







1. 目前进展
1.1 相关资料
1.2 流程
1.3 困难
1.4 组件
1.5 生成方法与判别方法
1.5.1 生成方法(Generative Methods)
1.5.2 判别方法(Discriminative Approaches)
1.6 手势姿态估计方法
1.6.1 方法分类
| Model-Driven | Data-Driven |
| User interacts primarily with a (mathematical) model and its results | User interacts primarily with the data |
| Helps to solve well-defined and structured problem (what-if-analysis) | Helps to solve mainly unstructured problems |
| Contains in general various and complex models | Contains in general simple models |
| Large amounts of data are not necessary | Large amounts of data are crucial |
| Helps to understand the impact of decisions | Helps to prepare decisions by showing developments in the past and by identifying relations or patterns |
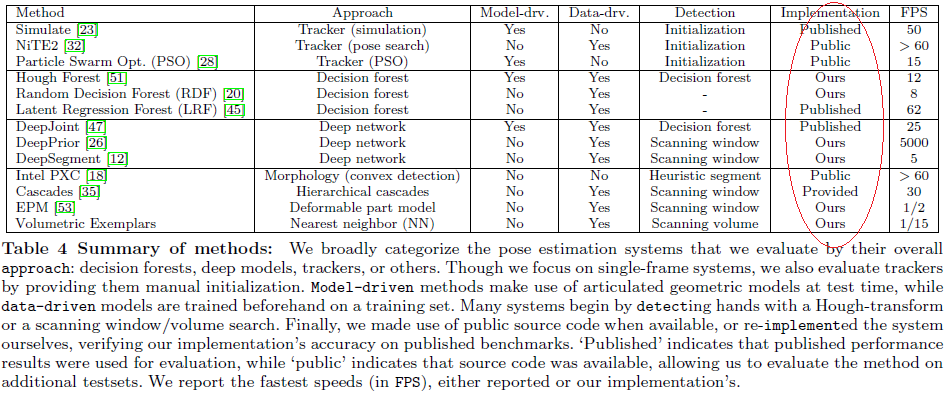
1.6.2 方法汇总
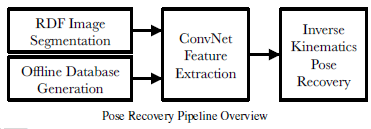
1.6.3 架构
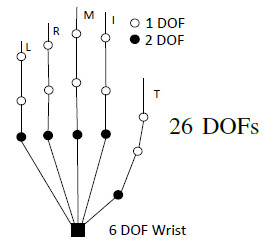
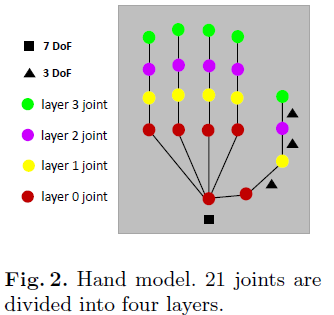
1.7 关节描述及自由度(DOF)
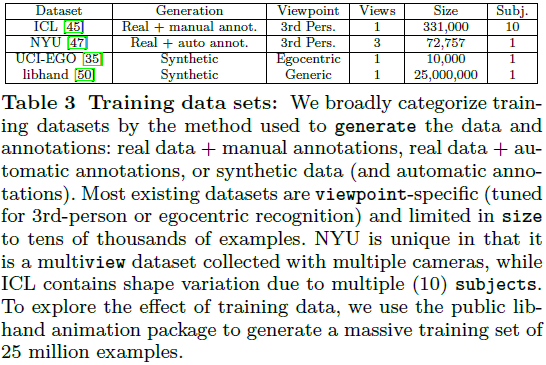
1.8 训练数据及其生成方法
1.8 测试数据(都是真实数据)

2. 生成模型 (Model Based Methods)
主要问题:初始化复杂、容易陷于局部最优
【1.1】(2014) Realtime and Robust Hand Tracking from Depth.
