







C# Task.Yield
最近在阅读 .NET Threadpool starvation, and how queuing makes it worse (.NET线程池耗尽,以及队列如何使其变得更糟)这篇博文时发现文中代码中的一种 Task 用法之前从未见过。
下面代码中的 await Task.Yield() :
static async Task Process()
{
await Task.Yield();
var tcs = new TaskCompletionSource<bool>();
Task.Run(() =>
{
Thread.Sleep(1000);
tcs.SetResult(true);
});
tcs.Task.Wait();
}(注:上面的代码不是示例,只是因为这段代码而初遇 await Task.Yield)
Task.Yield 简单来说就是创建时就已经完成的 Task ,或者说执行时间为0的 Task ,或者说是空任务,也就是在创建时就将Task 的 IsCompeted 值设置为0。
那 await 一个空任务会怎样?我们知道在 await 时会释放当前线程(假设为ID 6),等所 await 的 Task 完成时会从线程池中申请新的线程( 说明一点,新的线程有可能和之前的线程(ID 6)一样)继续执行 await 之后的代码,这本来是为了解决异步操作(比如IO操作)霸占线程实际却用不到线程的问题,而 Task.Yield 却产生了一个不仅没有异步操作而且什么也不干的 Task ,不是吃饱了撑着吗?
今天吃晚饭的时候终于想明白了——吃饱了没有撑。Task.Yield 产生的空任务仅仅是为 await 做嫁衣,而真正的图谋是借助await 实现线程的切换,让 await 之后的操作重新排队从线程池中申请线程继续执行。
这样做有什么好处呢?
线程是非常非常宝贵的资源,千金难买一线程,而且有优先级,提高线程利用率的重要手段之一就是及时将线程分配给最需要的地方,而最奢侈的之一是让一个优先级低执行时间长的操作一直占用着一个线程,await Task.Yield 可以让你巧妙地借助 await的线程切换能力,将不太重要的比较耗时的操作放在新的线程(重新排队从线程池中申请到的线程)中执行。打个比方,很多人排队在外婆家就餐,你来的时候比较巧,正好有位置,但你本来就不着急肚子也不太饿准备慢慢吃慢慢聊,而排队的人当中有些人很饿很着急吃完还有事,这时你如果先点几个招牌菜解解馋,然后将座位让出来,重新排队,并且排队的人当中像你这样的都这么做,那些排队中心急如焚的人真是是幸福感爆棚,外婆家的老板也笑弯了腰。你让出座位重新排队的爱心行为就是await Task.Yield() 。
C# async、await本质
在C#中,async和await关键字是用于编写异步代码的特殊语法。它们的本质是基于任务(Task)和状态机的异步编程模式。
首先,使用async关键字修饰的方法表示一个异步方法,它可以在方法内部使用await关键字来等待一个异步操作的完成。当遇到await关键字时,方法会暂时挂起,并将控制权返回给调用方,让后续的代码可以继续执行。await关键字主要有两个作用:
-
等待异步操作完成:
await表达式会等待一个实现了Task或Task<T>类型的异步操作完成,并获取其结果。在等待期间,方法会暂停执行,直到异步操作完成为止。 -
返回异步操作的结果:
await表达式会将异步操作的结果返回给调用方,而不是一个封装异步操作的Task对象。这使得异步方法可以像同步方法一样使用返回值进行处理,而无需显式地处理Task。
在编译时,编译器会通过生成状态机来管理异步方法的状态和控制流。这个状态机会记录方法的执行上下文,并在异步操作完成后恢复方法的执行。这样,使用await关键字的方法可以在异步操作完成后继续执行,保持方法执行的顺序和同步代码类似。
总结来说,async和await本质上是使用基于任务和状态机的异步编程模式来简化异步代码的编写和管理。它们提供了一种更直观、易于理解的方式来处理异步操作,使得异步编程变得更加简单和可读性更高。
C# yield关键字
在C#中,yield关键字用于生成可枚举集合或迭代器。它的主要作用是在一个方法或属性中定义一个迭代器块,通过逐步返回序列中的元素来简化集合的遍历。
使用yield关键字定义的方法或属性被称为迭代器方法(Iterator Methods),它们可以用于创建一个实现了IEnumerable<T>接口的集合,或者返回一个实现了IEnumerator<T>接口的迭代器。
以下是yield关键字的一些特点和用法:
-
延迟执行:
yield语句使得集合元素按需生成,只有在迭代器通过调用MoveNext()方法请求下一个元素时,才会执行yield语句并产生下一个元素。这种延迟执行的特性可以在处理大型数据集或无限序列时提供性能优势。 -
简化编写:使用
yield关键字可以将集合的遍历逻辑与生成元素的逻辑分离开来,从而简化代码的编写。通过在迭代器方法中使用yield return语句,可以方便地逐个返回集合中的元素,而不需要显式地维护状态和索引。 -
支持迭代器块:
yield关键字可以用在循环内部,允许在每次循环迭代时返回一个元素。这使得可以根据需要生成不同的元素,而无需将它们全部存储在内存中。 -
只读访问:生成的集合或迭代器是只读的,只能通过迭代器进行顺序访问,不能修改集合中的元素。
下面是使用yield关键字定义迭代器方法的示例:
public IEnumerable<int> GetNumbers()
{
yield return 1;
yield return 2;
yield return 3;
