







上一篇文章主要讲述了有关seaborn的一些基础设置,可以让使我们绘制的图形更加饱满。接下来我们来看seaborn可以绘制哪些图形。左边是我们常用的绘图接口,右边则是一些基础设置,还有一些功能有待补充。依次来看这些函数的实现方式和具体功能。 。
。
目录
一、关系图
1.scatterplot():散点图是统计可视化的重要组成部分。它使用点云来描述两个变量的联合分布,其中每个点代表数据集中的一个观察。这种描绘可以推断出大量关于它们之间是否有任何有意义的关系的信息。
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None,
data=None, palette=None, hue_order=None, hue_norm=None, sizes=None,
size_order=None, size_norm=None, markers=True, style_order=None,
x_bins=None, y_bins=None, units=None, estimator=None, ci=95, n_boot=1000,
alpha='auto', x_jitter=None, y_jitter=None, legend='brief', ax=None, **kwargs)
主要参数解析:
x,y:你需要传入的数据,一般为DataFrame中的列
hue:可以是dataframe中可以作为分类的某一列,主要作用就是分类
style:绘图的风格,可以是dataframe中可以作为分类的某一列
size:绘图的大小,可以是dataframe中可以作为分类的某一列
data:数据集,一般为DataFrame对象
palette:调色板
markers:bool,绘图的形状
ci:允许的误差范围
alpha:透明度
x_jitter,y_jitter:设置点的抖动程度
ax:绘制图像的坐标对象,否则使用当前坐标轴
示例:
仅使用x、y、data三个参数绘制图形
tip = pd.read_csv('tips.csv')
sns.scatterplot(x='total_bill', y='tip', data=tip)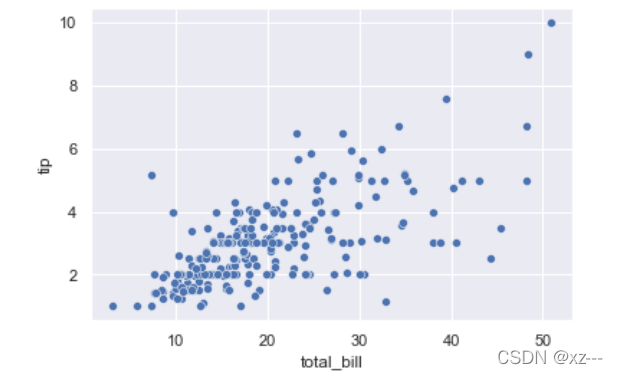
加入参数hue=‘time’后,数据依据time进行分组,使用其他特征的则会出现不一样的分组情况。
