样式定制:
-
红色表示上涨
-
绿色表示下跌
-
黑色边框和影线
-
蓝色成交量柱状图
-
4.5.3 文章分析功能
对于新增功能,我决定使用类国产AI中的“链接提交参考功能”,在底部新增一个模块:用户可以在此提交pdf或word,以及图片,系统实现内容中金融数据的自动提取分析,我在后端规定适当的prompt,提前调试接入AI为一款“专为金融数据服务的AI应用”
五、项目整体架构
5.1 项目构建功能及方法
至此,我们完成了项目的整体构建,这个项目是一个基于Flask的web应用,主要用于股票信息的处理、分析和可视化。
以下是项目的主要功能和方法:
-
文件处理和信息提取:
- 方法:extract_text_from_pdf, StockInfoExtractor.get_stock_details
- 功能:处理上传的Word和PDF文件,提取文本内容和股票信息
- 调用:在index路由中
-
股票信息展示:
- 方法:zhifu.zhifu_info
- 功能:获取股票的详细信息
- 调用:在zhifudaima_detail路由中
-
股票可视化:
- 方法:StockKLinePlotter.get_k_line_plot_base64_start
- 功能:生成股票K线图
- 调用:在visualization路由中
-
股票评分:
- 方法:BigTimian_20.get_combined_data, BigTimian_5.get_combined_data
- 功能:计算股票的20天和5天评分
- 调用:在visualization和search路由中
-
行业数据获取:
- 方法:DataFetcher.fetch_data(注释掉的代码)
- 功能:获取行业平均数据
- 调用:在visualization路由中(已注释)
-
股票搜索:
