







A pre-training based personalized dialogue generation model with persona-sparse data
基于预训练和个性化稀疏数据的个性化对话生成模型
论文背景
AAAI2020 解读
部分内容引用 https://blog.csdn.net/LZJ209/article/details/104303844
原文链接:https://arxiv.org/abs/1911.04700
1.为了让对话模型生成出更加human-like的回复,给模型以特定的性格背景等作为参考信息是必要的。
2.大型预训练模型比如GPT2和BERT由于使用了大量的语句做训练,它们的语言能力非常的强大,生成出的语句非常的流畅。虽然大型预训练模型并没有针对某一个领域进行训练,但是人们通过在预训练的基础上再在目标数据集上进行二次训练,得到的结果大多好过只用目标数据集训练的结果。
3.数据集PERSONA-CHAT是一个为了应对该任务而提出的一个数据集,数据集采用人工收集,在构造数据集时人们被要求按照给定的性格信息来进行模拟对话,由此造成参与者在短短的几句对话中包含了相当多的个人信息,论文称这种现象为"persona-dense"。 [复制]
论文想要解决的问题
1.真实的对话中,只有很少的对话会涉及到个人信息,我们称现实生活中的对话是“persona-sparse”的,上述persona-dense的数据集并不符合真实情况。
2.如果直接用大型预训练模型在PERSONA-CHAT类似的数据集上进行训练,那么模型很有可能过分的注重个人信息,从而造成句句都离不开个人信息,这在上述数据集上可能会得到很好的结果,但是却并不真实。
3.由于真实的对话中,涉及到个人信息的语句非常的少,所以直接在persona-sparse的数据集上训练很有可能模型更注重那些不包含个人信息的语句,个人信息在训练的过程中成了噪音。
(总结:用persona-dense数据集不行,用普通数据集也不行)
论文贡献
提出了一个可以在persona-sparse的数据集上训练的预训练模型。
提出了一种通过模型自动计算persona比重的方法。
模型
变量解释
目标:根据 dialogue context C和responder的target persona T,生成流畅的response Y
Y
=
arg
max
Y
′
P
(
Y
′
∣
C
,
T
)
Y = \mathop{\arg\max}_{Y'}P(Y'|C,T)
Y=argmaxY′P(Y′∣C,T)
其中,persona T 视为一些属性的集合(例如 性别、地点、个人兴趣)
T
=
{
t
1
,
t
2
,
.
.
.
,
t
N
}
T=\{t_1, t_2, ..., t_N \}
T={t1,t2,...,tN},且每个属性可以用键值对
t
i
=
<
k
i
,
v
i
>
t_i=<k_i,v_i>
ti=<ki,vi>表示。
dialogue context
C
=
{
(
U
1
,
T
1
)
,
.
.
.
,
(
U
M
,
T
M
)
}
C=\{ (U_1,T_1),...,(U_M,T_M)\}
C={(U1,T1),...,(UM,TM)}包含了对话中的多轮(turns)【也就是话语
U
i
U_i
Ui】和 persona
T
i
T_i
Ti。
框架
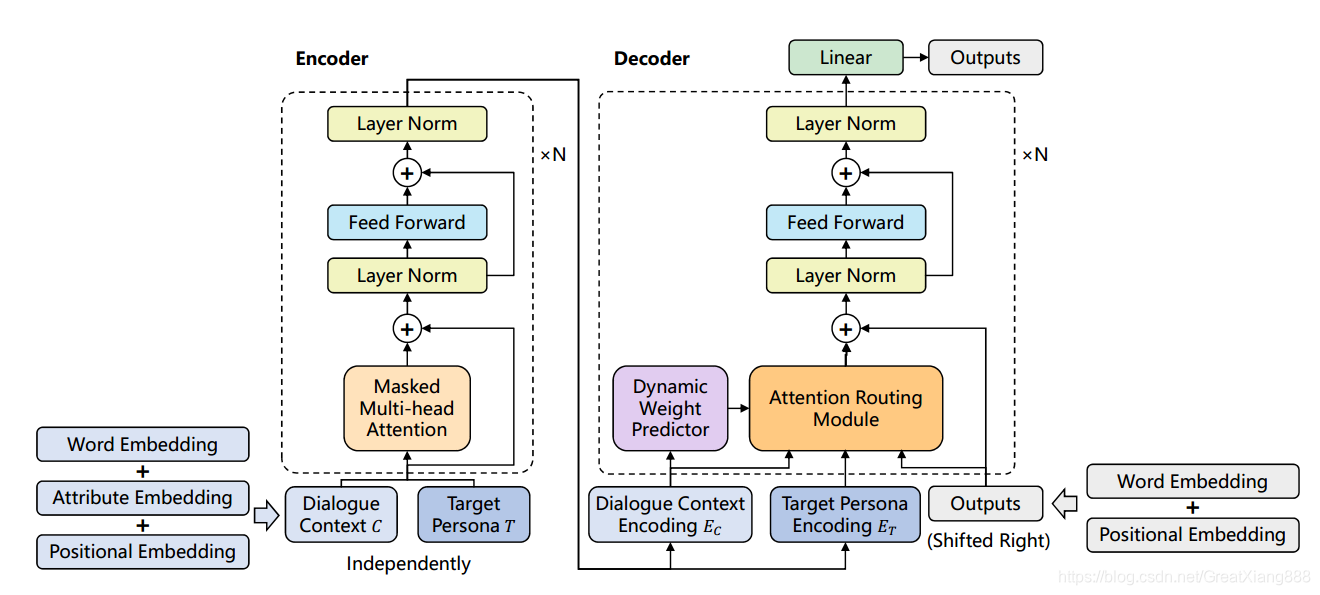
个性化对话生成模型框架:编码器和解码器共享同一组参数。dialogue context和target persona使用编码器独立编码,并且它们的编码进入每个解码器块中的注意路由模块。训练一个动态权重预测器来衡量每条路线的贡献。
Encoding
Encoding with Personas