tip = pd.read_csv('tips.csv')
sns.scatterplot(x='total_bill', y='tip', hue='time', data=tip)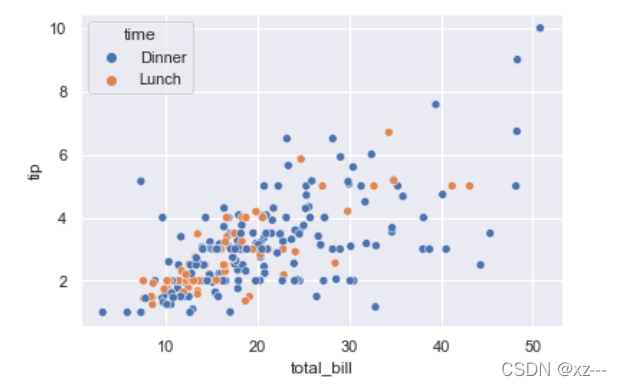
tip = pd.read_csv('tips.csv')
sns.scatterplot(x='total_bill', y='tip', hue='time', data=tip, style='time',
size='size', markers=True) 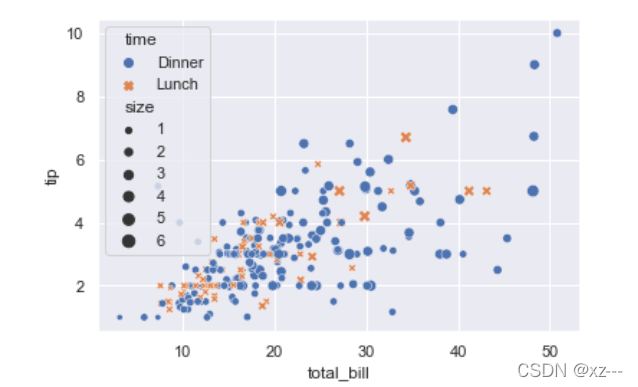
大家可以自行对比,看看有什么改变。
cmap = sns.cubehelix_palette(dark=.3,light=.8,as_cmap=True)
ax = sns.scatterplot(x='total_bill',y='tip',
hue='size', size='size',palette=cmap,data=tips)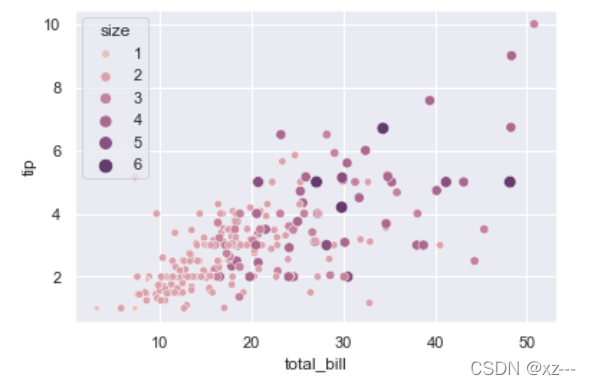
palette这个参数为我们接入了更加丰富的绘图颜色表示,但是色啊born本省自带的颜色其实也足够满足我们日常使用,如果还想掌握更加丰富的颜色表示,需要深入了解palette这个参数的用法。scatterplot()其他参数大家可以自行练习,这里就不在赘述。
2.lineplot():用几种语义分组的可能性画一条线图。可以使用色相,大小和样式参数针对数据的不同子集显示x和y之间的关系。这些参数控制使用什么视觉语义来标识不同的子集。通过使用所有三种语义类型,可以独立显示多达三个维度,但是这种情节样式可能难以解释,并且通常无效。使用冗余语义(即同一变量的色相和样式)有助于使图形更易于访问。
seaborn.lineplot(x=None, y=None, hue=None, size=None, style=None, data=None,
palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None,
size_norm=None, dashes=True, markers=None, style_order=None, units=None,
