






Retrieval
发展历史
- 布尔模型
- 矢量空间模型
- 概率模型
- 基于神经网络和深度学习的模型
VSM(Vector Space Model)
矢量空间模型,是一种基于向量空间表示文本的检索模型。
具体做法:
- 预处理:去除停用词、词干化、大小写转换等处理。
- 构建词汇表:对所有文档中的单词进行统计,并选择一部分作为词汇表。
- 生成向量表示:对于每个文档,使用词汇表中的单词生成一个向量表示。这可以通过将每个单词映射到词汇表中的位置,并在该位置处放置单词出现的频率来完成。
- 计算相似度:对于查询文本和文档向量,计算它们之间的余弦相似度。余弦相似度是两个向量之间的夹角的余弦值,用来衡量它们之间的相似程度。
这种方法的优点是简单易懂,易于实现,并且可以处理大量的文本数据。缺点是没有考虑单词的语义信息和上下文,导致在处理一些语义相关性强的文本时效果不佳。因此,后来的方法通常会使用深度学习等技术来获取更好的向量表示。
缺点:
- 词义消歧问题:矢量空间模型中的每个词都被表示为一个向量,但在某些情况下,同一个词可能有不同的含义,而这些含义在向量表示中并没有被区分开来。
- 维度灾难问题:在矢量空间模型中,每个文档都被表示为一个高维向量,当文档集合变得越来越大时,所需的存储空间和计算成本也会越来越高。
- 次要词问题:在矢量空间模型中,一些常见的词如“the”、“a”、“an”等对文本检索结果并没有太大的影响,但它们在向量表示中仍然会占据较大的权重,从而影响文本检索的准确性。
- 无法处理长文本问题:由于矢量空间模型中每个文档都被表示为一个向量,而向量的维度通常与词表大小相同,因此当文档长度较长时,文档的向量表示可能会变得非常稀疏,从而影响文本检索的准确性。
BM25
介绍
- BM25是一种常用的文本检索模型,属于基于概率的模型。它在文档中寻找包含查询项的最佳匹配,并返回这些匹配文档的排名。BM25的基本假设是,查询词项与文档词项的关联性并不完全相同,而是符合贝叶斯公式中的独立性假设。具体来说,BM25将查询项的权重作为一个与查询项频率成正比的增长函数,同时还考虑了查询项在文档中出现的频率和文档的长度等因素。
具体做法
- 对于给定的查询,首先需要确定查询项和文档中词项之间的匹配情况。这一步通常使用分词器将查询和文档分别分成单词,然后比较它们的重叠程度。
- 计算每个查询项的权重。BM25使用一种称为逆文档频率(IDF)的度量来衡量查询项的重要性。具体来说,IDF值反映了查询项在文档集合中的普遍性,如果一个查询项在大部分文档中都出现了,那么它的IDF值就会很低。反之,如果一个查询项只在一小部分文档中出现,那么它的IDF值就会很高。
- 计算文档的匹配度得分。BM25将每个查询项的权重乘以查询项在文档中出现的频率,并使用一个增长函数将得分进行归一化。这个增长函数的作用是将得分从0到1进行缩放,同时对于在文档中出现次数较多的查询项,它的作用会比出现次数较少的查询项更小。
- 根据得分对文档进行排序。计算出每个文档的匹配得分后,需要将它们按得分从高到低进行排序,以便将最相关的文档呈现给用户。
优点
- BM25 的主要优点是它对词项权重的计算比较精细,考虑了文档的长度和词项的文档频率,可以更好地度量查询和文档之间的相关性。此外,BM25 也相对简单易于实现,被广泛应用于信息检索领域。
缺点
- BM25 假设各个词项之间是独立的,但实际上词项之间可能存在相关性,这可能导致模型在一些情况下的效果并不理想。
- BM25 仅考虑了词项在文档中的出现情况,并未考虑词项的语义信息。对于一些需要考虑语义信息的检索任务,BM25 的效果可能较差。
- 对于长查询,BM25 的表现可能不如其他一些方法,因为长查询中可能包含许多不重要的词项,这些词项可能会影响结果的准确性。
单词分数
-
单词
和query之间的相关性
-
当query很长时,我们还需要刻画单词与query的之间的权重。对于短的query,这一项不是必须的。
这里
表示单词t在query中的词频,
是一个可调正参数,来矫正query中的词频范围。
-
-
query中每个单词