}在上面的示例中,GetNumbers()方法是一个迭代器方法,通过使用yield return语句返回三个整数。通过调用该方法并使用foreach循环,可以逐个访问生成的元素:
foreach (var number in GetNumbers())
{
Console.WriteLine(number);
}以上代码将依次输出1、2和3。
总而言之,yield关键字提供了一种简单且灵活的方式来创建可枚举集合或迭代器,简化了集合的遍历过程,并支持延迟执行和只读访问的特性。
C# yield return 的作用简单说明
简单的说就是记录你上一次执行的位置,等你下次再执行这个函数就会跳到上次的记录点继续执行
using System;
using System.Threading.Tasks;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
Task.Run(async ()=> {
await foreach (var number in GenerateSequence())
{
Console.WriteLine(number);
}
});
Console.Read();
}
public static async System.Collections.Generic.IAsyncEnumerable<int> GenerateSequence()
{
for (int i = 0; i < 20; i++)
{
await Task.Delay(100);
//yield return这个的作用就是每当代码执行到这里的时候返回
//而当GenerateSequence函数再次被调用的时候会从上一次的yield开始接着往下走
yield return i;
//yield break的作用就是提前结束
//当GenerateSequence函数再次被调用会重新开始循环
if (i == 18)
yield break;
}
}
}
}JS yield关键字
在 JavaScript 中,yield 关键字与生成器函数(Generator Function)一起使用。生成器函数是一种特殊类型的函数,可以通过 yield 关键字暂停函数的执行,并返回一个迭代器对象。
下面是关于 yield 关键字的一些说明:
-
生成器函数:生成器函数是一种特殊的函数,通过在函数体内使用
yield关键字可以将函数的执行暂停,同时可以通过调用迭代器对象的next()方法来继续函数的执行。 -
迭代器对象:生成器函数的调用会返回一个迭代器对象,它具有一个
next()方法,用于继续函数的执行并返回一个对象,该对象包含了yield表达式的值和状态信息。 -
暂停和恢复:当生成器函数遇到
yield关键字时,函数的执行会暂停,并将yield表达式右侧的值作为迭代器对象的value属性返回。当再次调用迭代器对象的next()方法时,函数会从上次暂停的位置恢复执行,并继续执行到下一个yield表达式或函数结束。 -
多次迭代:生成器函数可以使用多个
yield关键字来产生一系列的值。每次调用next()方法时,生成器函数会继续执行,直到遇到下一个yield关键字或函数结束。
下面是使用 yield 关键字定义生成器函数的示例:
function* generateNumbers() {
yield 1;
yield 2;
yield 3;
}
const iterator = generateNumbers();
console.log(iterator.next().value); // 输出 1
console.log(iterator.next().value); // 输出 2
console.log(iterator.next().value); // 输出 3在上面的示例中,generateNumbers() 是一个生成器函数,通过使用 yield 关键字分别返回三个数字。通过调用生成器函数并使用迭代器对象的 next() 方法,可以逐个获取生成的值。
需要注意的是,生成器函数以及通过 yield 关键字定义的代码只在调用 next() 方法时才会执行,它们具有惰性求值的特性。这使得生成器函数非常适合处理大型数据集或无限序列,因为它只在需要的时候才会产生值。
总结来说,JavaScript 中的 yield 关键字与生成器函数一起使用,提供了一种更灵活的方式来控制函数的执行和产生迭代器对象。它使得迭代过程可以暂停和恢复,并且能够方便地按需生成值,从而简化了异步编程和处理复杂迭代逻辑的场景。
C# 和 javascript yield关键字区别
在 C# 和 JavaScript 中,yield 关键字具有相似的概念和用途,但在语法和实现上有一些区别。下面是 C# 和 JavaScript 中 yield 关键字的主要区别:
-
语法差异:
- C#:在 C# 中,
yield关键字是作为迭代器块的一部分使用的,用于定义迭代器方法。它以yield return或yield break的形式出现,用于返回一个序列中的元素或终止迭代。 - JavaScript:在 JavaScript 中,
yield关键字是与生成器函数一起使用的,用于暂停函数的执行并返回一个迭代器对象。它以yield的形式出现,用于产生函数的值。
- C#:在 C# 中,
-
迭代器功能不同:
- C#:在 C# 中,通过使用
yield return关键字,可以构建一个实现了IEnumerable<T>接口的可枚举集合或迭代器。这意味着使用foreach循环或 LINQ 查询等方式可以顺序访问生成的元素。 - JavaScript:在 JavaScript 中,通过使用
