







 本文详细介绍了图像处理中的卷积与反卷积技术,包括卷积的不同类型(full、same、valid)及其计算公式,阐述了反卷积的概念与应用场景,并探讨了池化层的作用及多种池化方法。
本文详细介绍了图像处理中的卷积与反卷积技术,包括卷积的不同类型(full、same、valid)及其计算公式,阐述了反卷积的概念与应用场景,并探讨了池化层的作用及多种池化方法。
感谢博主:http://blog.csdn.net/fate_fjh/article/details/52882134
1.前言
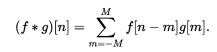
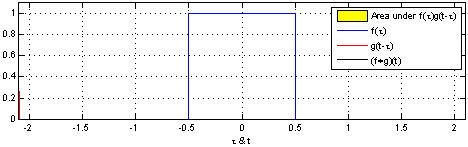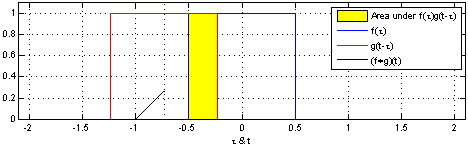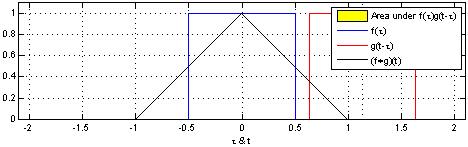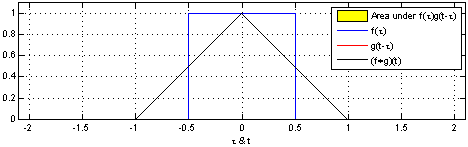
2.图像卷积
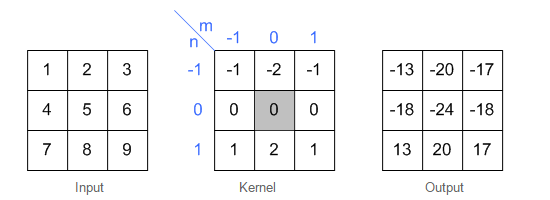

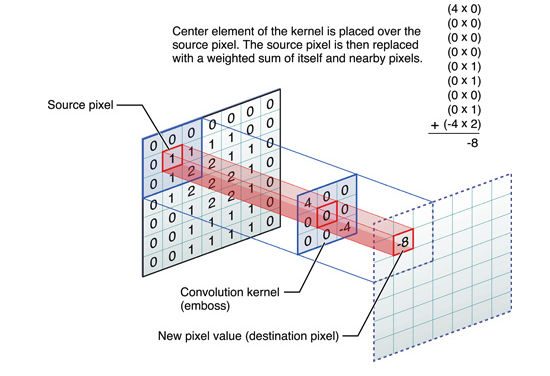
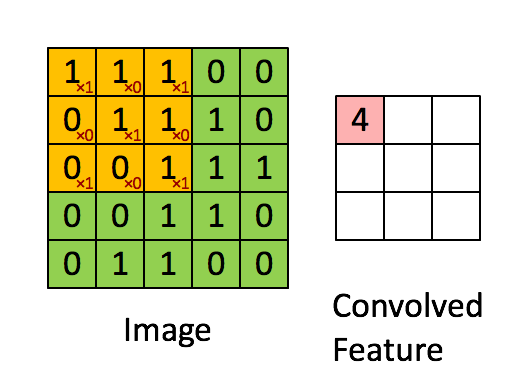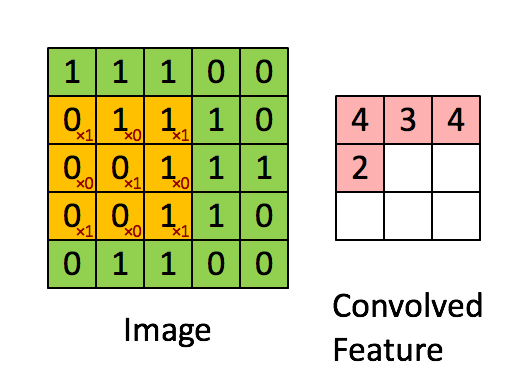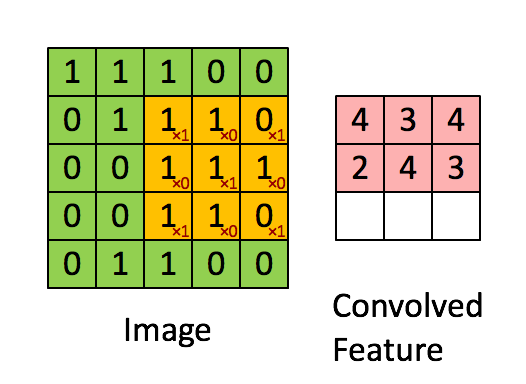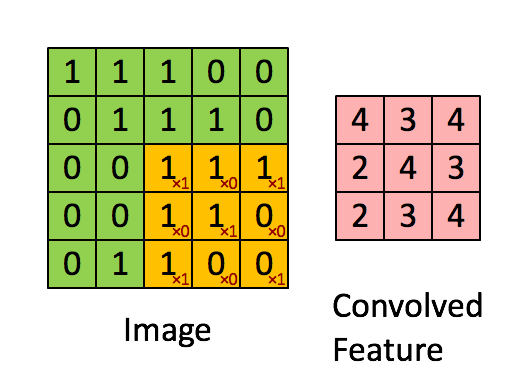
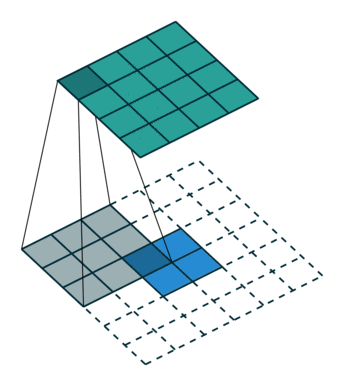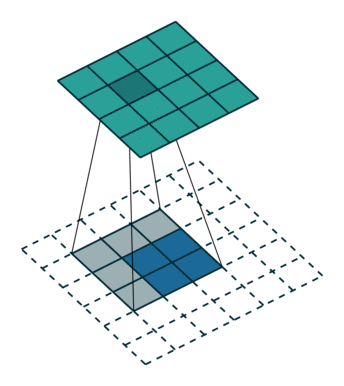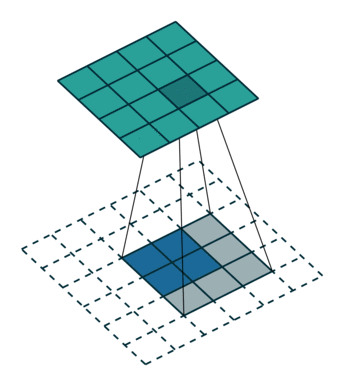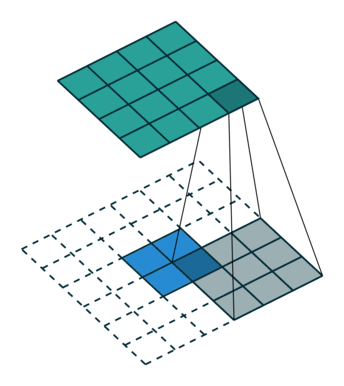
图6中蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图6的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积。下面是WIKI对应图像卷积后多出部分的解释:
Kernel convolution usually requires values from pixels outside of the image boundaries. There are a variety of methods for handling image edges.意思就是多出来的部分根据实际情况可以有不同的处理方法。(其实这里的full卷积就是后面要说的反卷积)