- 方法:Search.process_input
- 功能:处理用户输入,搜索股票信息
- 调用:在search路由中
-
AI对话:
- 方法:chat_with_spark
- 功能:与AI进行对话
- 调用:在chat路由中
-
市场趋势分析:
- 方法:ak.stock_board_concept_name_ths
- 功能:获取股票板块概念名称
- 调用:在trend路由中
-
汇率信息:
- 方法:ak.fx_spot_quote
- 功能:获取即期汇率报价
- 调用:在information路由中
-
指数和个股数据:
- 方法:SZZS.szzs, SZZS.gegu, SZZS.timian_30
- 功能:获取指数和个股的历史数据,计算30天评分
- 调用:在search路由中
主要路由及其功能:
- /: 首页,处理文件上传和股票信息提取
- /about: 关于页面
- /visualization: 股票可视化页面
- /information: 显示汇率信息
- /trend: 显示市场趋势
- /search: 股票搜索和详细信息展示
- /zhifudaima: 显示提取的股票信息
- /chat: AI对话界面
- /zhifudaima_detail/<zhifudaima_code>: 显示特定股票的详细信息
5.2 项目使用指导
访问Web端,首先进入到登录页面
如果没有账号,可点击注册按钮注册(注册用户默认为user权限,当然可升级为管理员,但需要管理员操作,此部分内容后面细讲)
首先我们以普通用户的身份登录,访问到该系统主页面
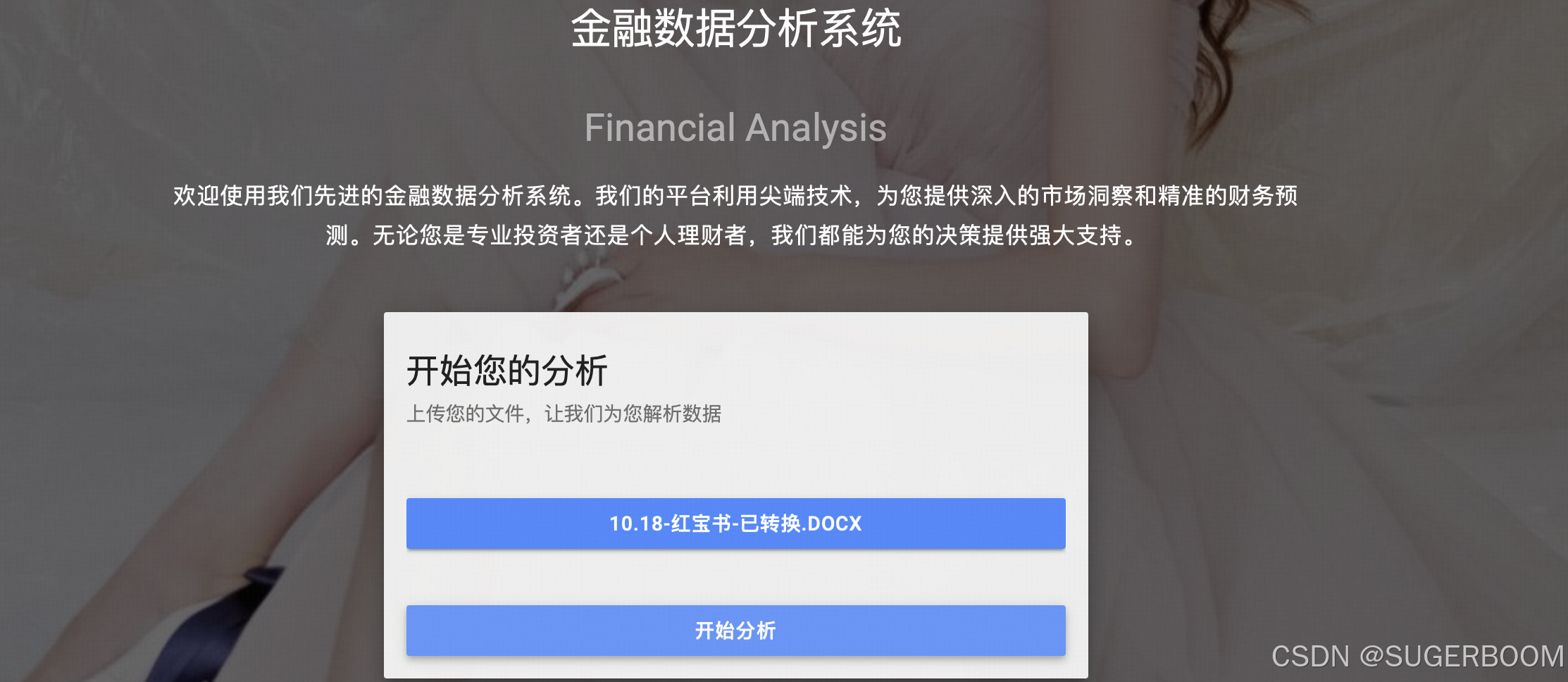
系统的核心功能为文件分析,点击选择文件,可上传本地文件,选择后点击开始分析,后台进行数据的拆分与处理
