






要理解SVM的损失函数,先定义决策边界。假设现在数据中总计有个训练样本,每个训练样本i可以被表示为 ( x i , y i ) ( i = 1 , 2 , . . . , N ) (x_i,y_i)(i=1,2,...,N) (xi,yi)(i=1,2,...,N),其中xi是 ( x 1 i , x 2 i , . . . , x n i ) T (x_1i,x_2i,...,x_ni)^T (x1i,x2i,...,xni)T这样的一个特征向量,每个样本总共含有n个特征。二分类标签yi的取值是{-1, 1}。
如果n等于2,则有i=(x1i,x2i,yi)T,分别由特征向量和标签组成。此时可以在二维平面上,以x2为横坐标,x1 为纵坐标,y为颜色,可视化所有的N个样本:
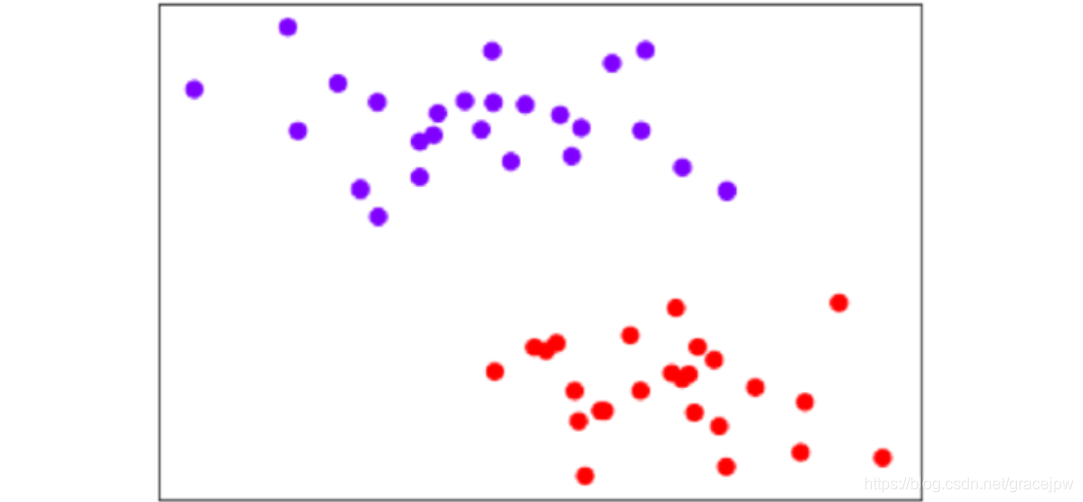
让所有紫色点的标签为1,红色点的标签为-1。要在这个数据集上寻找一个决策边界,在二维平面上,决策边界(超平面)就是一条直线。二维平面上的任意一条线可以被表示为:
x 1 = a x 2 + b x_1=ax_2+b x1=ax2+b
变换表达式如下:
0 = a x 2 − x 1 + b 0=ax_2-x_1+b 0=ax2−x1+b
0 = [ a , − 1 ] ∗ [ x 1 x 2 ] + b 0=[a,-1]*\left[\begin{array}{c}x_1\\x_2\end{array}\right]+b 0=[a,−1]∗[x1x2]+b
0 = ω T x + b 0=\boldsymbol{\omega^Tx}+b 0=ω
机器学习:线性SVM的损失函数
最新推荐文章于 2022-03-07 12:28:56 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5148
5148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