Attention
Attention Routing:
target persona
E
T
E_T
ET , the dialogue context
E
C
E_C
EC , previously decoded tokens
E
p
r
e
v
E_{prev}
Eprev
E
p
r
e
v
E_{prev}
Eprev作为query。
E
T
E_T
ET ,
E
C
E_C
EC,
E
p
r
e
v
E_{prev}
Eprev采用3个multi-head attention 分别作为key与value。
O
T
=
M
u
l
t
i
H
e
a
d
(
E
p
r
e
v
,
E
T
,
E
T
)
O_T = MultiHead(E_{prev},E_T,E_T)
OT=MultiHead(Eprev,ET,ET)
O
C
=
M
u
l
t
i
H
e
a
d
(
E
p
r
e
v
,
E
C
,
E
C
)
O_C = MultiHead(E_{prev},E_C,E_C)
OC=MultiHead(Eprev,EC,EC)
O
p
r
e
v
=
M
u
l
t
i
H
e
a
d
(
E
p
r
e
v
,
E
p
r
e
v
,
E
p
r
e
v
)
O_{prev} = MultiHead(E_{prev},E_{prev},E_{prev})
Oprev=MultiHead(Eprev,Eprev,Eprev)
前两个公式采用unmasked 双向 self-attention 来获取更多有效的交互信息。最后一个公式采用masked self-attention来避免看到“golden truth” token.
然后进行融合,persona 权重
α
∈
[
0
,
1
]
\alpha \in [0,1]
α∈[0,1] :
O
m
e
r
g
e
=
α
O
T
+
(
1
−
α
)
O
C
+
O
C
+
O
p
r
e
v
O_{merge} = \alpha O_T +(1-\alpha)O_C +O_C+ O_{prev}
Omerge=αOT+(1−α)OC+OC+Oprev
α
\alpha
α越大,包含的个性化信息越多。
自动计算persona比重
α
\alpha
α怎么得到:
设计一个二分类器
P
θ
(
r
∣
E
C
)
P_{\theta}(r|E_C)
Pθ(r∣EC)。输入dialogue context
E
C
E_C
EC ,判断这个training dialogue是否为persona related ,相关则r=1,不相关r=0。
那么这个二分类器的confidence就可以当作权重:
α
=
P
θ
(
r
=
1
∣
E
C
)
\alpha = P_{\theta}(r=1|E_C)
α=Pθ(r=1∣EC)
我们可以通过一个heuristic script产生标签,该脚本通过一些规则(如单词匹配)来判断是否persona related。
二分类器的目标函数:
L
W
(
θ
)
=
−
∑
i
r
i
l
o
g
P
θ
(
r
i
∣
E
C
)
+
(
1
−
r
i
)
l
o
g
[
1
−
P
θ
(
r
i
∣
E
C
)
]
L_W(\theta) = -\sum_{i}r_i log P_{\theta}(r_i|E_C) + (1-r_i) log [1-P_{\theta}(r_i|E_C)]
LW(θ)=−i∑rilogPθ(ri∣EC)+(1−ri)log[1−Pθ(ri∣EC)]
language model
Pre-training and Fine-tuning
原始的LM,和gpt2相同
L
L
M
(
ϕ
)
=
−
∑
i
l
o
g
P
ϕ
(
u
i
∣
u
i
−
k
,
.
.
.
,
u
i
−
1
)
L_{LM}(\phi) = -\sum_{i} log P_{\phi} (u_i |u_{i-k}, ..., u_{i-1})
LLM(ϕ)=−i∑logPϕ(ui∣ui−k,...,ui−1)
考虑到dialogue context encoding
E
C
E_C
EC和target persona encoding
E
T
E_T
ET的:
L
D
(
ϕ
)
=
−
∑
i
l
o
g
P
ϕ
(
u
i
∣
u
i
−
k
,
.
.
.
,
u
i
−
1
,
E
C
,
E
T
)
L_{D}(\phi) = -\sum_{i} log P_{\phi} (u_i |u_{i-k}, ..., u_{i-1}, E_C, E_T)
LD(ϕ)=−i∑logPϕ(ui∣ui−k,...,ui−1,EC,ET)
最终的目标函数
L ( ϕ , θ ) = L D ( ϕ ) + λ 1 L L M ( ϕ ) + λ 2 L W ( θ ) L(\phi,\theta) = L_D(\phi) + \lambda_1 L_{LM}(\phi) + \lambda_2 L_W(\theta) L(ϕ,θ)=LD(ϕ)+λ1LLM(ϕ)+λ2LW(θ)
END
(公式还是挺难敲的。。)














 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









