






链接:https://www.zhihu.com/question/34170804/answer/512837255
https://zhuanlan.zhihu.com/p/46742217
来源:知乎
pointnet全文翻译:https://blog.csdn.net/BatFlo_wsh/article/details/89330195

随着激光雷达,RGBD相机等3D传感器在机器人,无人驾驶领域的广泛应用。针对三维点云数据的研究也逐渐从低层次几何特征提取(PFH,FPFH,VFH等)向高层次语义理解过渡(点云识别,语义分割)。与图像感知领域深度学习几乎一统天下不同,针对无序点云数据的深度学习方法研究则进展缓慢。分析其背后的原因,不外乎三个方面:
1.点云具有无序性。受采集设备以及坐标系影响,同一个物体使用不同的设备或者位置扫描,三维点的排列顺序千差万别,这样的数据很难直接通过End2End的模型处理。
2.点云具有稀疏性。在机器人和自动驾驶的场景中,激光雷达的采样点覆盖相对于场景的尺度来讲,具有很强的稀疏性。在KITTI数据集中,如果把原始的激光雷达点云投影到对应的彩色图像上,大概只有3%的像素才有对应的雷达点。这种极强的稀疏性让基于点云的高层语义感知变得尤其困难。
3.点云信息量有限。点云的数据结构就是一些三维空间的点坐标构成的点集,本质是对三维世界几何形状的低分辨率重采样,因此只能提供片面的几何信息。
其实多视角图片和体素化的方法都有着相似的中心思想,就是希望通过将点云变换成规则化的、可以通过CNN直接进行处理的形式。而直接对点云进行处理的深度学习方法跟上述两种方法最大的不同就是,它是可以直接使用这些三维点的位置信息的。在这方面比较有代表性的就是PointNet方法。
PointNet主要是解决了两个核心问题:点云的无序化和物体姿态变换的不变性。
1)由于点云是无序的,那么最基本的就是需要保证的就是网络对同一点云的不同输入顺序的不变性,PointNet的解决方案是使用一个比较简单的对称函数,如图所示:
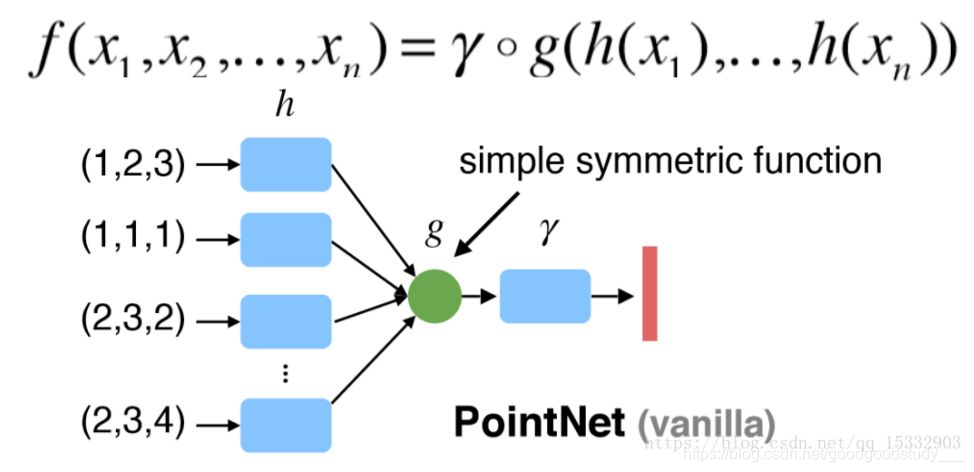
其中h是特征提取函数,在PointNet中就是MLP,g就是对称函数,可以是max、average等函数,在PointNet中用的是max函数,γ则代表的是网络更高层的特征提取函数。
2)在解决点云的无序性问题之后,还有一个非常重要的问题,那就是点云的旋转不变特性,点云在旋转过后的类别是不会发生改变的,所以PointNet在这个问题上参考了二维深度学习中的STN[5]网络,在网络架构中加入了T-Net网络架构,来对输入的点云进行空间变换,使其尽可能够达到对旋转的不变性。
PointNet架构
面对以上困难,来自斯坦福大学的学者提出了PointNet,给出了自己的的解决方案。PointNet是第一种直接处理无序点云数据的深度神经网络。一般情况下,深度神经网络要求输入信息具有规范化的格式,比如二维的图像,时序性的语音等。而原始的三维点云数据往往是空间中的一些无序点集,假设某一个点云中包含N个三维点,每一个点用(x,y,z)三维坐标表示,即使不考虑遮挡,视角等变化,单就这些点的先后顺序排列组合,就有N!种可能。因此,我们需要设计一个函数,使得函数值与输入数据的顺序无关。实际上,在代数组合学中,这类函数被称为对称函数。PointNet中,作者使用了Max Pooling层做为主要的对称函数,这种处理虽然简单,但是实验证明效果较好。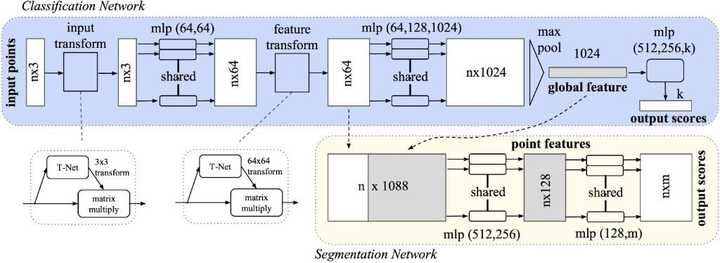