- BM25的设计依据一个重要的发现:词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的相关性分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响就不在线性增加了,而这个阈值会跟文档本身有关。因此,在刻画单词与文档相似性时,BM25是这样设计的:
S ( q i , d ) = ( k 1 + 1 ) t f t d k 1 ( 1 − b + b ∗ L d L a v g ) + t f t d S(q_i,d) = \frac{(k_1+1)tf_{td}}{k_1(1-b+b\ast\frac{L_d}{L_{avg}})+tf_{td}} S(qi,d)=k1(1−b+b∗LavgLd)+tftd(k1+1)tftd
-
每个单词的权重
-
单词的权重最简单的就是用idf值
其中N表示索引中全部文档数,
为包含了
-
-
完整公式
于是最后的公式为:
基于神经网络和深度学习的模型
DPR (Dense Passage Retrieval)
DPR(Dense Passage Retrieval)是一种基于双塔架构的检索方法,它使用编码器-解码器结构和密集表示,以在候选文本和查询之间建立更紧密的匹配。DPR可以在密集嵌入空间中直接比较查询和文档,而无需借助词袋模型。具体来说,DPR使用两个神经网络模型:文档编码器和查询编码器,它们分别将文档和查询转换为嵌入向量。DPR使用负例采样和交叉损失函数来训练模型,使得查询与其相关的文档在嵌入向量空间中更加接近,而与不相关的文档则更加远离。
DPR的关键创新点在于采用了密集嵌入向量表示,并通过双塔架构实现了end-to-end的训练和检索。这些创新使得DPR比传统基于词袋模型的检索方法更具优势,特别是在一些复杂的自然语言场景中。DPR在多个自然语言处理任务中得到了广泛的应用,包括问答、文档检索、对话系统等。
Dual-encoder
本文采用了一个dual-encoder的框架,可以理解为一个双塔结构,一个encoder
E
P
(
⋅
)
E_P(⋅)
EP(⋅) 专门对passage进行表示,另一个encoder
E
Q
(
⋅
)
E_Q(⋅)
EQ(⋅) 专门对question进行表示,然后我们使用内积来表示二者的相似度:
s
i
m
(
p
,
q
)
=
E
P
(
p
)
⋅
E
Q
(
q
)
sim(p,q) = E_P(p) ⋅ E_Q(q)
sim(p,q)=EP(p)⋅EQ(q)
损失函数
每个训练样本,都是由1个question,1个positive passage和n个negative passage构成的。positive就是与问题相关的文本,negative就是无关的文本。
用一个样本中每个passage(n+1个)和当前question的相似度作为logits,使用softmax对logits进行归一化,就可以得到每个passage与当前question匹配的概率,由此就可以设计极大似然损失——取positive passage的概率的负对数,相当于cross-entropy loss。
负样本选择
在上面的损失函数中,我们发现负样本起着重要的作用。另外,正样本一般都是确定的,而负样本的选择则是多种多样的,所以负样本怎么选,对结果应该有很大的影响。
作者设计了三种负样本(negative passage)选择的方式:
- Random:从语料库中随机抽取一个passage,基本上都是跟当前question无关的;
- BM25:使用基于BM25的文本检索方式在语料库中检索跟question最相关的文本,但要求不包含答案;
- Gold:在训练样本中,其他样本中的positive passage。即对于训练样本i 和j ,qi 对应的正样本是p+i ,而这个p+i 可以作为qj 的负样本。
既然都命名为Gold了,那说明作者对它给予了厚望,肯定是主要的负样本来源。
论文最终的最佳实践,就是主要采用同一个mini-batch中的Gold passages,配合上一个BM25 passage(以及同batch内其他question的BM25)。