Chen Qian; Xiao Sun, Yichen Wei, Xiaoou Tang, Jian Sun
- 只使用CPU可达到25FPS,误差小于10mm
- 使用48个球简单定义手模型,并且定义了一个快速的cost函数;
- 定义了一个自由度(DOF)为26 的手的模型,其中的6个自由度代表全局的手的模型(整体);每一个手指还有4个自由度(总共20个)。同时还加上了手的运动学的限制。
- 使用基于梯度的随机优化方法,使其快速收敛并获取好的精确度;
1)基于梯度的优化方法。但是明显的缺点是:很容易被陷在局部最优里面,同时对于非刚体的处理效果也不是很好。
2)PSO: 是一种从参数空间搜索最优化参数的方法。在演化的过程中,整个点云的最好位置以及以及每一个点的局部最好的位置都被记录下来。在每一个的演化的过程中,粒子的速度都以它前一个速度的某种运算来更新。这样得到的结果的好处是:能够更好的搜索参数空间,避免那些很差的局部最优值。但是缺点是:速度比较慢。
- 建议了一个新的手指检测和手初始化方法
- Video
- MSRA Hand Dataset :Benchmark
3. 判别模型 (Data-Driven,Learning Based Methods)
- Deep-Joint
- 使用CNN提取特征,并为关节位置生成小的热图(heatmaps),然后从特征和小的热图中使用IK(反向动力学)推断出手的姿势。
- 此方法只能预测关节的2D位置,然后使用深度图算出第三个坐标,这对于隐藏关节是有问题的。此外,其精确度受限于heatmap分辨率;因为CNN必须在每个像素位置进行评估,所以创建热图计算量很大。
- 40FPS (without CPU,见"2015-Cascaded Hand Pose Regression")
- Code
- NYU Hand Pose Dataset : Benchmark
1) 使用Primesense Carmine 1.09(结构光)抓取 RGB-D数据(每一帧的关节位置通过3个Kinect获取)
2) 72K训练样本(1人),8K测试帧(2人 )
3) Ground Truth 标记包含36个关节,本文只使用了14个关节