yield关键字,可以创建一个生成器函数,它返回一个迭代器对象。通过调用迭代器对象的next()方法,可以逐步执行生成器函数,并从yield表达式获取值。
- C#:在 C# 中,通过使用
-
问题领域不同:
- C#:在 C# 中,
yield关键字常用于处理集合的遍历,可以按需生成元素,提供延迟执行和只读访问的能力,适用于处理大型数据集或无限序列等场景。 - JavaScript:在 JavaScript 中,
yield关键字常用于处理异步编程,它可以将函数的执行暂停和恢复,通过生成器函数和迭代器对象的组合,可以便捷地处理复杂的迭代逻辑,适用于处理异步操作、状态机或惰性求值等场景。
- C#:在 C# 中,
需要注意的是,尽管 yield 关键字在 C# 和 JavaScript 中有一些差异,但它们都提供了一种简化代码和处理迭代逻辑的方法。无论是在 C# 还是 JavaScript 中,yield 关键字都使得迭代过程更加灵活和高效。
.NET Threadpool starvation, and how queuing makes it worse
There has been plenty of talk lately about threadpool starvation in .NET:
- https://blogs.msdn.microsoft.com/vancem/2018/10/16/diagnosing-net-core-threadpool-starvation-with-perfview-why-my-service-is-not-saturating-all-cores-or-seems-to-stall
- Azure DevOps Service
- or even on our own blog: Monitor Finalizers, contention and threads in your application - Criteo Engineering
What is it about? This is one of the numerous ways asynchronous code can break if you wait synchronously on a task.
To illustrate that, consider a web server that would execute this code:
You start an asynchronous operation (DoSomethingAsync) then block the current thread. At some point, the asynchronous operation will need a thread to finish executing, so it’ll ask the threadpool for a new one. You end up using two threads for an operation that could be done with just one: one waiting actively on the Wait() method call and another one performing the continuation. In most cases this is fine. But it can become a problem if you deal with a burst of requests:
- Request 1 arrives to the server. ProcessRequest is called from a threadpool thread. It starts the asynchronous operation then waits on it
- Requests 2, 3, 4, and 5 arrive to the server
- The asynchronous operation completes and its continuation is enqueued to the threadpool
- In the meantime, since 4 requests have arrived, 4 calls to ProcessRequest have been enqueued before your continuation
- Each of those requests will in turn start an asynchronous operation and block their threadpool thread
Combined with the fact that the threadpool grows very slowly (one thread per second or so), it’s easy to understand how a burst of requests can push a system into a situation of thread starvation. But there’s something missing in the picture: while the burst could temporarily lock the system, unless the workload is continuously increasing, the threadpool should be capable of growing enough to eventually recover.