In-batch negatives
假设我们的batch size为B,每个question有1个positive和n个negative,那么一个batch内就有B×(n+1) 个passages要经过encoding,而一般我们都需要比较多的negatives才能保证较好的效果,所以光是encoding,这个计算开销就很大。
于是,有人就想出了一个办法,我们只需要B个questions和其对应的B个positives,形成两个矩阵Q 和P ,然后“我的positive,可以当做你的negative”,这样我们就不需要额外再找negative了,然后直接算一个 S = Q P T S=Q^PT S=QPT 就可以得到计算损失函数所需要的所有pair的相似度,这就使得整个过程变得高效又简洁。由于不需要额外找negatives,所以一个batch内只有B 个positive passages需要经过encoding,这比前面的方法减少了n+1倍。
Duet
Duet是一种基于深度学习的信息检索模型,旨在提高传统文本检索系统的性能。它最初由微软研究院的工程师提出,由两个子模型组成:
- 一个是基于卷积神经网络的局部模型。
- 另一个是基于长短期记忆网络的全局模型。
Duet是一种基于深度学习的信息检索模型,旨在提高传统文本检索系统的性能。它最初由微软研究院的工程师提出,由两个子模型组成:一个是基于卷积神经网络的局部模型,另一个是基于长短期记忆网络的全局模型。
这两个网络作为单个神经网络的一部分被联合训练。
local 模型进行精确匹配,分布式模型进行 同义词,相关术语或者语义匹配。
在这篇论文中,作者提出了三种高效的IR的匹配属性
- exact match :这是IR的基础
- match positions :相关文档中的查询词匹配比非相关文档中的匹配更具聚类性。
- inexact term matches:解决词汇不匹配问题,exact match 的致命问题是忽略了query的相关词,比如对于query :Australia , 会忽略Sydney’ and ‘koala’ 。这对于IR来说绝对不是一个好的策略
Architecture
分布式模型在匹配之前将查询和文档文本投影到嵌入空间中,而本地模型在交互矩阵上操作,将每个查询项与每个文档项进行比较。最终分数是来自本地和分布式网络的分数之和
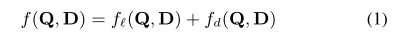
其中查询和文档都被认为是术语的有序列表
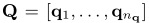
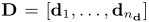
input的fixed:quert:10 ,doc:1000
Local Model
Local model是一个深度神经网络,它使用精确的术语匹配来匹配查询和文档。它可以精确的匹配位置和接近度。它是本文提出的模型架构的两个子网络之一。本地模型将查询和文档的交互矩阵作为输入,并将其传递给深度学习模型以产生相关性得分。交互矩阵基于文档中查询词的精确匹配模式。
query 和 document 的term用one-hot表示,然后计算exact match矩阵:
X = D T Q X = D^TQ X=DTQ
Distributed Model
- Distributed Model是一个基于表征的匹配模型,它使用神经嵌入学习文本的分布式表示,然后在嵌入空间中计算查询和文档之间的相关性。
- Distributed Model包括两个子网络:一个用于查询嵌入,一个用于文档嵌入。这两个子网络都是多层感知器(MLP),它们将词向量作为输入,并输出一个低维向量作为查询或文档的嵌入。
- Distributed Model使用余弦相似度作为查询和文档嵌入之间的匹配函数,并将其作为最终得分输出。
Optimization
每一组训练样本由一个查询Q,一个相关文档
D
∗
D^*
D∗和一组不相关文档
N
=
D
1
,
D
2
,
.
.
.
