







转载注明来源: https://blog.csdn.net/greenlight_74110/article/details/79715264
背景
在传统的RNN网络的反向传播过程中,在与关联循环隐藏层间的神经元的权重矩阵相乘很多次后,梯度会消失。这意味着,过渡矩阵中的权重大小对学习过程有很强的影响。
如果该矩阵中的权重小(更确切来说,如果权重矩阵的主要特征值比1小),可能会导致一种叫做梯度消失的情况,即梯度信号变得太小以致于学习变得十分缓慢或者停止。它将会使得学习数据中的长期依赖关系的任务变得更加困难。反过来,如果该矩阵中的权重很大(或者说,权重矩阵的主要特征值比1.0大),将导致梯度信号太大以致于学习产生偏差的情况,通常被称为梯度爆炸。
模型
以上的问题是LSTM模型提出一种叫做记忆单元的新结构背后的主要动机。一个记忆单元由四种主要元素组成:一个输入门,一个具有自循环连接的神经元,一个遗忘门以及一个输出门。自循环连接有着1.0的权重并确保能阻断任何外部干扰,一个记忆单元的状态可以在一个时间步到另一个之间保持连续。这些门被用来调制记忆单元本身间的相互干扰和环境。输入门可以允许即将到来的信号来改变记忆单元的状态或者阻断它。另一方面,输出门能允许记忆单元的状态对其它神经元产生影响或者阻断它。最后,遗忘门能调节记忆单元的自循环连接,允许单元根据需要记住或者忘记它先前的状态。

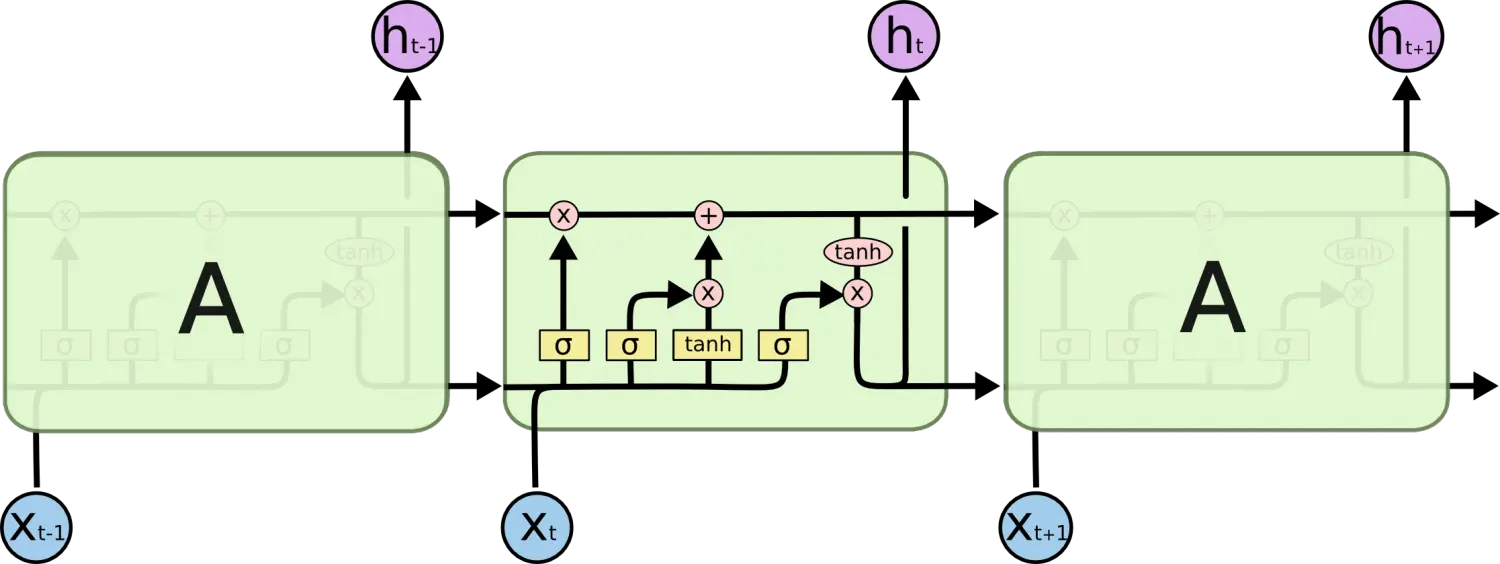
实现
下面的等式描述了某一层中的记忆单元在每个时间步t是怎样更新的。
x(t)是记忆单元层在时间t的输入
W、U、V是权重矩阵
b是偏置向量确定更新信息
首先,我们计算在时间t时,输入门的值i(t),用于记忆单元的状态的候选值C(t):


确定丢弃信息
然后,计算在时间t时,记忆单元的遗忘门的激活,f(t)的值:

更新单元状态
假设输入门激活的值i(t),遗忘门激活f(t)以及候选状态值C(t),可以计算出记忆单元在时间t的新状态C(t):

确定输出信息
利用记忆单元的新状态,我们可以计算出它们的输出门的值,再同单元状态相乘,继而算出单元输出:

















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