【2】(2014.4) Latent Regression Forest: Structured Estimation of 3D Articulated Hand Posture.
Danhang Tang, Hyung Jin Chang, Alykhan Tejani, Tae-Kyun Kim
- 粗略估计一个包含手的3D边框
- 主要贡献:
1)学习手的拓扑结构(以非监督、数据驱动的方式),它由Latent Tree Model表示
2)一个新的基于森林的判别框架(LRF: Latent Regression Forest),此框架在图像中进行结构化搜索(coarse-to-fine),同时框架每个阶段嵌入一个错误回归器以避免错误累积
3)生成一个多视角的手势Dataset(180K 3D标记深度图,从10不同的测试者采集)
- ICVL Hand Posture Dataset:Benchmark
1) 使用Intel Creative TOF深度摄像头, 22K训练样本
2) 每行对应一个图像(包含16x3个数字,表示16个关节的位置(x,y,z),且是关节中央的位置)
3) (x,y)以像素为单位,z以mm为单位
4) 16个关节的顺序:Palm, Thumb root, Thumb mid, Thumb tip, Index root, Index mid, Index tip, Middle root, Middle mid, Middle tip, Ring root, Ring mid, Ring tip, Pinky root, Pinky mid, Pinky tip
5) 不精确的标记
- Video Awesome Random Forest Danhang Tang
- 62.5FPS (without CPU,见"2015-Cascaded Hand Pose Regression")
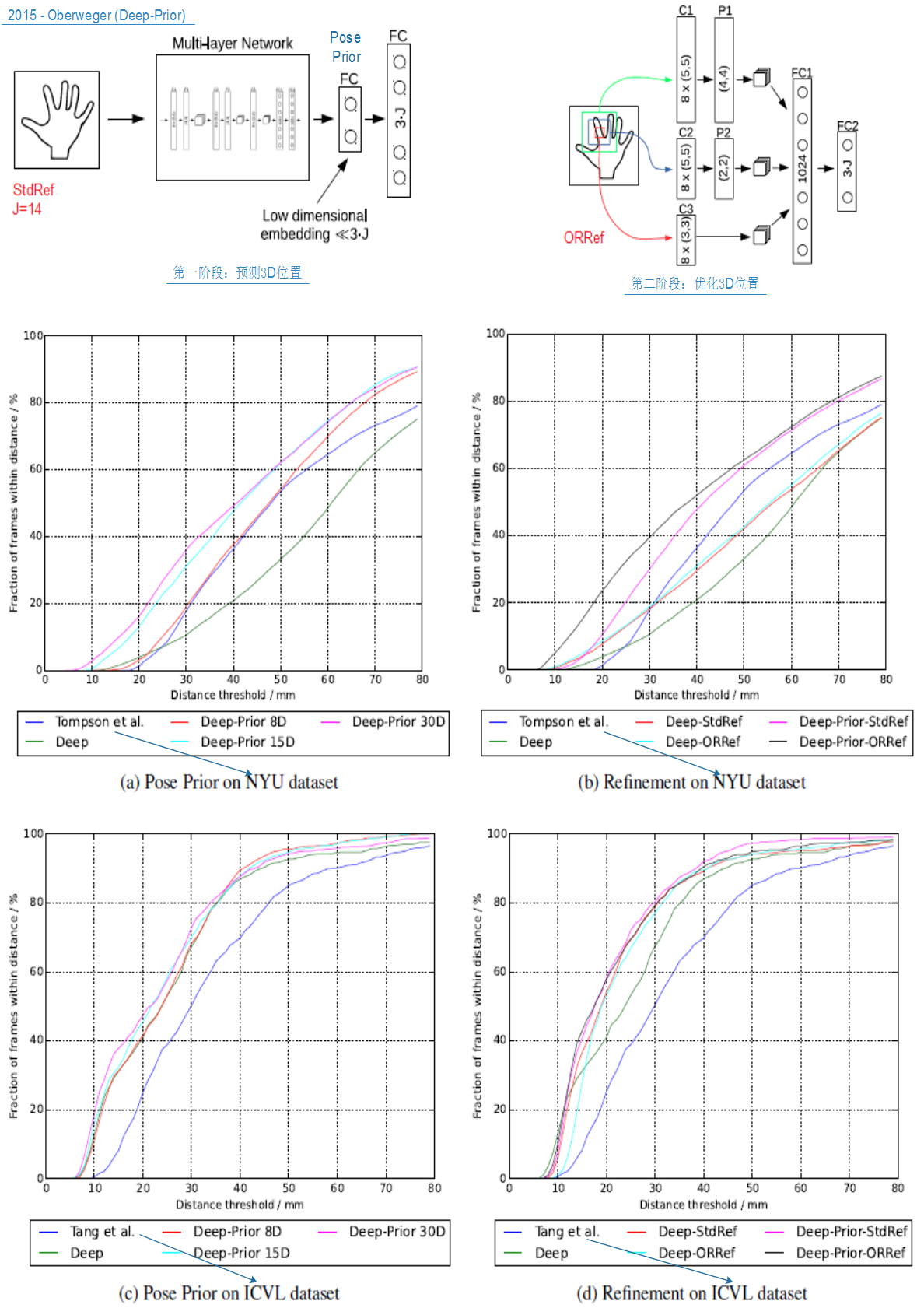
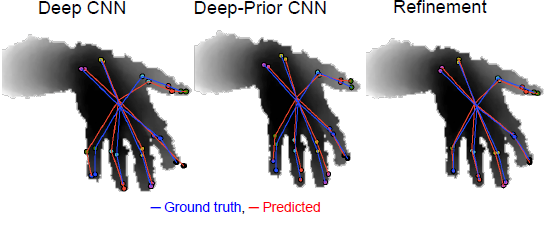
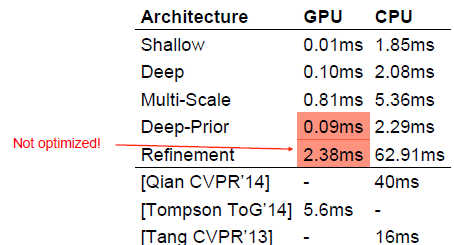
【3】(2015.2) Hands Deep in Deep Learning for Hand Pose Estimation.