3.反卷积(后卷积,转置卷积)
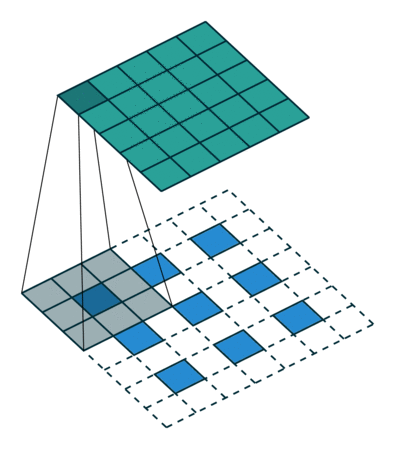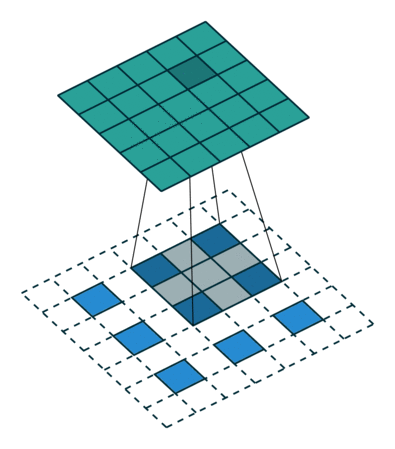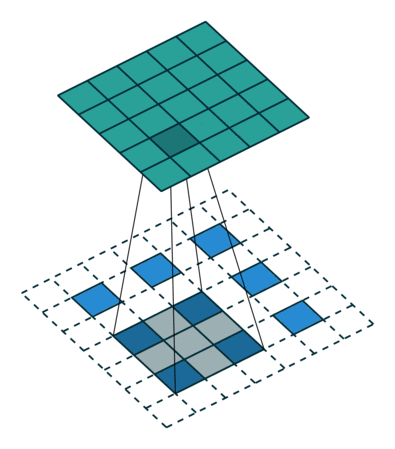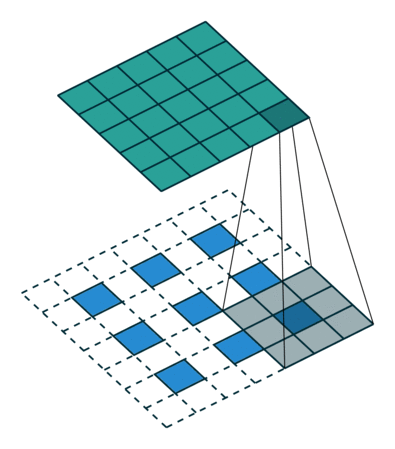
补充一个资料:
图6与图7出处,https://github.com/vdumoulin/conv_arithmetic
------------新增反卷积过程解释----------------
经过上面的解释与推导,对卷积有基本的了解,但是在图像上的deconvolution究竟是怎么一回事,可能还是不能够很好的理解,因此这里再对这个过程解释一下。
目前使用得最多的deconvolution有2种,上文都已经介绍。
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
方法2:记录pooling index,然后扩大空间,再用卷积填充
图像的deconvolution过程如下,
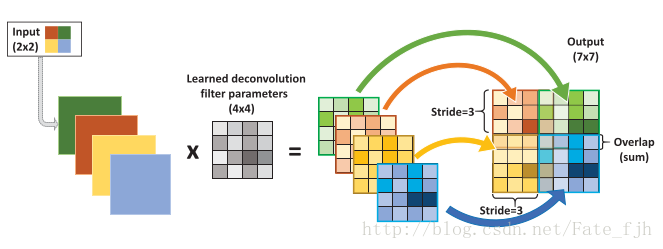
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出翻卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
一 池化的过程
卷积层是对图像的一个邻域进行卷积得到图像的邻域特征,亚采样层(池化层)就是使用pooling技术将小邻域内的特征点整合得到新的特征。
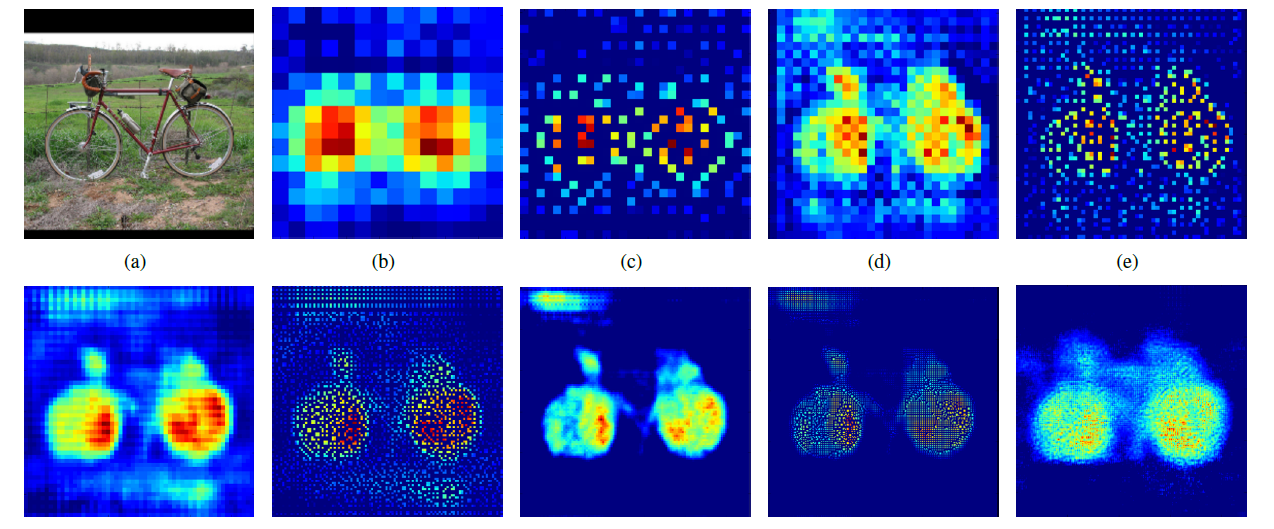
在完成卷积特征提取之后,对于每一个隐藏单元,它都提取到 (r-a+1)×(c-b+1)个特征,把它看做一个矩阵,并在这个矩阵上划分出几个不重合的区域,然后在每个区域上计算该区域内特征的均值或最大值,然后用这些均值或最大值参与后续的训练,这个过程就是池化。
二 池化的优点
| 1 显著减少参数数量 |
通过卷积操作获得了图像的特征之后,若直接用该特征去做分类则面临计算量的挑战。而Pooling的结果可以使得特征减少,参数减少。
例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样本都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