系统通过分析文件,得到了诸多行业号(文件中所涉及到的行业),点击序号可展开简介,简介中含有名称、股票代码、基础介绍和走势图等基本信息
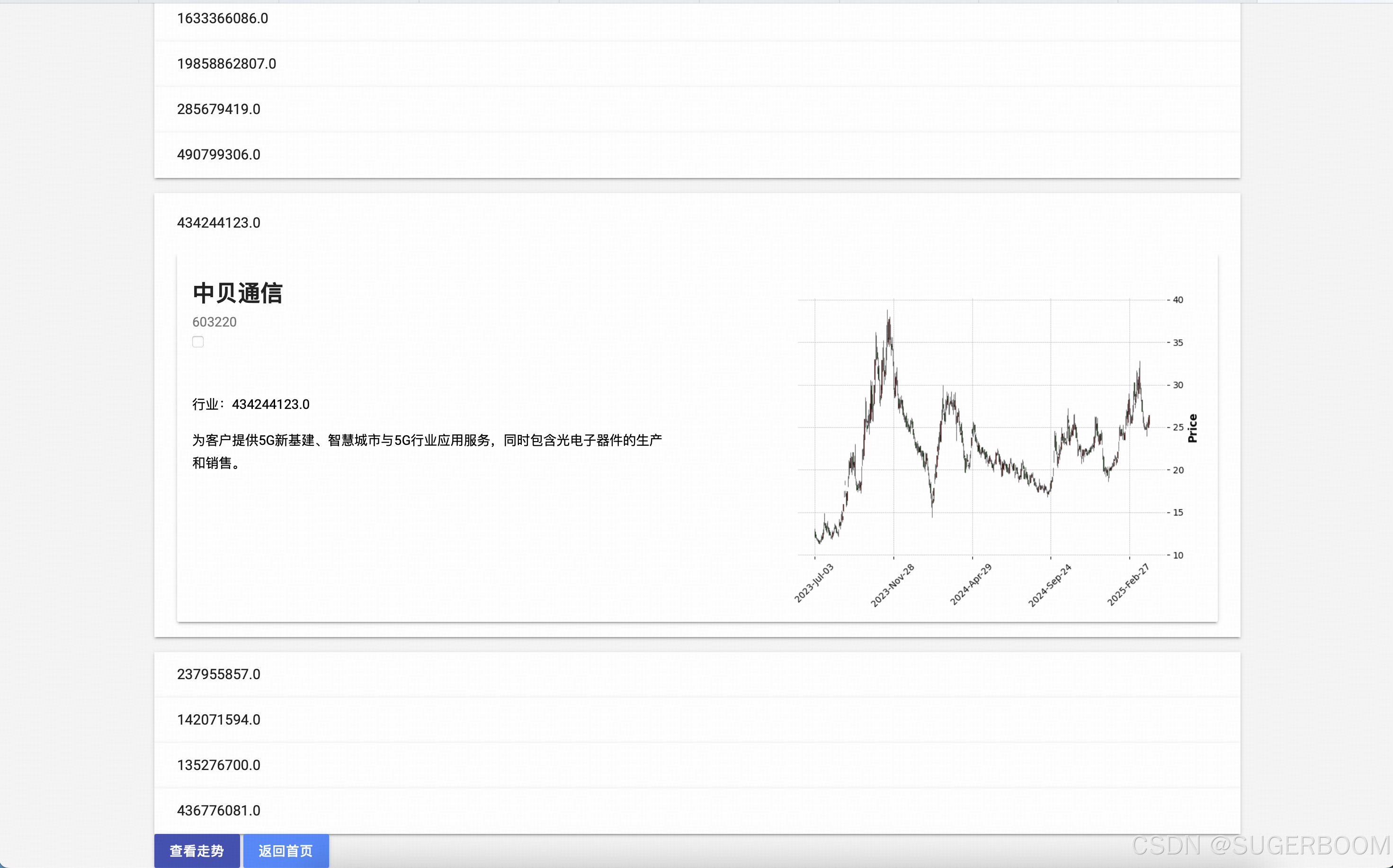
选中想要进一步分析的股票,点击“查看走势”即可得到更详细的信息。
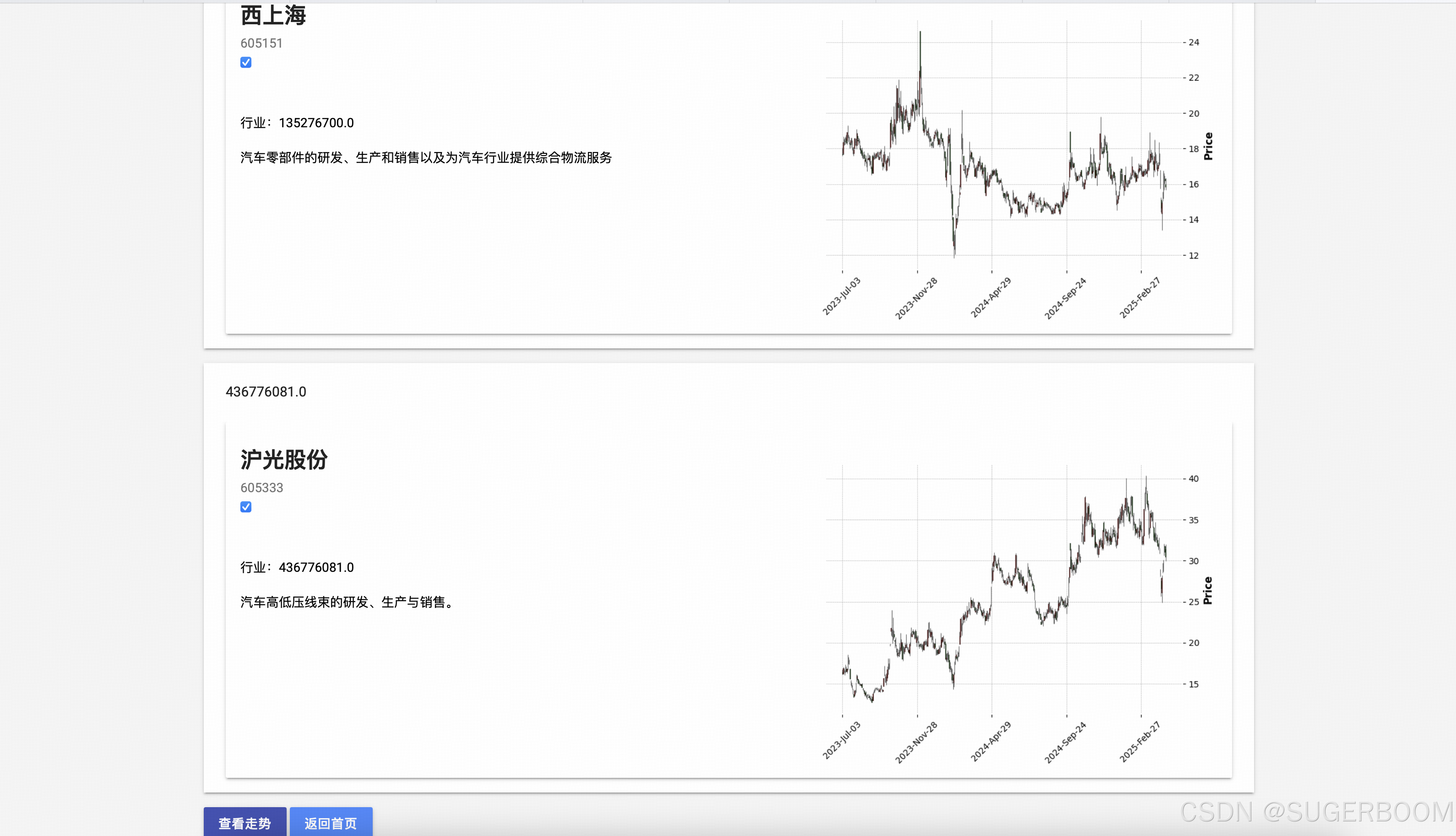
当然,可以单独分析,也可以选中多个对比分析,这正是本项目最大的创新之处
不再局限于文件描述,能够自动筛选文章中涉及到的金融数据,并以图表的形式直观的展现对比。
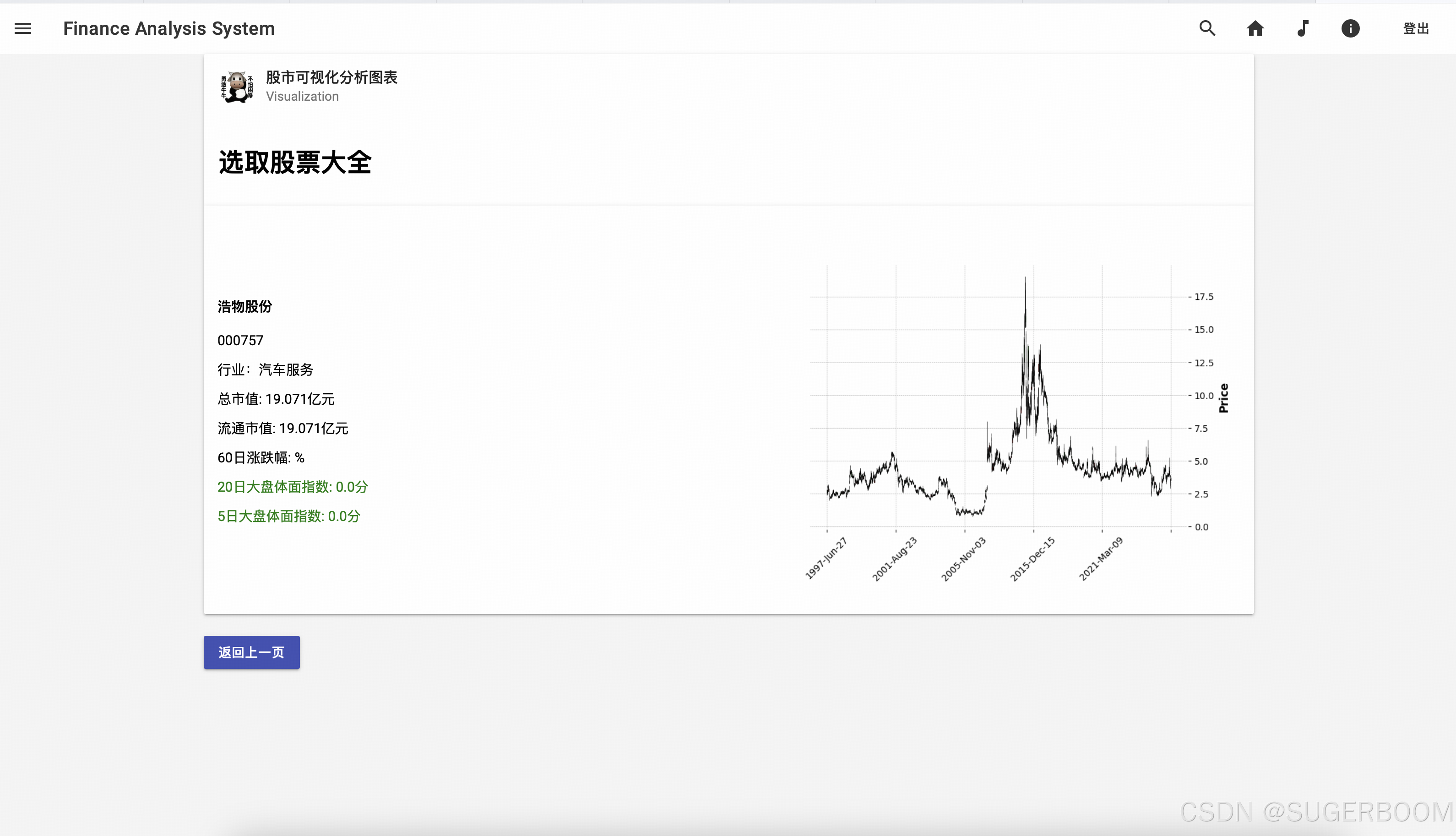
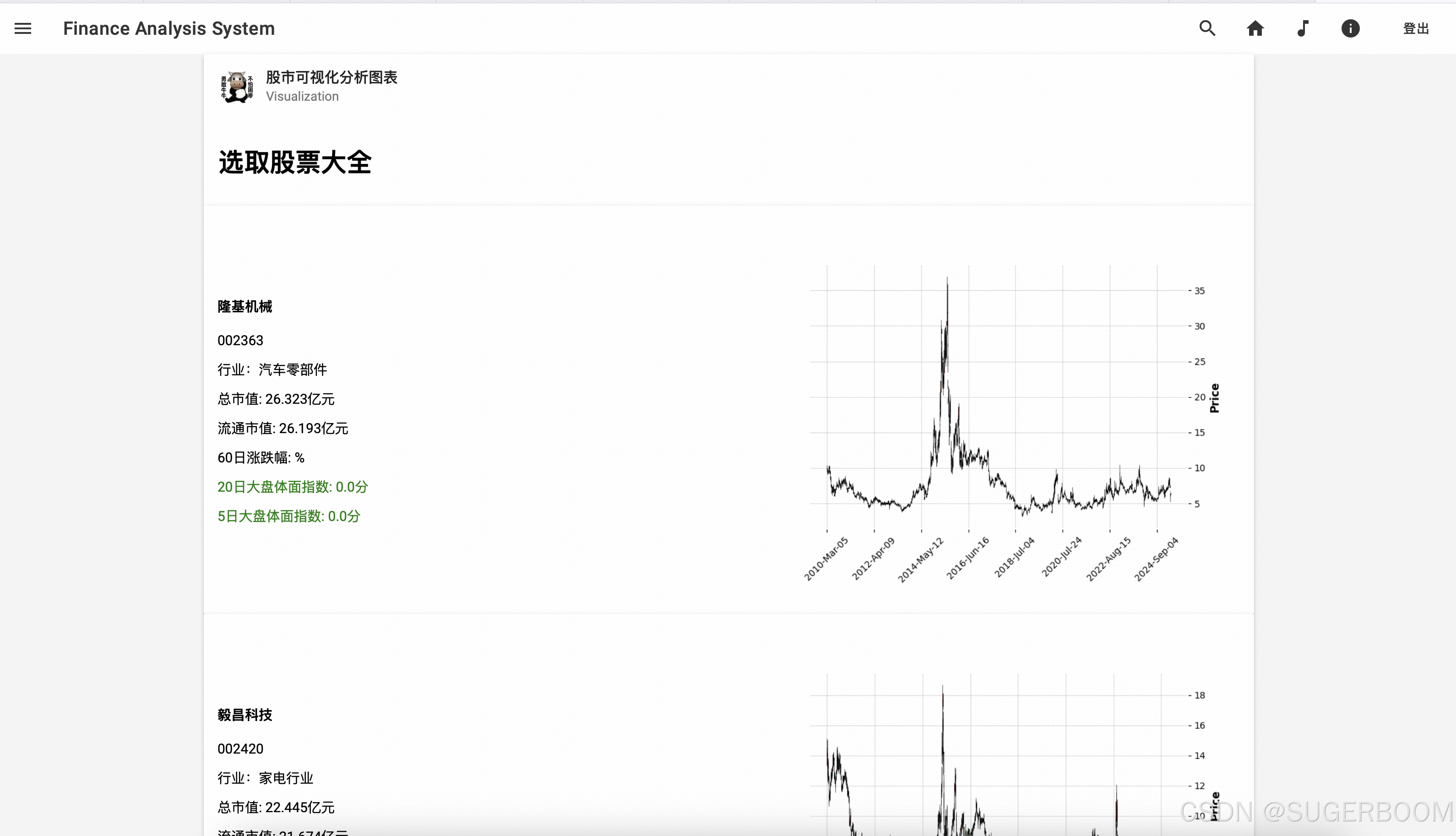
现在我们再来看搜索功能——点击右上角的放大镜,即可展开搜索栏,使用股票代码或名称都可以搜索到您想要查询的股票