Yet, it does not fit what we observed on our own servers. We usually restart our instances as soon as a starvation happens, but in one case we didn’t. The threadpool grew until its hardcoded limit (32767 threads), and the system never recovered:
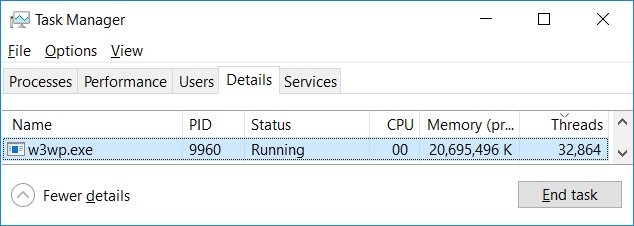
If you do the math, 32767 threads should be more than enough to handle the 1000-2000 QPS that our servers process, even if every request required 10 threads!
It seems there’s something else going on.
The part where things get worse
Let’s consider the following code. Take a minute to guess what will happen:
using System;
using System.Threading;
using System.Threading.Tasks;
namespace Starvation
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(Environment.ProcessorCount);
ThreadPool.SetMinThreads(8, 8);
Task.Factory.StartNew(
Producer,
TaskCreationOptions.None);
Console.ReadLine();
}
static void Producer()
{
while (true)
{
Process();
Thread.Sleep(200);
}
}
static async Task Process()
{
await Task.Yield();
var tcs = new TaskCompletionSource<bool>();
Task.Run(() =>
{
Thread.Sleep(1000);
tcs.SetResult(true);
});
tcs.Task.Wait();
Console.WriteLine("Ended - " + DateTime.Now.ToLongTimeString());
}
}
}Producer enqueues 5 calls to Process every second. In Process, we yield to avoid blocking the caller, then we start a task that will wait 1 second and wait for it. In total, we start 5 tasks per second and each of those tasks will need an additional task. So we need 10 threads to absorb the constant workload. The threadpool is manually configured to start with 8 threads, so we are 2 threads short. My expectations are that the program will struggle for 2 seconds until the threadpool grows to absorb the workload. Then it needs to grow a bit further to process the additional workitems that we enqueued during the 2 seconds. After a few seconds, the situation will stabilize. 生产者每秒为进程排队5个调用。在Process中,我们放弃以避免阻塞调用者,然后我们启动一个将等待1秒的任务并等待它。总的来说,我们每秒启动5个任务,每个任务都需要一个额外的任务。所以我们需要10个线程来吸收恒定的工作负载。线程池被手动配置为从8个线程开始,所以我们少了2个线程。我的预期是,程序将挣扎2秒,直到线程池增长到可以吸收工作负载为止。然后,它需要进一步增长一点,以处理我们在2秒内排队的额外工作项。几秒钟后,情况会稳定下来。
But if you run the program, you’ll see that it managed to display “Ended” a few times in the console, then nothing happens anymore:
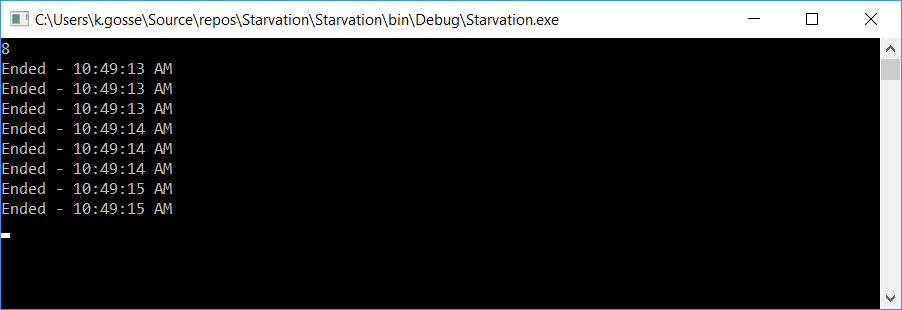
Note that this code assumes that Environment.ProcessorCount is lower or equal to 8 on your machine. If it’s bigger, then the threadpool will start with more thread available, and you need to lower the delay of the Thread.Sleep in Producer() to set the same conditions.