estimator='mean', ci=95, n_boot=1000, sort=True, err_style='band',
err_kws=None, legend='brief', ax=None, **kwargs)
主要参数解析:
x、y:输入数据变量
hue:分组变量
markers:bool,对不同的对象使用不同的标记
dashes:确定如何为style变量的不同级别绘制线条的对象。设置为True将使用默认的短划线代码,或者您可以将短划线代码列表或style变量的字典映射级别传递给短划线代码。设置为False将对所有子集使用实线。线段在 matplotlib 中指定: (segment, gap)长度的元组,或用于绘制实线的空字符串。
err_style:是否用半透明误差带或离散误差棒绘制置信区间。
(大部分参数同上)
仅使用x,y,data三个参数绘图
sns.lineplot(x='timepoint', y='signal', data=fmri)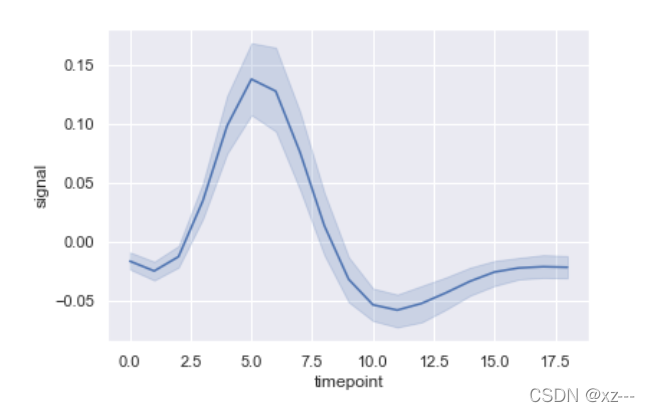
加入分组变量hue=’event‘
sns.lineplot(x='timepoint', y='signal', data=fmri, hue='event')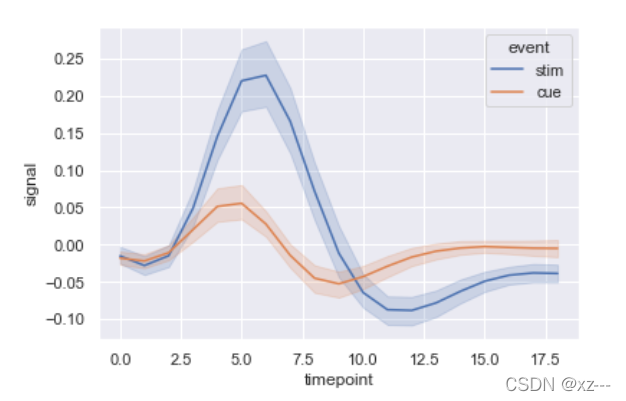
我们发现lineplot按照特征event中stim和cue两个分类变量将图像分成了两类。
sns.lineplot(x='timepoint', y='signal', data=fmri, hue='region', style='event',
markers=True,dashes=True, err_style='bars', ci=68)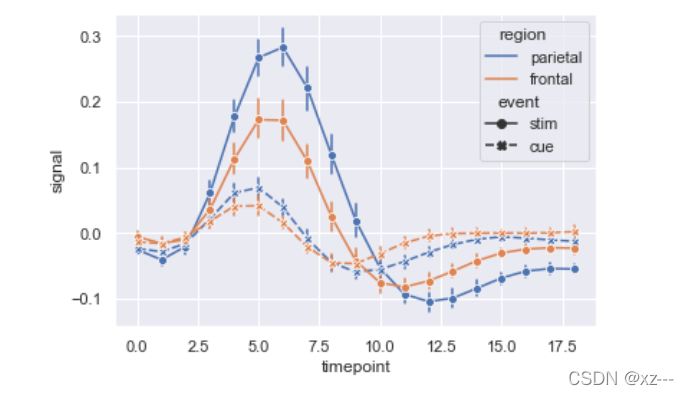
加入了markers后,每一条线都有了自己独特的标记,同时显示错误条而不是错误带并绘制标准错误。
3.relplot():relplot可以说是scatterplot与lineplot的加强版,不仅具备了后两者的特性,而且有了更全面的数据展示功能。
seaborn.relplot(x=None,y=None,hue=None,size=None,style=None,data=None,row=None,