Markus Oberweger, Paul Wohlhart, Vincent Lepetit
- Deep-Prior
- 使用CNN网络直接深度图中手关节的位置。本文的特点是速度很快并且精度可以通过refinement提高。作者主要的贡献是两个部分:
1)设计一个加入了prior的网络输出手的关节点
2)基于上述关节点预测,对每一个关节点用一个refinement网络来进行更精确的关节点输出。甚至可以用迭代的方式多次refine关节点位置
- Code Python Code based on Caffe
- 引用【1】、【2】
【4】(2015.x)Training a Feedback Loop for Hand Pose Estimation
Markus Oberweger, Paul Wohlhart, Vincent Lepetit
- 使用Feedback Loop来纠正预测错误
- Feedback Loop也是一个深度网络,通过训练数据优化
- 避免把3D模型拟合到输入数据,不需要手工创建3D模型
- 在单GPU上可执行400fps
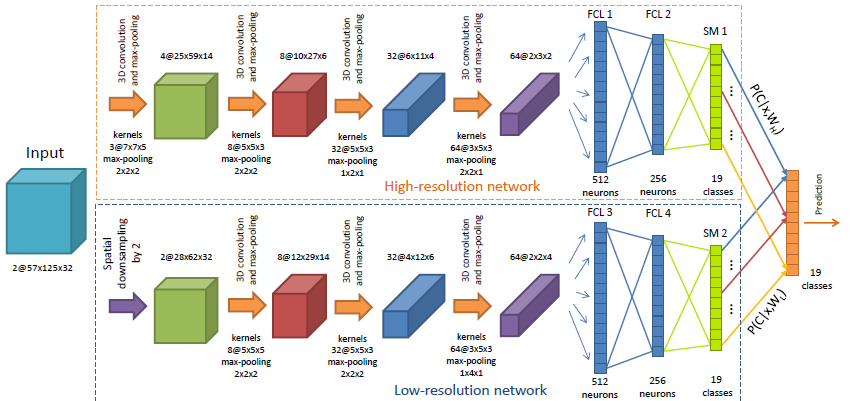
【5】(2015.4) Hand Gesture Recognition with 3D Convolutional Neural Networks
Pavlo Molchanov, Shalini Gupta, Kihwan Kim, and Jan Kautz
- 从深度图像中识别驾驶员手势 (NVIDIA)
- 组合多空间尺度的信息进行最后的预测
- 也利用空间-时间方法进行数据扩增,以避免训练时的过拟合
- 正确率 77.5%,基于VIVA challenge dataset
【6】(2015.5) Depth-based hand pose estimation: methods, data, and challenges.