Looking at the task manager, we can see that CPU usage is 0 and the number of threads is growing at about one per second:

Here I’ve let it run for a while and got to a whopping 989 threads, yet still nothing is happening! Even though 10 threads should be enough to handle the workload. So what’s going on?
Every bit is important in that code. For instance, if we remove Task.Yield and manually start new tasks instead in Producer (the comments indicate the changes):
using System;
using System.Threading;
using System.Threading.Tasks;
namespace Starvation
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(Environment.ProcessorCount);
ThreadPool.SetMinThreads(8, 8);
Task.Factory.StartNew(
Producer,
TaskCreationOptions.None);
Console.ReadLine();
}
static void Producer()
{
while (true)
{
// Creating a new task instead of just calling Process
// Needed to avoid blocking the loop since we removed the Task.Yield
Task.Factory.StartNew(Process);
Thread.Sleep(200);
}
}
static async Task Process()
{
// Removed the Task.Yield
var tcs = new TaskCompletionSource<bool>();
Task.Run(() =>
{
Thread.Sleep(1000);
tcs.SetResult(true);
});
tcs.Task.Wait();
Console.WriteLine("Ended - " + DateTime.Now.ToLongTimeString());
}
}
}Then we get the predicted behavior! The application struggles a bit at first, until the threadpool grows enough. Then we have a steady stream of messages, and the number of threads is stable (29 in my case).
What if we take that working code but start Producer in its own thread?
using System;
using System.Threading;
using System.Threading.Tasks;
namespace Starvation
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(Environment.ProcessorCount);
ThreadPool.SetMinThreads(8, 8);
Task.Factory.StartNew(
Producer,
TaskCreationOptions.LongRunning); // Start in a dedicated thread
Console.ReadLine();
}
static void Producer()
{
while (true)
{
Process();
Thread.Sleep(200);
}
}
static async Task Process()
{
await Task.Yield();
var tcs = new TaskCompletionSource<bool>();
Task.Run(() =>
{
Thread.Sleep(1000);
tcs.SetResult(true);
});
tcs.Task.Wait();
Console.WriteLine("Ended - " + DateTime.Now.ToLongTimeString());
}
}
}This frees one thread from the threadpool, so we should expect it to work slightly better. Yet, we end up with the first case: the application displays a few messages before locking up, and the number of threads grows indefinitely.
Let’s put Producer back to a threadpool thread, but use the PreferFairness flag when starting the Process tasks:
using System;
using System.Threading;
using System.Threading.Tasks;
namespace Starvation
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine(Environment.ProcessorCount);
ThreadPool.SetMinThreads(8, 8);
Task.Factory.StartNew(
Producer,
TaskCreationOptions.None);
Console.ReadLine();
}
static void Producer()
{
while (true)
{
Task.Factory.StartNew(Process, TaskCreationOptions.PreferFairness); // Using PreferFairness
Thread.Sleep(200);
}
}
static async Task Process()
{
var tcs = new TaskCompletionSource<bool>();
Task.Run(() =>
{
Thread.Sleep(1000);
tcs.SetResult(true);
});
tcs.Task.Wait();
Console.WriteLine("Ended - " + DateTime.Now.ToLongTimeString());
}
}
}Then once again we end up with the first situation: the application locks up, and the number of threads increases indefinitely.
So, what is really going on?
The threadpool queuing algorithm
To understand what’s happening, we need to dig into the internals of the threadpool. More specifically, into the way the workitems are queued.
There are a few articles out there explaining how the threadpool queuing works (The Moth - New and Improved CLR 4 Thread Pool Engine). In a nutshell, the important part is that the threadpool has multiple queues. For N threads in the threadpool, there are N+1 queues: one local queue for each thread, and one global queue. The rules for picking in which queue your item will go are simple:
- The item will be enqueued to the global queue:
- if the thread that enqueues the item is not a threadpool thread
- if it uses ThreadPool.QueueUserWorkItem/ThreadPool.UnsafeQueueUserWorkItem
- if it uses Task.Factory.StartNew with the TaskCreationOptions.PreferFairness flag
- if it uses Task.Yield on the default task scheduler
- In pretty much all other cases, the item will be enqueued to the thread’s local queue
How are the items dequeued? Whenever a threadpool thread is free, it will start looking into its local queue, and dequeue items in LIFO order. If the local queue is empty, then the thread will look into the global queue and dequeue in FIFO order. If the global queue is also empty, then the thread will look into the local queues of other threads and dequeue in FIFO order (to reduce the contention with the owner of the queue, which dequeues in LIFO order).