col=None,col_wrap=None,row_order=None,col_order=None,palette=None,hue_order=None,
hue_norm=None,sizes=None,size_order=None,size_norm=None,markers=None,dashes=None,
style_order=None,legend='brief',kind='scatter',
height=5,aspect=1,facet_kws=None,**kwargs)主要参数解析:
row,col:data中的变量名,确定网格分面的类别变量
kind:可选scatter,line
(其他常见参数参考以上示例)
sns.relplot(x='total_bill', y='tip', data=tip, hue='sex', style='time', size='size',
row='time', col='smoker')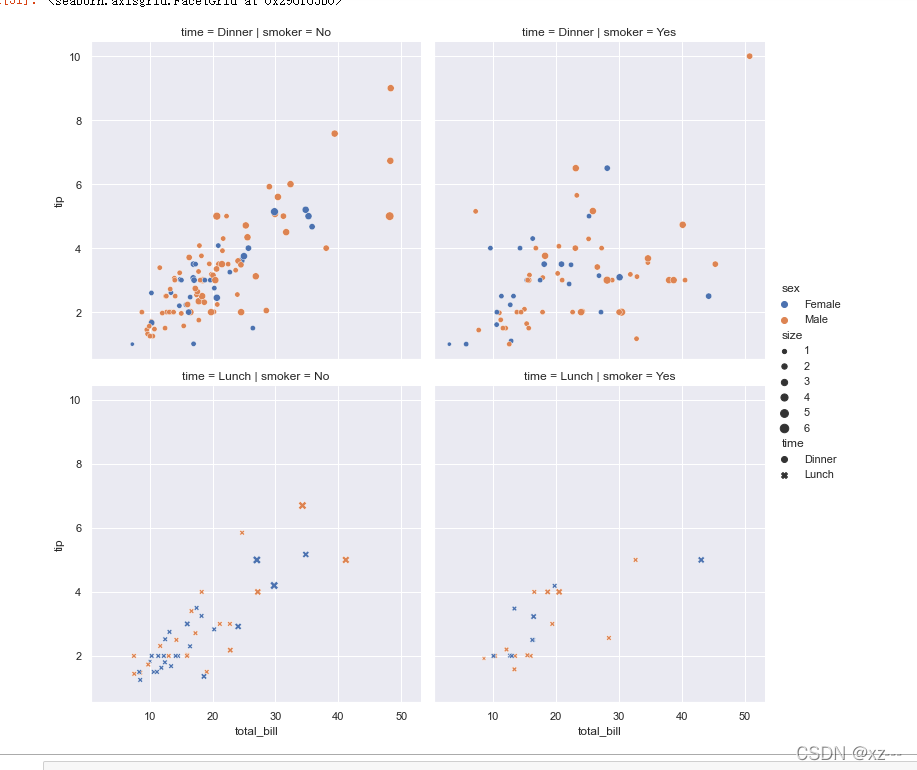
从这张图可以看到,添加了col和row变量后,能够更加清晰的为我们展示各个特征之间的关系。左上角第一个展示晚饭和不抽烟者的关系(仅仅是为了做示范)。
sns.relplot(x='timepoint', y='signal', data=fmri, hue='region', style='event',
row='event', col='region', kind='line')
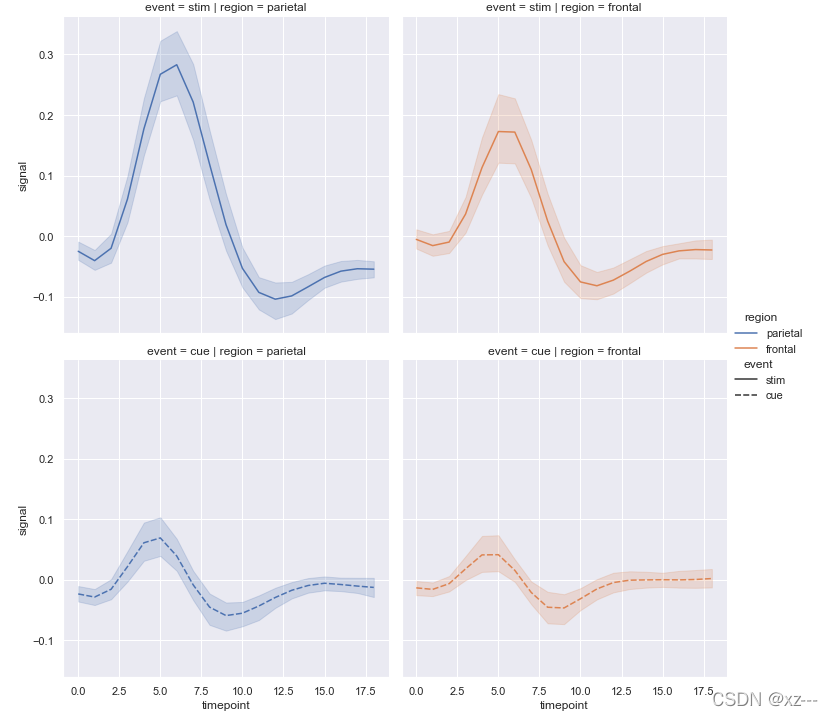
当参数kind=’line‘时,又可以得到另一个关系图标。
二、分类散点图
1.stripplot(分布散点图):
按照不同类别对样本数据进行分布散点图绘制。stripplot(分布散点图)一般并不单独绘制,它常常与boxplot和violinplot联合起来绘制,作为这两种图的补充。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, jitter=True, dodge=False, orient=None, color=None,
palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, **kwargs)
常用参数解析:
jitter:抖动项,表示抖动程度,float或True
dodge:重叠区域是否分开