James Steven Supancic III Gregory Rogez Yi Yang Jamie Shotton Deva Ramanan
- 基于单一深度帧实现了一系列的手势识别,并且发布了相关软件和评估代码
- 在单手场景中,姿势估计基本能解决
- 许多方法使用不同的标准评价自己,使比较变得困难,从而定义了一个评价标准
- 介绍了一个“简单的近邻基线”,它超越了大部已经存在的系统,表明大部分系统泛化能力差
- 强调一个未被关注的关键点:训练数据与模型本身一样重要
- 引用【1】、【3】

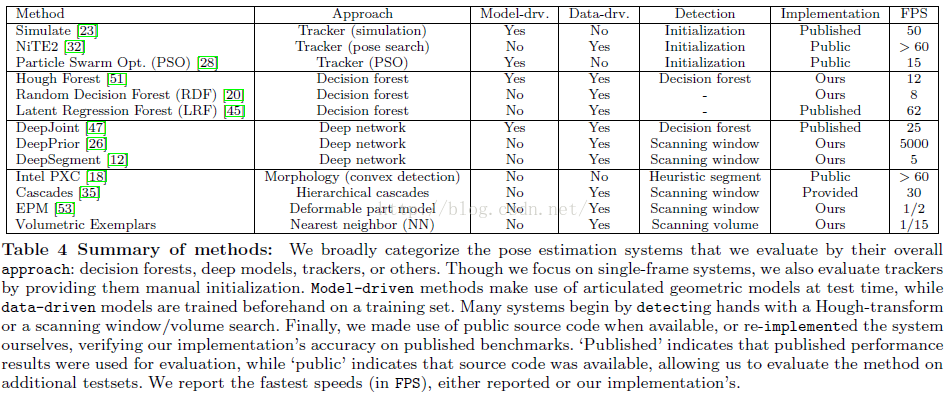
【7】(2015.4) Fast and Robust Hand Tracking Using Detection-Guided Optimization
Srinath Sridhar, Franziska Mueller, Antti Oulasvirta, Christian Theobalt
- RDF (Randomized Decision Forest、Gaussian mixture representation)
- 50FPS without GPU support
- Website
- 没有与其它方法的比较结果,其准确度不比Deep-Prior好
【8】(2015.4) Cascaded Hand Pose Regression
Xiao Sun, Yichen Wei, Shuang Liang, Xiaoou Tang and Jian Sun
- 三维姿态索引功能(3D pose-indexed features)
- 分层回归(Hierarchical Regression)
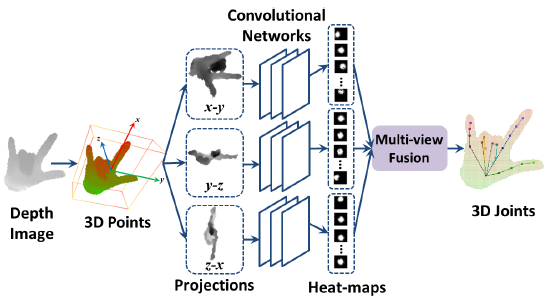
【8】(2016.3) Robust 3D Hand Pose Estimation in Single Depth Images: from Single-View CNN to Multi-View CNNs.
Liuhao Ge, Hui Liang, Junsong Yuan, and Daniel Thalmann
- 首先把深度图投影到3个正交平面,在每个平面上回归可以估计关节位置的热图(heat-maps)
- 把三个平面的热图融合起来,产生最后的3D位置估计,并学习先验姿势(pose priors)
- Video
- 引用【1】、【2】
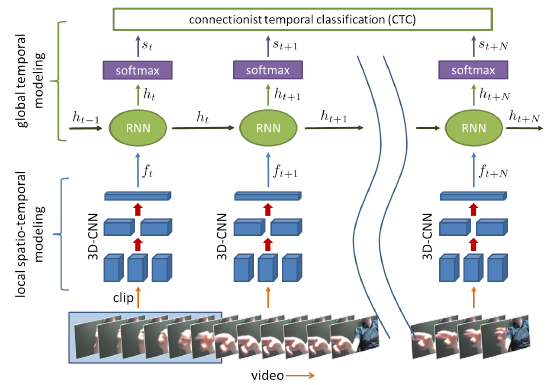
【9】(2016.4) Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D CNN.
