






个人理解,水平有限,有错请多指正。参考论文:Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks
CTC是作为RNN的损失函数使用,只在训练的时候使用。
首先,假设有P个动态手势的视频序列
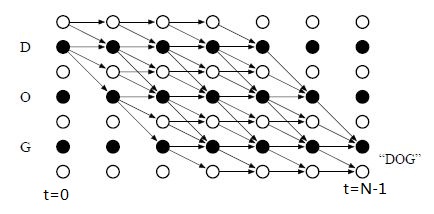
如上图所示(图片来自语音识别论文):D,O,G可以看成不同的手势,当识别多个视频流的动态手势时,多条路劲可以得到同一个向量y。如:[1-22-]=[-12--]=[12],其中1,2为具体手势的label,而-为空手势。从图可得最终路径的结束必须是在N-1的具体手势或者空手势结束。所以我们求得由X视频序列计算y向量的概率为:

其中:





而CTC的损失函数为:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