我们以000001号股票为例,搜索后展示股票的详细数据,包括个股股价走势,对应指数走势,均通过直观的折线图展示,鼠标停留可以查看数据。 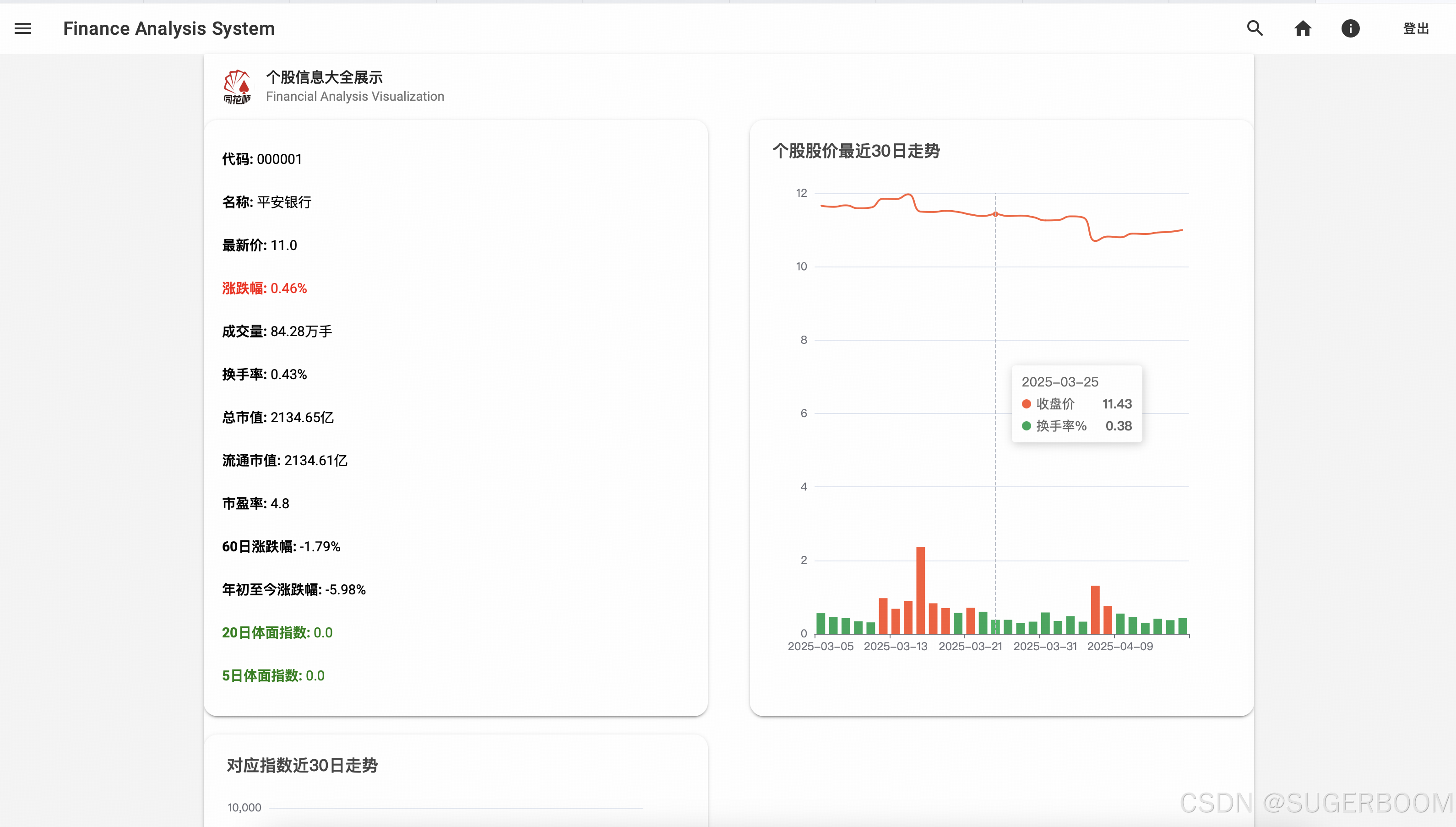
现在让我们回到主页,查看侧边栏中的一些功能
Change Color可以改变日间夜间模式


侧边栏中的Visualization是分析页(股市可视化分析图表),之前通过分析文档得出的图表便在此展示。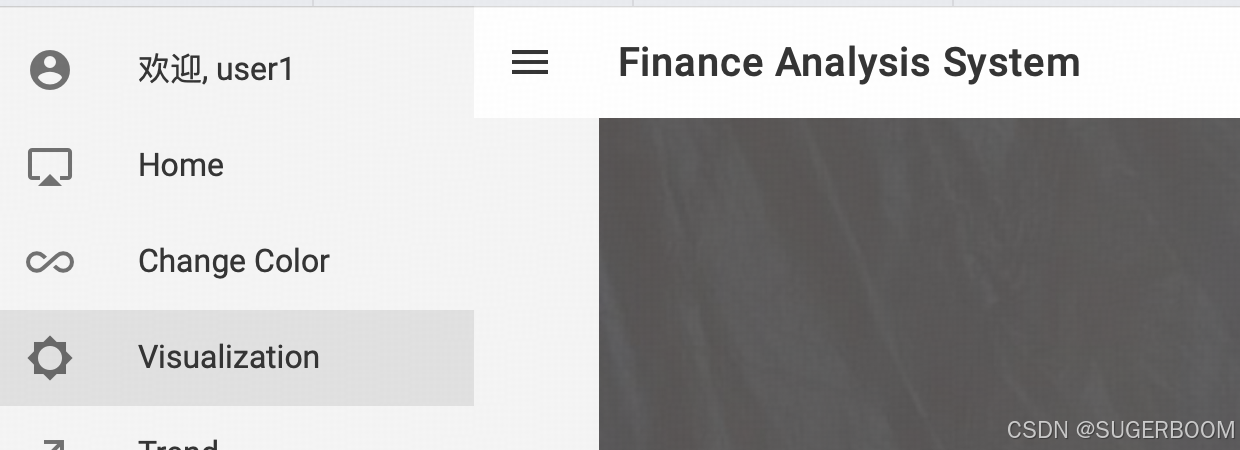
侧边栏中的Trend是行业趋势展示, 这里会实时获取行业最新热点,方便快速了解行业趋势。
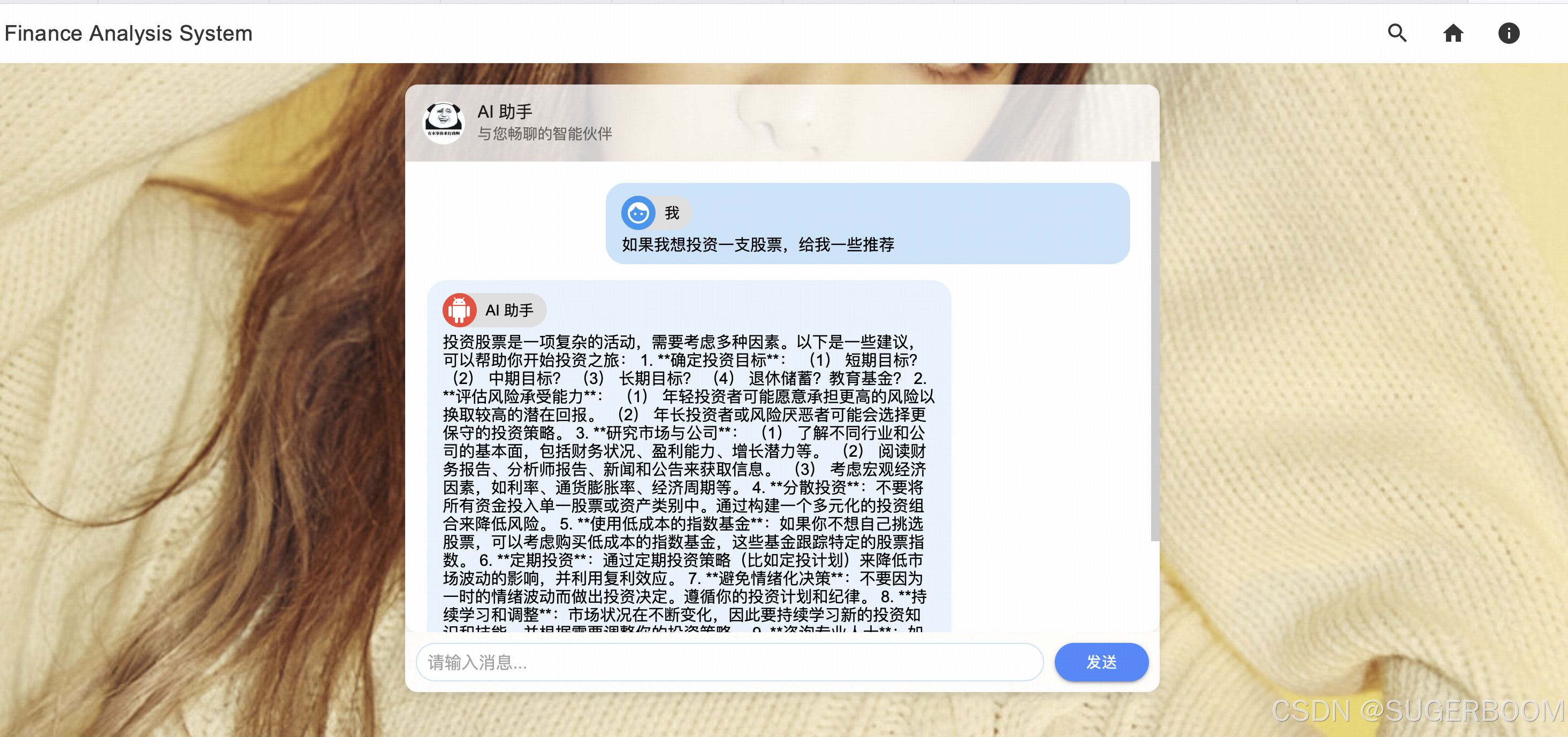
侧边栏中的Chat是聊天界面,接入科大讯飞免费智能大模型,可以在此与AI对话。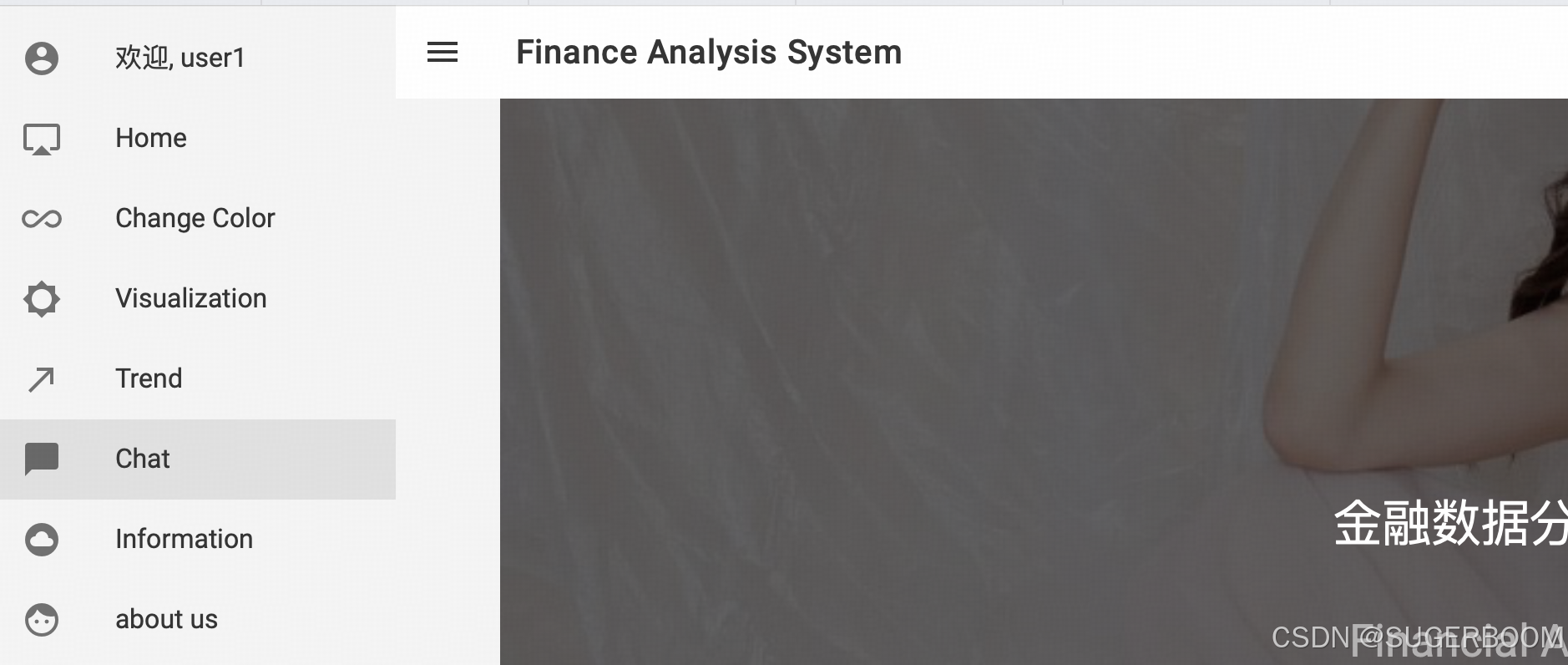