How does that impact us? Let’s go back to our faulty code.
In all the variations of the code, the Thread.Sleep(1000) is enqueued in a local queue, because Process is always executed in a threadpool thread. But in some cases we enqueue Process in the global queue and in others in the local queues:
- In the first version of the code, we use Task.Yield, which queues to the global queue
- In the second version, we use Task.Factory.StartNew, which queues to the local queue
- In the third version, we change the Producer thread to not use the threadpool, so Task.Factory.StartNew enqueues to the global queue
- In the fourth version, Producer is a threadpool thread again but we use TaskCreationOptions.PreferFairness when enqueuing Process, thus using the global queue again
We can see that the only version that worked was the one not using the global queue. From there, it’s just a matter of connecting the dots:
- Initial condition: we put our system in a state where the threadpool is starved (i.e. all the threads are busy)
- We enqueue 5 items per second into the global queue
- Each of those items, when executing, enqueues another item into the local queue and waits for it
- When a new thread is spawned by the threadpool, that thread will first look into its own local queue which is empty (since it’s newborn). Then it’ll pick an item from the global queue
- Since we enqueue into the global queue faster than the threadpool grows (5 items per second versus 1 thread per second), it’s completely impossible for the system to recover. Because of the priority induced by the usage of the global queue, the more threads we add, the more pressure we put on the system
When using the local queue instead (second version of the code), the newborn threads will pick items from the other threads’ local queues since the global queue is empty. Therefore, new threads helps alleviate the pressure on the system.
How does it translate to a real-world scenario?
Take the case of an HTTP-based service. The HTTP stack, whether it uses Windows’ http.sys or another API, is most likely native. When it forwards new requests to the .NET user code, it’ll queue them in the threadpool. Those items will necessarily end up in the global queue, since the native HTTP stack can’t possibly use .NET threadpool threads. Then the user code relies on async/await, and very likely use the local queues all the way. It means that in a situation of starvation, new threads spawned by the threadpool will process the new requests (enqueued in the global queue by the native code) rather than completing the ones already in the pipe (enqueued in the local queues). Therefore, we end up in the situation previously described where every new thread adds even more pressure to the system.
Another situation where things can turn ugly is if the blocking code is running as part of the callback of a timer. Timer callbacks are enqueued into the global queue. I believe such a case can be found here (pay a close attention to the TimerQueueTimer.Fire call at the beginning of the callstack for the 1202 threads shown): Azure DevOps Service.
What can we do about that?
From a user-code perspective, unfortunately not much. Of course, in an ideal world we would use non-blocking code and never end up in a threadpool starvation situation. Using a dedicated pool of threads around the blocking calls can help a lot, as you stop competing with the global queue for new threads. Having a back-pressure system is a good idea too. At Criteo we’re experimenting with a back-pressure system that measures how long it takes for the threadpool to dequeue an item from a local queue. If it takes longer than a few configured threshold, then we stop processing incoming requests until the system recovers. So far it shows promising results.
From a BCL (基础类库) perspective, I believe we should treat the global queue as just another local queue. I can’t really see a reason why it should be treated in priority compared to all other local queues. If we’re afraid that the global queue would grow quicker than the other queues, we could put a weight on the random selection of the queue. It would probably require some adjustments, but this is worth exploring.从BCL的角度来看,我认为我们应该将全局队列视为另一个本地队列。我真的看不出为什么它应该优先于所有其他本地队列。如果我们担心全局队列会比其他队列增长得更快,我们可以对队列的随机选择施加权重。这可能需要一些调整,但这是值得探索的















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









