







目录
CubeStudio 在线开发:Jupyter 创建 GPU 类型容器后无法识别显卡的解决方法
CubeStudio 在线开发:Jupyter 创建 GPU 类型容器后无法识别显卡的解决方法
在使用 CubeStudio 在线开发平台创建带有 GPU 能力的 Jupyter Notebook 容器时,很多用户可能会遇到一个令人困惑的问题:
在容器中成功安装了 PyTorch 的 GPU 版本,但运行
torch.cuda.is_available()返回False,并且执行nvidia-smi显示 “No devices were found”。
本文将复现该问题的典型场景,并提供清晰的解决步骤,帮助你顺利使用 GPU 加速训练任务。
💥 问题复现
在创建 GPU 类型的 Jupyter 容器时,CubeStudio 需要你手动输入 GPU 资源使用限制。平台的输入框提示如下:
gpu的资源使用限制(单位卡),示例: 1,2。
训练任务每个容器独占整卡。申请具体的卡型号,可以类似 1(V100)。
很多用户容易误解这段描述,例如将 1,2 理解为「申请两个 GPU」,但实际上 该平台并不接受中英文逗号分隔的 GPU ID 列表格式。
错误输入示例:
1,2
造成的后果是:
-
Jupyter 容器虽然正常启动;
-
但容器内部
nvidia-smi返回No devices were found; -
torch.cuda.is_available()永远为False; -
实际未成功分配 GPU。
✅ 正确输入方式
平台需要你指定 单卡 GPU 数量 或 卡类型(可选),示例如下:
2
或(若支持类型指定):
2(V100)
这代表你申请 2 张 GPU 卡,或明确申请 2 张 V100 卡。
🔧 解决步骤回顾
1. 确认 PyTorch 为 GPU 版本
使用命令安装 PyTorch CUDA 11.8 版本:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
并在 Python 中验证:
import torch
print("torch version:", torch.__version__)
print("CUDA built:", torch.backends.cuda.is_built())
print("CUDA available:", torch.cuda.is_available())
print("CUDA version:", torch.version.cuda)
如果 torch.cuda.is_available() 为 False,请继续查看下一步。
2. 运行 nvidia-smi 检查显卡是否挂载
nvidia-smi
如输出:
No devices were found
说明 容器未正确挂载 GPU。
3. 修正 CubeStudio 的 GPU 配置参数
在重新创建 Jupyter 容器时:
-
清空之前的输入
1,2; -
改为只输入数字,如
2; -
然后点击启动。
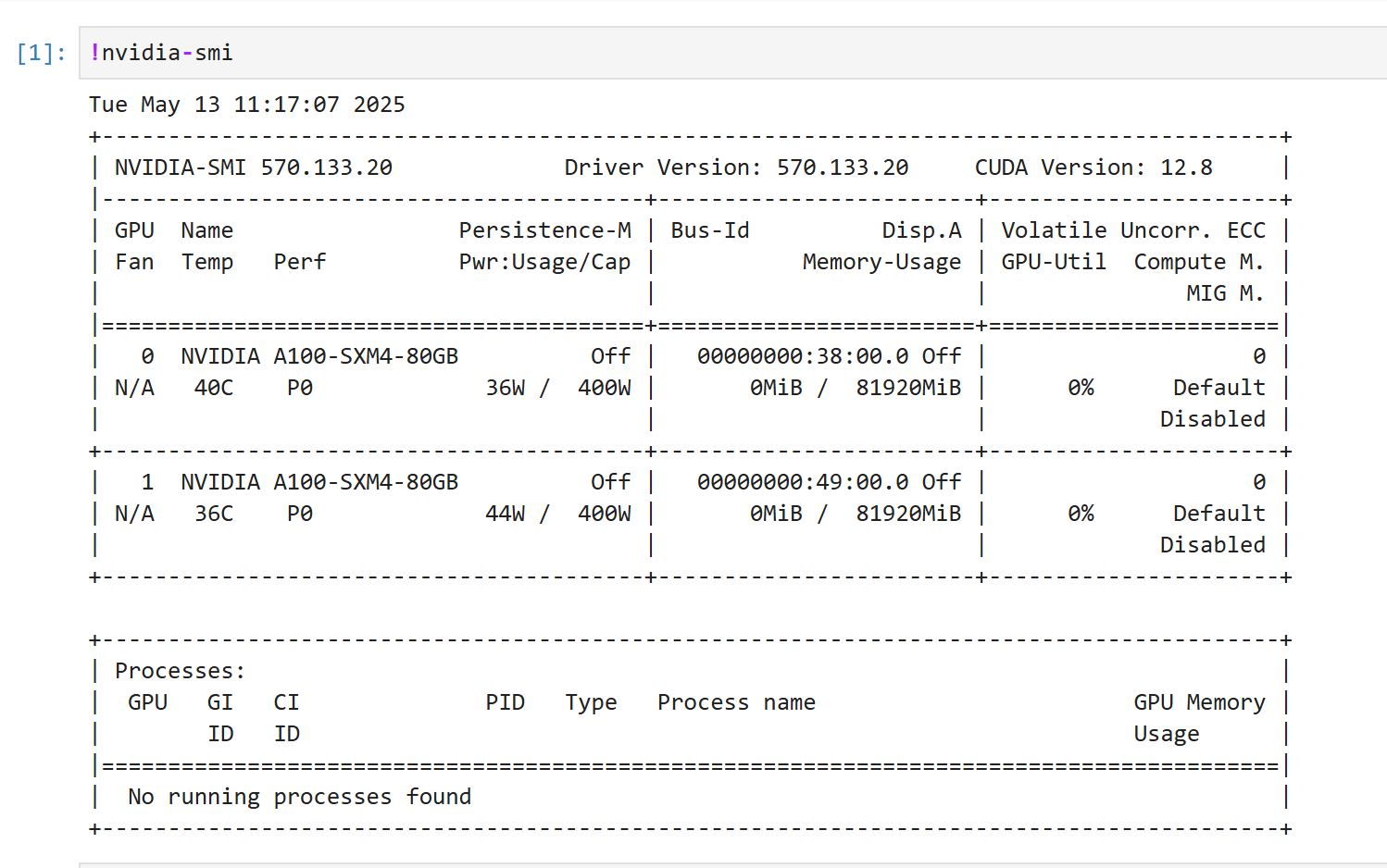
容器创建完成后,重新进入 Notebook,运行以下命令验证:
!nvidia-smi
如果显示正确的 GPU 型号、驱动版本和进程信息,说明问题已经解决。
此时:
torch.cuda.is_available() # 应返回 True
🎯 总结
| 问题项 | 描述 |
|---|---|
| 错误输入 | 1,2(逗号格式导致平台无法识别 GPU 申请) |
| 正确输入 | 2 或 2(V100) |
| 表现症状 | PyTorch 报告无 GPU,nvidia-smi 显示无设备 |
| 解决方式 | 重设容器,正确输入数字格式后重新申请 GPU |
🔚 结语
在云端平台进行 AI 开发时,显卡资源往往是关键。CubeStudio 提供了灵活的 GPU 分配机制,但对输入格式的要求较为严格。希望本文能够帮助你快速定位类似问题,顺利构建基于 GPU 的训练环境。
如需进一步了解 PyTorch GPU 使用、CUDA 驱动或 Docker 容器 GPU 挂载等内容,欢迎留言探讨!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









