







 本文详细介绍了机器学习项目实战的五个关键步骤:问题定义、数据预处理、选择模型、训练与参数确定、超参数调试与性能优化。在数据预处理阶段,强调了数据收集、预处理、特征工程的重要性,并提到了数据向量化、特征缩放等技巧。在模型训练过程中,讨论了内部参数和超参数的区别,以及模型评估和优化的方法,如K折验证和防止过拟合。
本文详细介绍了机器学习项目实战的五个关键步骤:问题定义、数据预处理、选择模型、训练与参数确定、超参数调试与性能优化。在数据预处理阶段,强调了数据收集、预处理、特征工程的重要性,并提到了数据向量化、特征缩放等技巧。在模型训练过程中,讨论了内部参数和超参数的区别,以及模型评估和优化的方法,如K折验证和防止过拟合。
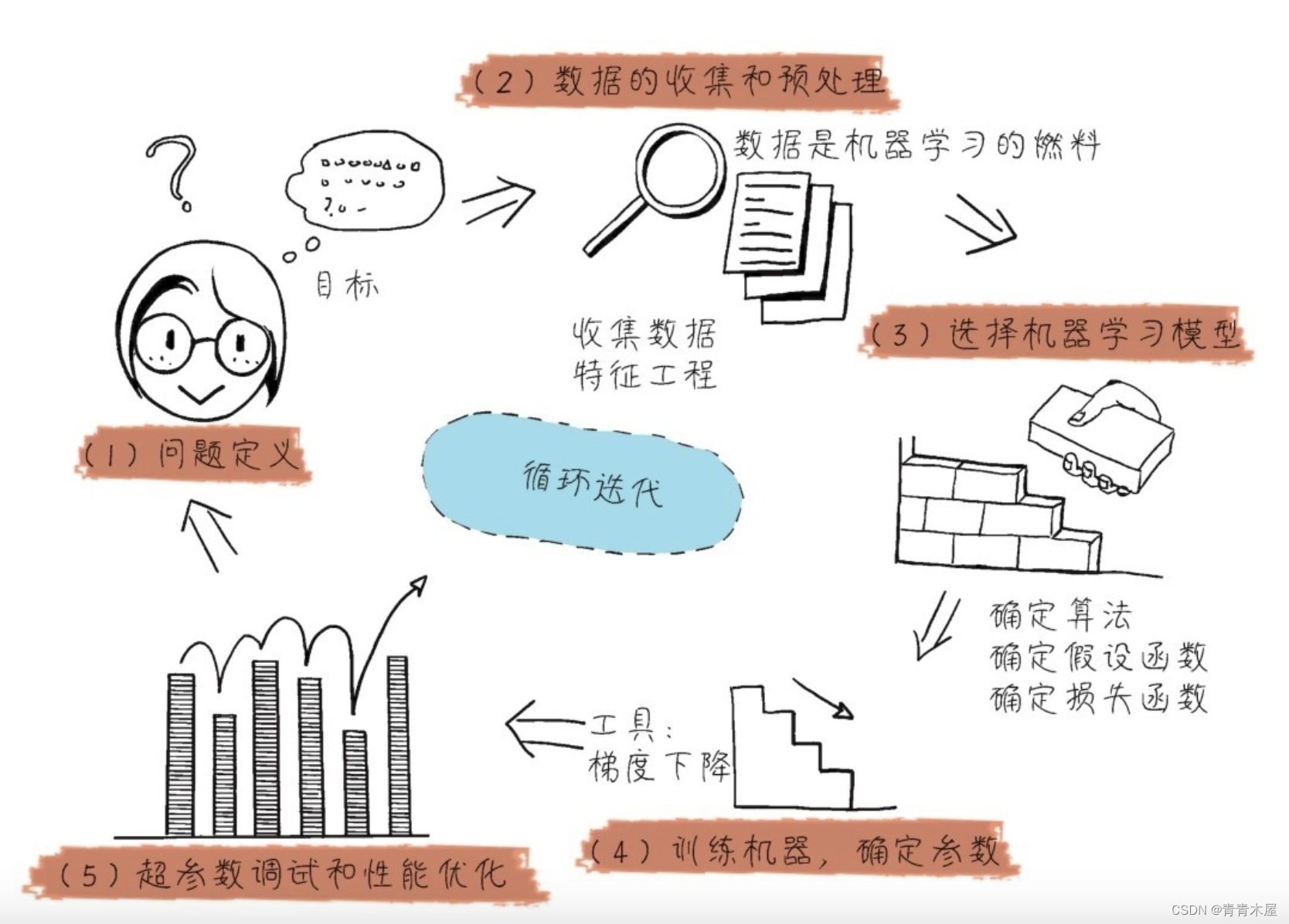
机器学习项目实战架构
机器学习建模过程可以总结为,建模”三部曲“:
- 选择函数模型,
- 评估函数的优劣,
- 确定最优的函数。
而机器学习项目的实际过程,可以大致分为以下5个环节:
- 问题定义
- 数据的收集和预处理
- 选择机器学习模型
- 训练机器,确定参数
- 超参数调试和性能优化
每一步处理是否得当,都直接影响机器学习项目的成败。
1、问题定义
第一个环节是对问题的构建和概念化。
首先构建业务问题,目前业务痛点是什么、需要解决什么问题、机器学习的目标是什么。
要想在过去的数据的基础上预测未来,其实存在一个假设,就是未来的规律与过去相同。
2、数据的收集和预处理
(1)原始数据的准备
原始数据可能从多种渠道获得,比如:
- 自有数据
- 网络公开数据
- 开源数据网站下载
数据的获取和使用,需要符合数据安全法。
(2)数据的预处理
预处理工作包括:
- 可视化
对数据做基本的了解,可以通过列表、直方图、散点图等来看数据,可以用Excel来看,也可以通过使用Matplotliib或Seaborn等数据分析工具来画图看。 - 数据向量化
把原始数据格式化,目的是让机器可以读取。 - 处理坏数据和缺失值
借助数据处理工具,处理冗余数据、离群数据、错误数据,以及补充缺失值。 - 特征缩放
- 标准化。是对数据特征分布的转换,目标是符合正态分布(均值为0,标准差为1)。如果数据特征不符合正态分布的话,会影响机器学习效率。在实战中,会去除特征的均值来转换数据,然后除以特征的标准差来进行缩放。
- 归一化。标准化的一种变体是将特征缩放到给定的最小值和最大值之间,通常是0~1。归一化不会改变数据的分布状态。
- 规范化。将样本缩放为具有单位范数的过程,然后放入机器学习模型,这个过程消除了数据中的离群值。
- 在sklearn的preprocessing
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









