




 本文详细介绍了嵌入式系统中的SFI、FPI和SPB总线技术。SFI是一个单向总线,用于接收SRI的信息,而FPI在结构上与SRI相似,但包含数据处理功能。SPB基于PFI,具有更复杂的仲裁规则和饥饿机制。文章探讨了总线的传输类型、错误处理以及配置选项,对于理解嵌入式系统的内部通信机制提供了深入见解。
本文详细介绍了嵌入式系统中的SFI、FPI和SPB总线技术。SFI是一个单向总线,用于接收SRI的信息,而FPI在结构上与SRI相似,但包含数据处理功能。SPB基于PFI,具有更复杂的仲裁规则和饥饿机制。文章探讨了总线的传输类型、错误处理以及配置选项,对于理解嵌入式系统的内部通信机制提供了深入见解。
全部学习汇总: GreyZhang/g_TC275: happy hacking for TC275! (github.com)
前面大概看完了SRI的介绍,这一次开始看SFI。其实,看SRI的时候遇到了一个名词不知道是什么概念,这个名词是FPI。其实,SFI与之基本是对等的概念。

1. 首先看这个标题,基本上在一定程度上解答了我之前不熟悉的FPI的概念。但是,依然没有看到这个是什么单词的缩写。
2. SFI是一个单向的总线,我重新看了之前的总线设计的拓扑图。这个SFI只能够接收来自于SRI的信息,但是不能够发送给SRI。SRI是一个64bit的总线,而SFI是32bit,因此传输的过程中有一个数据转换的过程。
3. SFI可以缓冲多个写操作的处理。这样,SPB通过SFI向SRI写入操作可以在SPB上完成,同时通过SFI在SRI上同步。如果写入出现了问题,SPB不会得到什么信息提示。其实,后面的结论很容易理解,前面的同步我有点糊涂。开始,我以为这种同步是因为总线宽度不同因此有了一个转换效率导致了一定的加速。但是现在看来,既然这个总线是一个单向的,或许这个根本就不会成功。而这部分的描述或许只是为了表达错误产生之后不会得到什么提示信息。

1. 从功能的划分来看,FPI很多结构的概念跟SRI是相似的。
2. 刚开始看到320M字节的速度还觉得怎么突然间这么快了,但是看看单位其实很容易理解。这个MCU的地址总线基本都是32bit起步的,这也是为什么MCU被叫做32bit的MCU的原因。而这个速度其实就是有效的数据传输发生在了每一个时钟周期内的结果。
3. FPI的各种主从结构等描述跟SRI也是很相似的,但是多了一个数据的处理。

1. 类似SRI,FPI的处理本身也是通过主从的配合。
2. SBCU,总线控制单元。如果类比SRI来看,应该主要的功能类似于仲裁器,或者大一些Xbar_SRI。

1. 传输类型有几种:单传、块传、原子传。其中,原子传输看起来其实就是两个单传传输。
2. FPI总线事件请求时,如果slave正在忙,这可以导致FPI总线延迟传输。这时候,master会释放总线让slave提示是否已经ready。这个过程可以不断循环,一直到slave ready。

1. 这里多少有一点疑问,A0是一个什么概念?是寄存器吗?难道这个寄存器的作用在实现的时候是固定的,专门用来寻址?
2. FPI的基本操作:请求/授权、寻址、数据处理。
3. 从上面的传输示例来看,能够看出一个基本原则。上面的三种操作是可以同时发生的,但是每一个操作至多只有一个。

1. 开始的一段信息非常有用,这里能够让我明白一个基本的概念。其实SPB在概念上是要多于FPI的,因为从描述看,SPB是基于PFI的。而SBCU的缩写从这里能够看出一个完整的拼写,系统总线控制单元。是用来进行FPI的控制的。
2. 总线的仲裁规则:如果有挂起的请求,那么授权给最高优先级;如果没有挂起的请求,授权给默认;如果没有请求,那么进入idle。
3. 基于由县级的仲裁,而优先级是4bit的,这个是SRI的两倍。而且,用到的DMA控制器其实还有3个优先级。
4.前面提到了一个默认,那么什么是默认呢?其实,用的最频繁的master用作默认。如果是reset之后,优先级为0的作为默认。
5. 不同于SRI,SPB的总线仲裁只有优先级仲裁加上了饥饿机制,没有轮询。
6.复位之后,每一个优先级寄存器都有一个默认值。每一个FPI的master都有一个独立的默认优先级。