,
D
N
N={D_1,D_2,...,D_N}
N=D1,D2,...,DN组成。使用softmax函数根据分数计算给定查询的肯定文档的后验概率,然后最大化
log
p
\log p
logp即可:

Colbert
ColBERT 基于 BERT 模型,使用双塔结构来对查询和文档进行编码,然后使用交叉注意力机制来实现查询和文档之间的后期交互。
它采用了离线索引和在线重排的策略,可以大幅度减少在线检索时的计算量和响应时间。ColBERT 还提出了 Quality-Effective Ranking(QER)框架,实现了检索质量和响应时间之间的平衡。在各种信息检索任务中,ColBERT 都取得了优秀的性能
- ColBERT是一种高效且有效的文本检索方法,基于BERT模型和细粒度相似度计算
- ColBERT的动机是解决预训练语言模型在信息检索上的计算成本和性能问题
- ColBERT的核心思想是将查询和文档分别用BERT编码,然后用一个简单而强大的交互步骤来建模它们的细粒度相似度
- ColBERT可以利用深度语言模型的表达能力,同时保持可扩展性和高效性

Architecture
- Query & Document Encoders
- 采用了双塔结构,将查询和文档分别表示为两个向量空间中的向量,然后计算它们之间的相似度得分。
- Late Interaction
- 用于实现查询和文档之间的后期交互。这个交互在 ColBERT 模型中被称为“后期交互”
- ColBERT 模型使用一个多头注意力层,计算该词语与查询中的每个词语之间的注意力得分。这个注意力得分表示了查询和文档之间的相似度得分,用于后续的文档排序。
- 通过交叉注意力机制实现了查询和文档之间的后期交互,从而更好地捕捉到查询和文档之间的语义相似性。
- Offline Indexing: Computing & Storing Document Embeddings
- 它主要用于预先计算和存储文档的向量表示,以加速在线查询时的响应速度。
- 一旦所有文档的向量表示被计算出来,ColBERT 模型就可以使用这些向量来建立一个倒排索引(Inverted Index)。这个倒排索引可以将每个单词与包含该单词的所有文档相关联。这样,在查询时,模型可以首先根据查询中包含的单词从倒排索引中获取相关文档的编号,然后根据这些文档的向量表示计算它们与查询之间的相似度得分,并进行排序。
- 它通过离线计算和存储文档的向量表示,并建立倒排索引,以加速在线查询时的响应速度。
- Top-k Re-ranking with ColBERT
- 利用基于向量空间模型的传统方法,根据查询和文档之间的余弦相似度得分,得到一个初始的文档候选集合。
- 利用 ColBERT 模型对这个候选集合进行重新排序,以得到更准确的文档排序结果。
- ColBERT 模型在计算相似度得分时,使用了 Late Interaction 技术,从而更好地捕捉到查询和文档之间的语义关系。最终,模型根据文档与查询之间的相似度得分,对文档进行重新排序,以得到最终的排序结果。
- End-to-end Top-k Retrieval with ColBERT
- 它将 Query & Document Encoders 和 Top-k Re-ranking 两个组成部分结合在一起,形成了一个端到端的信息检索框架。
结论:
ColBERT引入了一种后期交互体系结构,这种体系结构使用类BERT独立的对查询和文档进行编码,再使用一种廉价而且强大的交互步骤去建模它们的细粒度的相似性。通过延迟并保留这种细粒度的相似性,获得离线预先计算文档表示的能力,大大加快查询的速度。
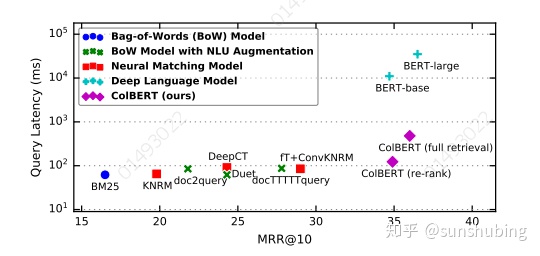
不同的检索模型对比:

(a)展示了基于表示的排名器,它们独立计算查询 q 和文档 d 的嵌入,并将相关性估计为两个向量之间的单一相似度分数。