上图是PointNet的网络架构,输入是包含n个点的三维点云(nx3),原始数据通过一个3D空间变换矩阵预测网络T-Net(3),估计出3x3的变换矩阵T(3)并作用在原始数据上,实现数据的对齐。对齐后的数据会以点为单位,通过一个共享参数的双层感知机模型进行特征提取。每个点提取出64维的特征,再通过特征空间变换矩阵预测网络T-Net(64)预测64x64的变换矩阵,作用到特征上,实现对特征的对齐。然后继续利用三层感知机(64,128,1024)进行以特征点为单位的特征提取,直到把特征的维度变为1024,继而在特征空间的维度上进行Max Pooling,提取出点云的全局特征向量。在点云分类任务中,可直接利用特征向量训练SVM或者多层感知机来进行分类,而在以点为单位的点云分割或者分块任务中,需要结合每一点的局部特征和全局特征进行特征融合和处理,实现逐点的分类。PointNet中把经过特征对齐之后的64维特征看成是点的局部特征,把最后的1024维特征看成是点的全局特征,因此通过一个简单的拼接,把局部和全局的特征捆绑在一起,利用多层感知机进行融合,最后训练分类器实现逐点的分类。
PointNet的整体网络架构中主要使用了MLP层进行特征提取以及T-Net层进行空间变换,并且在求解全局特征(global feature)时使用对称函数g(max pool)。网络支持分类和分割任务,对于分类任务来说,就是输出整个点云的类别,而分割任务则是输出点云中每一个点的分类结果。PointNet在这两种任务中都取得了很好的结果。
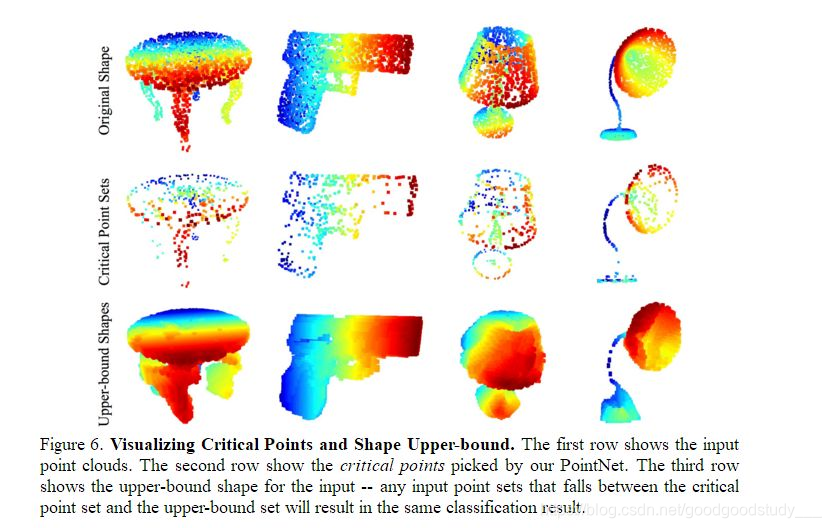
PointNet的实验是非常详细的,其中一个实验是输入网络中的所有的点只输出了一个1*1024的全局特征向量,所以说只有不到1024个关键点的特征使用到了,而论文对全局特征进行了反求,找出了是哪些关键点的特征这个构成了这个全局向量,并将这些点绘制了出来,如图。
PointNet应用
 PointNet是第一个可以直接处理原始三维点云的深度神经网络,这种新颖的网络设计可以直接对原始点云进行处理,进而完成高层次的点云分类和语义分割的任务,而且完全依赖于数据。从实验验证的结果来看,其效果和当前最好的结果具有可比性,在一些方面甚至超过了state-of-the-art.值得进一步挖掘和研究。
PointNet是第一个可以直接处理原始三维点云的深度神经网络,这种新颖的网络设计可以直接对原始点云进行处理,进而完成高层次的点云分类和语义分割的任务,而且完全依赖于数据。从实验验证的结果来看,其效果和当前最好的结果具有可比性,在一些方面甚至超过了state-of-the-art.值得进一步挖掘和研究。
Q&A
Q1:输入的原始三维点云数据需要做归一化吗?