| 2 池化单元具有平移不变性 |
pooling可以保持某种不变性(旋转、平移、伸缩等)
三 池化的方式
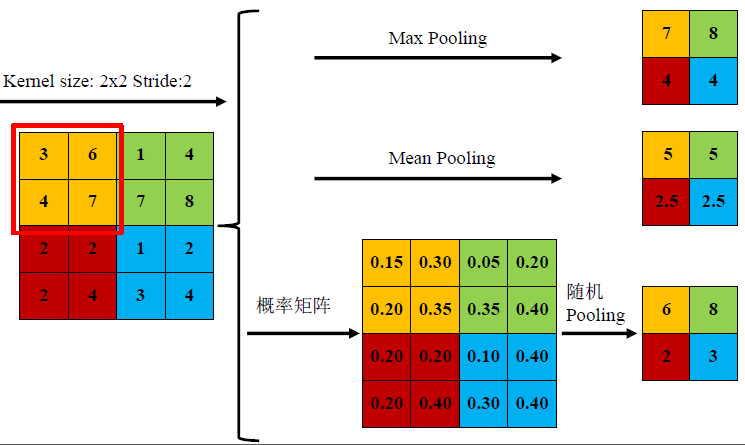
| 1 一般池化(General Pooling) |
1) mean-pooling,即对邻域内特征点只求平均,对背景保留更好;
2) max-pooling,即对邻域内特征点取最大,对纹理提取更好;
3) Stochastic-pooling,介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样;
特征提取的误差主要来自两个方面:(1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
下面给出matlab中max-pooling的代码实现:
function [outputMap, outputSize] = max_pooling(inputMap, inputSize, poolSize, poolStride)
% ==========================================================
% INPUTS:
% inputMap - input map of the max-pooling layer
% inputSize - X-size(equivalent to Y-size) of input map
% poolSize - X-size(equivalent to Y-size) of receptive field
% poolStride - the stride size between successive pooling squares.
% OUTPUT:
% outputMap - output map of the max-pooling layer
% outputSize - X-size(equivalently, Y-size) of output map
% ==========================================================
outputSize = inputSize/ poolStride;
inputChannel = size(inputMap, 3);
padMap = padarray(inputMap, [poolSize poolSize],0, 'post');
outputMap = zeros(outputSize, outputSize, inputChannel, 'single');