Pavlo Molchanov, Xiaodong Yang, Shalini Gupta, Kihwan Kim, Stephen Tyree, Jan Kautz
- 在真实世界中自动检测并分类动态手势的挑战:
1)人做手势时存在大量的多样性,导致检测和分类困难
2)系统必须实时在线工作,以避免用户做手势与分类结果出来之间有明显的延迟(实际需要在用户做完手势之前完成分类)
- 从多种数据中,使用递归三维卷积神经网络同时执行动态手势的检测和分类
- CNN可接入多路输入数据
- 检测分类器(Detection Classifier):区分是否有手势
- 识别分类器(Recognition Classifier):误别出具体的手势类型
-
- Video
- 在普通计算机上可达到32FPS,无需GPU加速
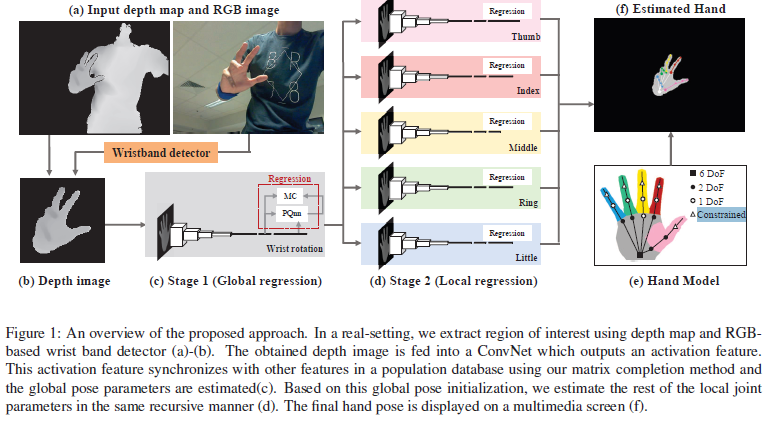
- 提供了一个完整矩阵(Matrix Completion)方法,此方法在每一帧的基础上估计关节角度参数
- 深度图-->CNN-->低维特征向量 (在训练时,按此方法生成特征数据库;在识别时,使用NN算法从特征数据库中找到最近的特征向量,从而获取关节角度参数<为了加速,会记住前面帧最近邻居的特征向量>)
- 创新的矩阵算法(matrix completion algorithm)使用空间、时间最近的特征向量及其已知的姿势参数来估计输入特征向量的姿势参数
- 包括大视角的特征数据库和分层的姿势参数估计,可以解决部分遮挡的问题
- 此方法可以灵活地使用或不使用时间信息,这样大大减轻了明显的姿势初始化(当跟踪丢失或手消失时)
- 如果把深度神经网络中分类层直接换成回归层,其目标函数将陷入局部最优
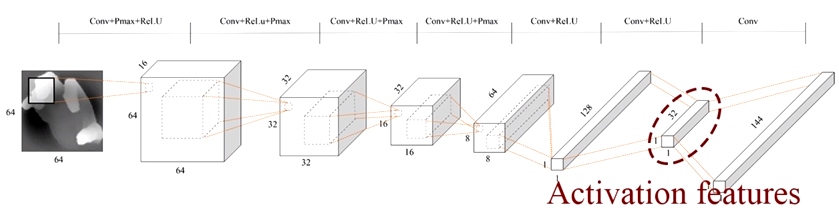
- 在全连接层的倒数第二层,训练几个ConvNets输出一个判别式的低维激活特征
- 主要观点:由一系列附近的激活特征生成一个激活特征,可以更好地表示手势
- ConvNets自动学习训练范围(全局或局部)、手指类型(thumb, index, middle, ring, little)、遮挡(通过输入姿势参数的离散值),且不需要其它额外信息
- 把训练数据输入ConvNets,ConvNets输出激活特征,然后把与每一个训练图像对应的激活特征存入“激活特征数据库”中
- 主要贡献:
1)姿势矩阵初始化(使用全局方向或手指关节的低维、差别式表示)
2)使用一个有效的矩阵方法估计关节角度参数
3)采用分层(全局回归、局部回归)的方法进行手势估计
- 此方法类似回归思想,但其完整矩阵方法中的“深度激活特征”与“强加的时间一致性”一起可以抑制抖动
- 此方法与协同过滤模型(collaborative filtering model)共享关系
- 卷积网络(ConvNet):不适合做回归任务,但分类任务做得很好
- 使用ConvNet计算的“激活特征”用于分类,而不是回归;把“激活特征”输入给用于实现回归的矩阵方法