order:命令绘制分类级别,否则从数据对象推断级别。
sns.stripplot(x='day', y='total_bill', data=tip)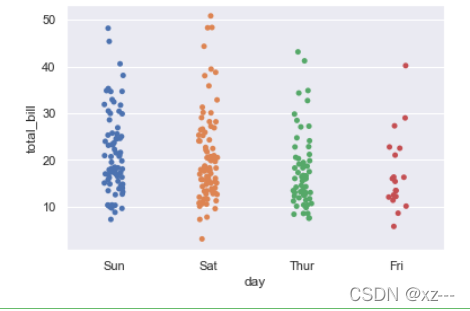
将total_bill按照day分成了四组
sns.stripplot(x='day', y='total_bill', data=tip, hue='time', dodge=True)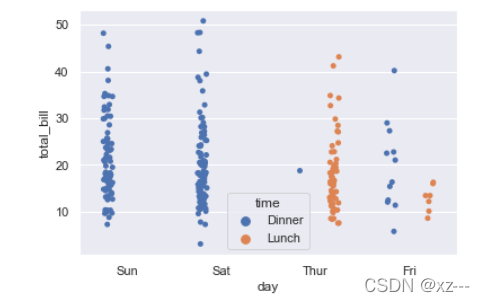
这里需要注意的是,使用了hue之后,dodge设置为True,则将重叠部分分开。
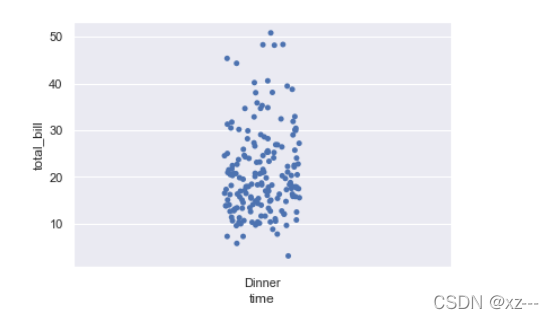
sns.stripplot(x='time', y='total_bill', data=tip, order=["Dinner"])使用order参数需要注意的是,order中的变量都要在x之中,否则只会显示画布。
2.swarmplot(分布密度散点图):这个函数类似于stripplot(),但是对点进行了调整(只沿着分类轴),这样它们就不会重叠。这更好地表示了值的分布,但它不能很好地扩展到大量的观测。
seaborn.swarmplot(x=None, y=None, hue=None, data=None, order=None,
hue_order=None, dodge=False, orient=None, color=None, palette=None, size=5,
edgecolor='gray', linewidth=0, ax=None, **kwargs)参数基本上与stripplot一致,在此不多做赘述。
sns.swarmplot(x='day', y='total_bill', data=tip)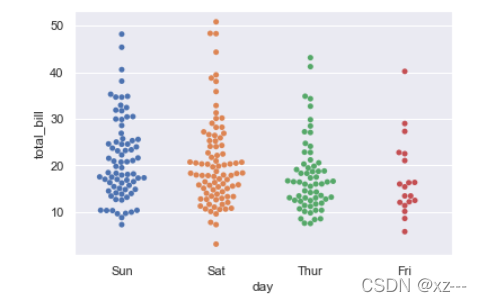
sns.swarmplot(x='day', y='total_bill', data=tip, hue='time', dodge=True)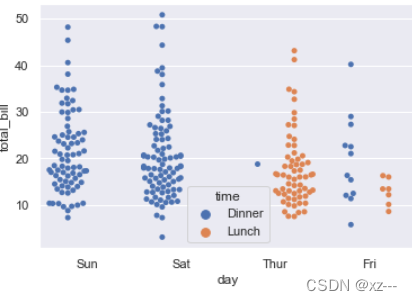

















 2373
2373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