for j = 1:outputSize
for i = 1:outputSize
startX = 1 + (i-1)*poolStride;
startY = 1 + (j-1)*poolStride;
poolField = padMap(startY:startY+poolSize-1,startX:startX+poolSize-1,:);
poolOut = max(reshape(poolField, [poolSize*poolSize,inputChannel]),[],1);
outputMap(j,i,:) = reshape(poolOut,[1 1 inputChannel]);
end
end
| 2.重叠池化(Overlapping Pooling) |
重叠池化的相邻池化窗口之间会有重叠区域。该部分详见参考文献[4]
| 3.空间金字塔池化(Spatial Pyramid Pooling) |
空间金字塔池化拓展了卷积神经网络的实用性,使它能够以任意尺寸的图片作为输入。该部分详见参考文献[3]
四 参考文献
[1]池化 http://ufldl.stanford.edu/wiki/index.php/%E6%B1%A0%E5%8C%96
[2]卷积神经网络初探 - Lee的白板报的个人空间 - 开源中国社区 http://my.oschina.net/findbill/blog/550565
[3]池化方法总结http://blog.csdn.net/mao_kun/article/details/50533788
[4] Krizhevsky, I. Sutskever, andG. Hinton, “Imagenet classification with deep convolutional neural networks,”in NIPS,2012.
[5]http://yann.lecun.com/exdb/publis/pdf/boureau-icml-10.pdf
[6]http://yann.lecun.com/exdb/publis/pdf/boureau-cvpr-10.pdf
[7]http://yann.lecun.com/exdb/publis/pdf/boureau-iccv-11.pdf
[8]http://ais.uni-bonn.de/papers/icann2010_maxpool.pdf

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