- 如果每个关节角度参数一个ConvNet,其精度较好,但时间和内存消耗较大;如果使用一个ConvNet来训练所有的关节角度参数,其内存和时间消耗较小,但精度较差;所以本文采用两阶段分层的方案
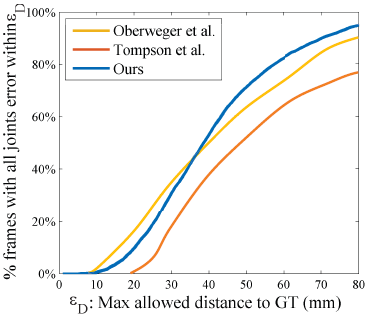
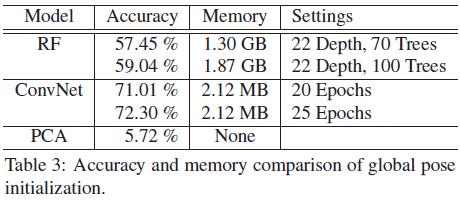
- 与其它方法的准确性比较,从图中可以可以,它的准确性并不比【3】Deep-Prior好 (GT:Ground Truth)
- 各种方法内存消耗比较

【11】(2016.5) Efficiently Creating 3D Training Data for Fine Hand Pose Estimation.
- 提供了一个半自动标定深度视频帧中手关节3D位置的方法,此方法只需要用户提供参考帧中可见关节的二维投影即可。
- 利用空间、时间和形状限制获取完整序列中手的所有关节位置
【12】(2014.9)Hand segmentation with structured convolutional learning
Natalia Neverova, Christian Wolf, Graham W. Taylor, Florian Nebout
- 数据对于现代算法来说有时候要高于算法本身,尤其是大面积推广深度学习以后,因此数据的多样性对模型最终精度和稳定性提供了一定的保障。但是庞大的数据标定却是一个非常痛苦的事情。尤其是网络越大,需要的数据就越多,动辄几十上百万,对于classification分分类估计还可以标一标,但是对于segmentation来说,要像素级别的标定上百万张图片,那就是不可能的
- 但是对于手势识别这样的变化非常大的任务来说,要想handle尽可能多的情况,样本会需要的更多。因此如何解决数据标定是一个难题
- 目前的解决方法是:使用合成数据,从微软的Human Pose那篇文章展现了合成数据的强大优势以来,合成数据的确是一个不错的选择,使用3D模型,天然精确标定,然后仿照现实中的情况添加一些噪声,然后就可以得到大量的标定数据
- 通过合成数据训练的模型提取context信息从而完成自动标定unlabelled样本
【13】(2016.6) Hand Pose Estimation through Semi-Supervised and Weakly-Supervised Learning
Natalia Neverova, Christian Wolf, Florian Neboutc, Graham W. Taylord。
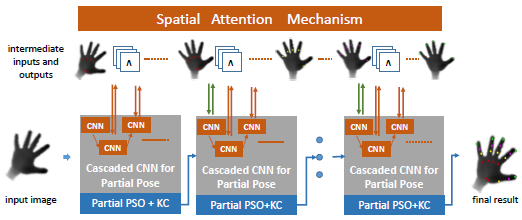
4. 混合方法(Discriminative methods + Generative methods)
Qi Ye, Shanxin Yuan, Tae-Kyun Kim















 1356
1356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