答:和其他网络的输入一样,输入点云数据需要做零均值的归一化,这样才能保证比较好的实验性能。
Q2:深层神经网络处理三维离散点云的难点在哪里?PointNet是如何解决这些难点的?
答:深度神经网络处理三维离散点云数据的难点主要在于点云的无序性和输入维度变化。在本篇文章中,我使用了深度神经网络中的常用对称函数:Max Pooling来解决无序性问题,使用共享网络参数的方式来处理输入维度的变化,取得了比较好的效果。
Q3:是否可以使用RNN/LSTM来处理三维点云数据?
答:RNN/LSTM可以处理序列数据,可以是时间序列也可以是空间序列。因此从输入输出的角度来讲,他们可以用来处理三维点云数据。但是点云数据是无序的,这种点和点之间的先后输入顺序并没有规律,因此直接使用RNN/LSTM效果不会太好。
Q4:T-Net在网络结构中起的本质作用是什么?需要预训练吗?
答:T-Net是一个预测特征空间变换矩阵的子网络,它从输入数据中学习出与特征空间维度一致的变换矩阵,然后用这个变换矩阵与原始数据向乘,实现对输入特征空间的变换操作,使得后续的每一个点都与输入数据中的每一个点都有关系。通过这样的数据融合,实现对原始点云数据包含特征的逐级抽象。
Q5:PointNet与MVCNN的实验结果比较中,有些指标稍差,背后的原因是什么?
答:PointNet提取的是每一个独立的点的特征描述以及全局点云特征的描述,并没有考虑到点的局部特征和结构约束,因此与MVCNN相比,在局部特征描述方面能力稍弱。面对这样的问题,我们基于PointNet已经做了一些改进和提升,新的网络命名为 PointNet++,已经上传到Arxiv,欢迎大家阅读并讨论交流。
PointNet++
虽然PointNet在分类和分割任务上都取得了很好的结果,但是论文指出PointNet存在着非常明显的缺点,那就是PointNet只使用了全局的点云特征,而没有使用局部点附近的特征信息,为了解决这个问题,PointNet++在网络中加入了局部信息提取的方案,并且取得了更好的结果。
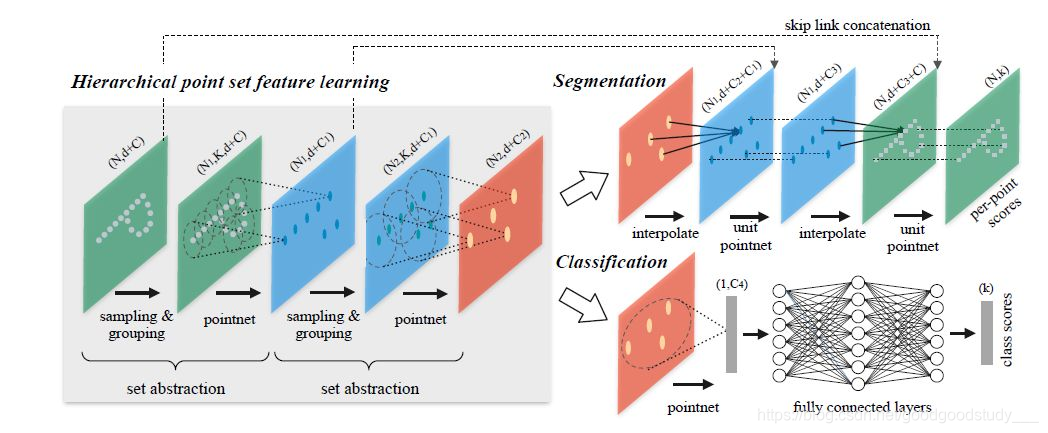
网络最主要的部分就是图7中的set abstraction部分,它首先是先寻找当前点云中的关键点,然后根据距离信息寻找关键点附近的点构成一个小的点集,最后使用PointNet进行特征求解。
通过重复上面的set abstraction部分,便可以不断的对局部点云中进行特征提取,可以使网络更好的利用局部信息。并且实验也证明了PointNet++相对于PointNet有了不小的性能提升。当然网络也使用了MSG和MRG的方法来解决当点云密度不均匀时的采样距离需要改变的问题,具体细节可以查看原论文。
虽然PointNet++达到了更好的效果,但是由于网络加入局部信息之后的不再使用T-net,所以PointNet++有时候存在结果不稳定的情况,所以PointNet++的测试结果是对原始点云进行多次旋转求得的平均结果,可见网络还有很大的改进空间。
最近这段时间也陆续出现了很多很不错的直接处理点云的深度学习论文,在这里就不一一介绍了,对这个方向有兴趣的同学可以去看看,应该会有很大的帮助,例如:PointCNN,PointSift,Graph CNNs等。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