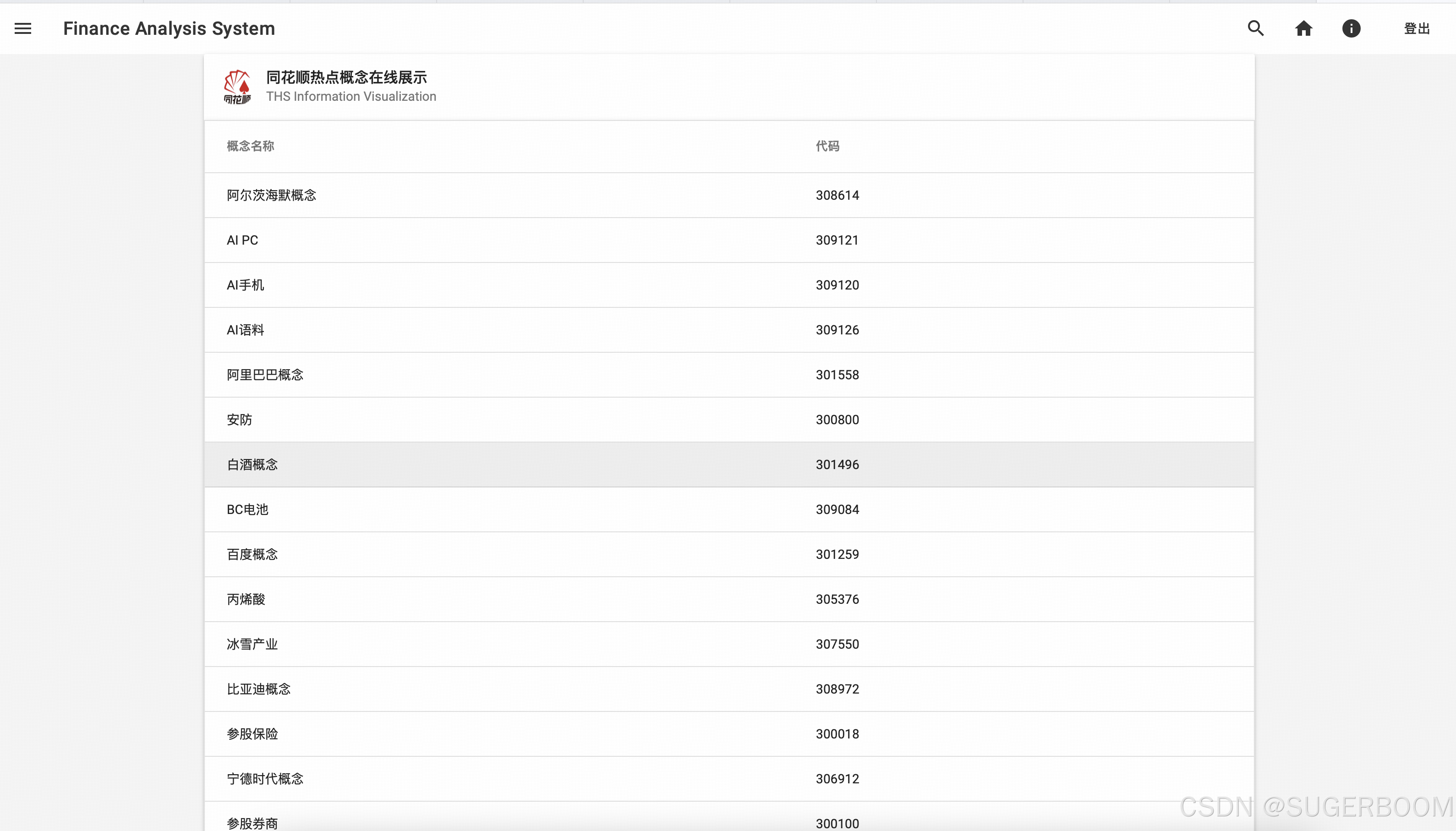
Infoemation是股市信息获取的“导航”,本系统相关的数据基本也是通过这些相关接口获取,此外还展示了人民币与美元的实时汇率。
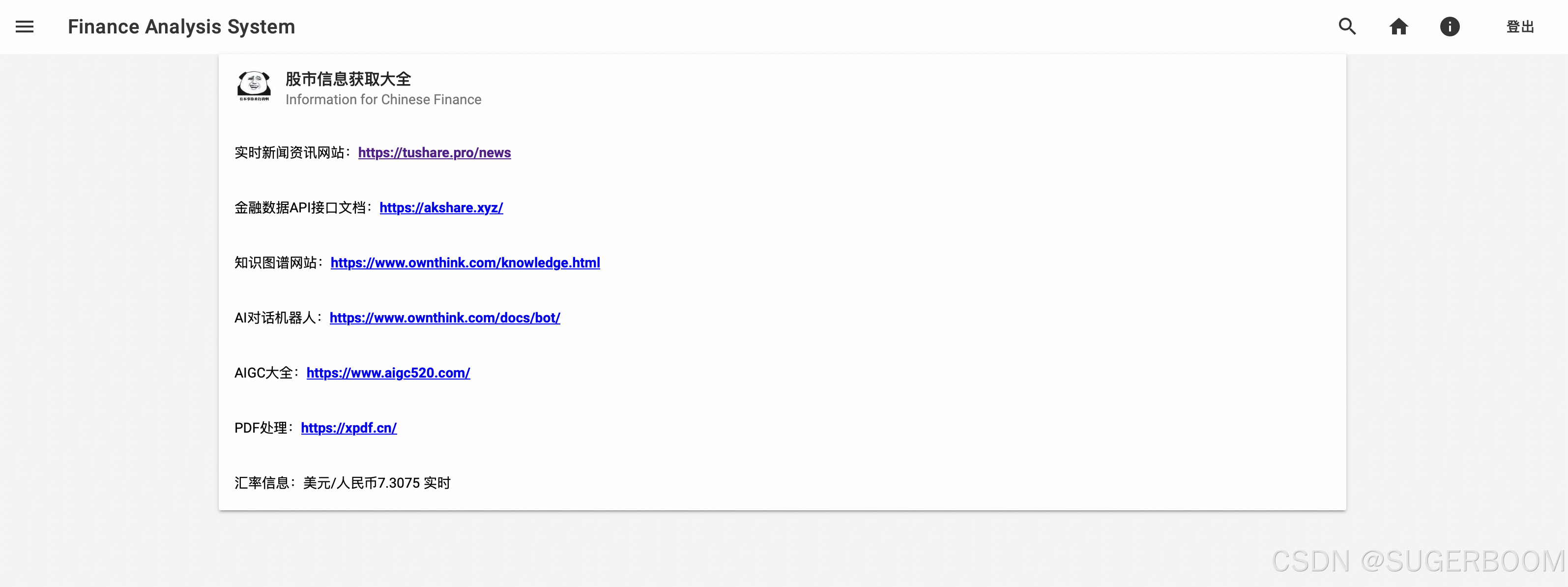
以上便是普通用户的可使用功能,现在我们来看管理员的页面。
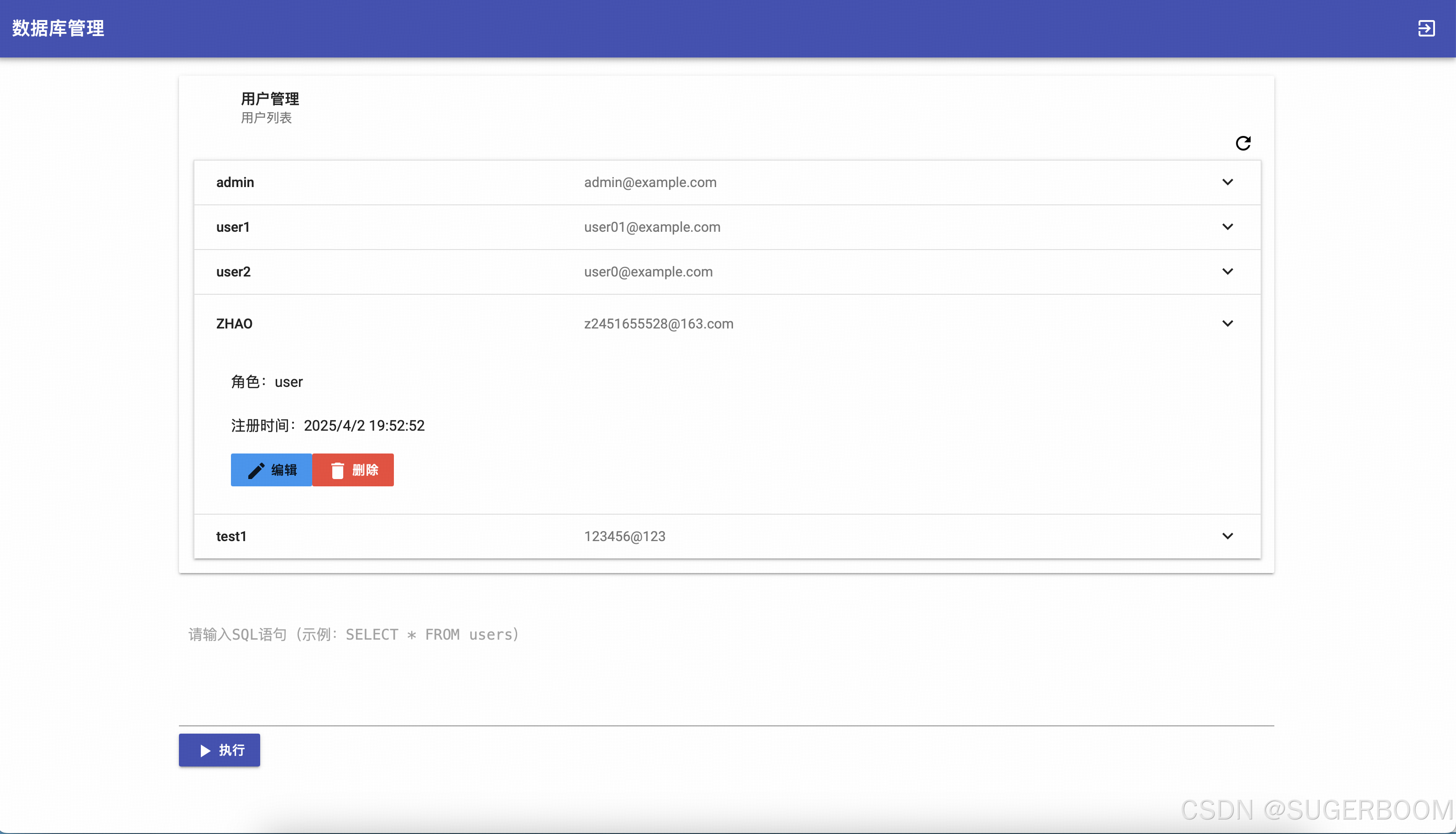
管理员页面与普通用户不同, 没有金融数据分析功能,可以理解为“管理员可以拥有两个账号”,其一与普通用户无异,其二为单独的数据库管理账号,专门进行数据库的增删改查。
可以在下方的SQL执行栏中输入SQL语句以执行更加复杂的筛选查询操作,此次我们以最简单的select * from users为例
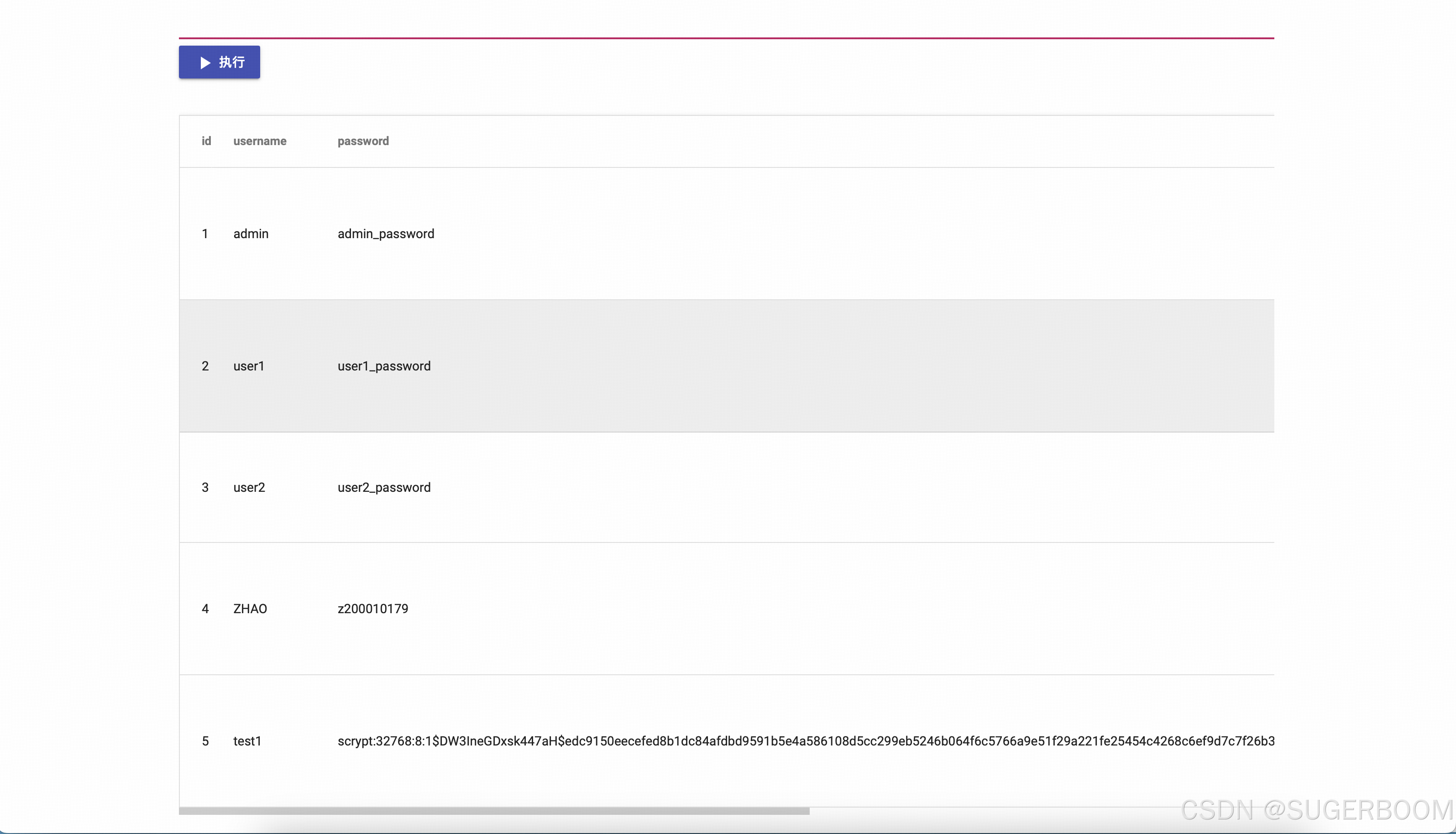
可以看到,除了初试的几个特定账号,通过“注册”得到的test1 密码为加密状态。
六、结语
至此,本项目构建完毕,现在是4月16日18:10,整个项目构建历时近两个月,其间从构思到搭建再到整体方向大修改,抛弃原有的数据库存储逻辑转而使用字典快速更新响应。系统基本是工作之余抽空完成,但整体完成度还算可以。
我没有选择读研,这大概率是我人生中唯一一次毕设经历,做到这种程度,知道对于我目前来说,不会有什么后悔:)
PS:高坚果和朋友们合伙创办了知识分享社群,里面会分享行业前沿消息、技术报告等内容,如果你现在处在找工作的迷茫期,欢迎你来看看(^_^)v
知识星球搜索:应届生Offer收割工厂https://t.zsxq.com/05No5

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