(b)可视化了典型的基于交互的排名器。这些排名器不将 q 和 d 概括为单个嵌入,而是通过深度神经网络(例如,使用 CNN / MLP )对 q 和 d 之间的单词和短语级别关系进行建模并匹配。在最简单的情况下,它们将交互矩阵馈送给神经网络,该矩阵反映了 q 和 d 之间每对单词之间的相似度。
(c)展示了一种更强大的基于交互的范式,它同时对 q 和 d 内部以及之间的单词相互作用进行建模。
(d) 展示了ColBERT中的“延迟交互”模型,该模型将查询和文档分别编码为两个上下文嵌入集,并使用快速计算来评估它们之间的相关性。该方法不需要枚举所有可能的候选项,从而实现了高效排序。与交互聚焦排名模型不同,它不需要先计算查询和文档中所有单词和短语之间的相似性,因此更具有可扩展性。
Encoder
- 对于query和doc都是用同一个模型,区别在query和document前分别加入[Q]和[D]token以此来区分。
- query encoder:每个token经过BERT后,将输出的上下文表示通过一个没有激活函数的线性层传递上下文化的输出表示。输出维度是n维,n是远远小于bert隐藏层维度的。
- 这一步主要为了控制文档和查询的嵌入的占用空间和执行效率,虽然这样做会在一定程度上影响嵌入的质量。
- document encoder:同是BERT的encoder,与query encoder不同之处在于不额外的使用[mask] token。并且过滤掉文档中的标点符号的嵌入(作者认为标点符号的嵌入对于检索的有效性是不必要的,这里的操作是根据一个预先定义的标点符号列表进行过滤)
- query encoder:每个token经过BERT后,将输出的上下文表示通过一个没有激活函数的线性层传递上下文化的输出表示。输出维度是n维,n是远远小于bert隐藏层维度的。

- 训练:给定带有查询q,正样本和负样本各一个,Colbert为两个样本各生成一个分数,并使用交叉熵损失函数进行优化。
延迟交互
- 就是在编码阶段都是各自独立的,通过BERT的encoder学习到上下文中包含的语义信息
- E q E_{q} Eq代表了一个查询的向量表达,而 E q i E_{q_i} Eqi则是这个查询中某一个token的向量表达, E d E_d Ed所代表的含义也是一样的。
- 对于每一个查询 E q E_q Eq,都会对其token进行遍历,拿到的 E q i E_{q_i} Eqi和特定文档的每一个 E d i E_{d_i} Edi都进行相似度计算,挑出max的相似度作为当下 E q i E_{q_i} Eqi的相似度分数,将 E q E_{q} Eq每一个token的分数都加起来,就是当下Eq和Ed的相似度分数。
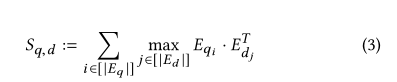
对于Colbert的MaxSim来说,计算MaxSim就是从文档中挑选出与查询向量的每一个token最相似的那一小部分向量,与之计算相似度,得到分数,最大分数进行求和,就是得到的分数。
验证:
- 使用MRR(平均倒数排名)
- 首先使用Colbert获取分数最高的k个文档,并由高到低排名
- 将文档中最先出现的正确文档的下标,也就是名次记录下来并取倒数。
- 将各个查询的倒数排名加起来就是MRR。
- 之所以是倒数是因为排名是越小越好,那么取倒数之后,最后的指标就是越接近1越好,所以要取倒数。
对于Colbert的MaxSim来说,计算MaxSim就是从文档中挑选出与查询向量的每一个token最相似的那一小部分向量,与之计算相似度,得到分数,最大分数进行求和,就是得到的分数。
验证:
- 使用MRR(平均倒数排名)
- 首先使用Colbert获取分数最高的k个文档,并由高到低排名
- 将文档中最先出现的正确文档的下标,也就是名次记录下来并取倒数。
- 将各个查询的倒数排名加起来就是MRR。
- 之所以是倒数是因为排名是越小越好,那么取倒数之后,最后的指标就是越接近1越好,所以要取倒数。















 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