1. 默认优先级基本上在应用的时候就是最优的,但是依然可以改。
2. 改的时候需要注意,不要出现两个相同的优先级。
3. 主优先级的修改只能够在只有一个master的时候进行配置修改,有多个master的时候不能够改。

1. SPB的饥饿机制跟SRI中的饥饿机制类似,都是通过一个计数器来实现。这个机制是永远使能的。
2. FPI的错误处理条件:错误确认;为实现的地址访问;超时。
3. 如果出现错误会记录地址和数据。

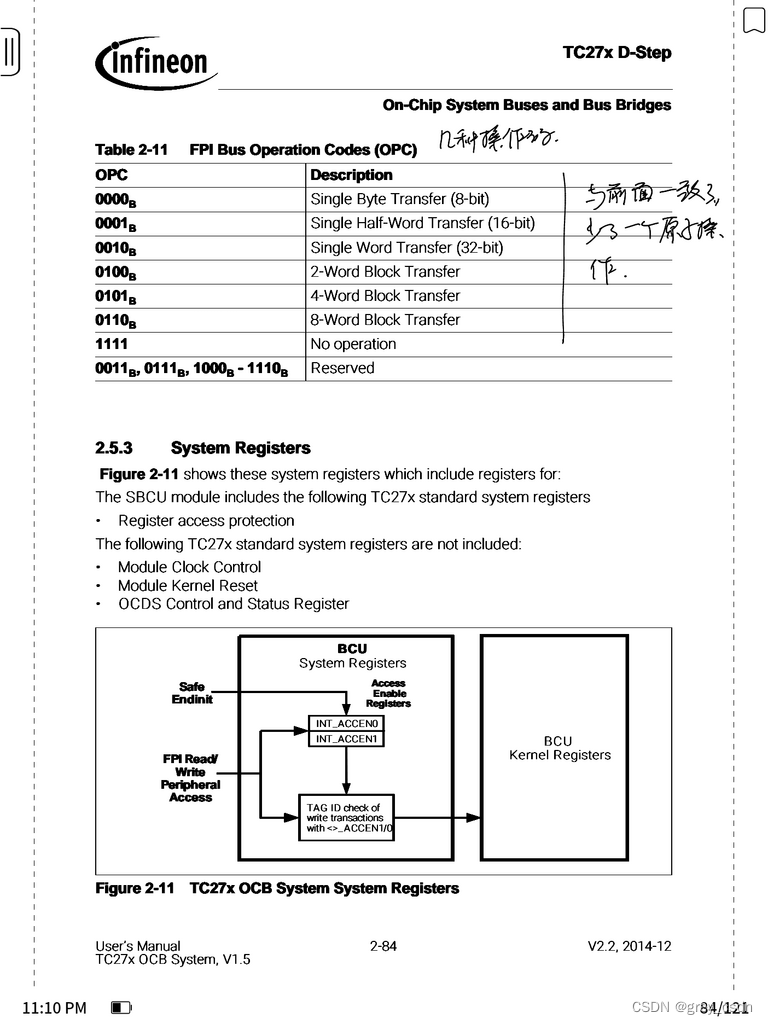
1. 在进行错误捕获的时候,机制类似于SRI,只进行第一个错误的捕获。
2. 如果捕获了一个错误之后,寄存器会锁定。只有接触锁定之后,才能够进行下一次捕获。
3. 写入事务中TriCore(应该是CPU的意思)引起的错误不会被提示,因为它不是有效的主代理。
4. 错误捕捉设置中也有一个SV的模式。
5. 这里给出了几种错误码以及操作码。
以上是对SPB的基本功能做了一个大概的了解,有了之前对SRI的了解这部分看得时候还是比较顺利的。这一次的学习暂且到此,后面再看一下是否有类似SRI的一些调试或者细致的配置。

















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









