







03-04-Spatial Transformer Layer(选修)
不变性
不变性意味着即使目标的外观发生了某种变化,但是依然可以把它识别出来。这对图像分类来说是一种很好的特性,因为我们希望图像中目标无论是被平移,被旋转,还是被缩放,甚至是不同的光照条件、视角,都可以被成功地识别出来。
所以上面的描述就对应着各种不变性:
平移不变性:Translation Invariance
旋转/视角不变性:Ratation/Viewpoint Invariance
尺度不变性:Size Invariance
光照不变性:Illumination Invariance
参考:平移不变性(卷积神经网络为什么具有平移不变性?) - xiaobai_Ry
为什么CNN有transition invariant?
局部平移不变性是一个很有用的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时。
在神经网络中,卷积被定义为不同位置的特征检测器,也就意味着,无论目标出现在图像中的哪个位置,它都会检测到同样的这些特征,输出同样的响应。比如人脸被移动到了图像左下角,卷积核直到移动到左下角的位置才会检测到它的特征。
简单地说,卷积+最大池化约等于平移不变性。即为参数共享和池化使卷积神经网络具有一定的平移不变性。
1 卷积
简单地说,图像经过平移,相应的特征图上的表达也是平移的。下图只是一个为了说明这个问题的例子。
输入图像的左下角有一个人脸,经过卷积,人脸的特征(眼睛,鼻子)也位于特征图的左下角。
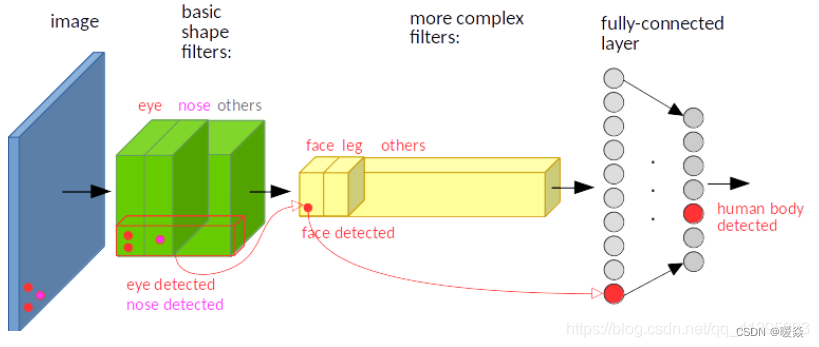
假如人脸特征在图像的左上角,那么卷积后对应的特征也在特征图的左上角。
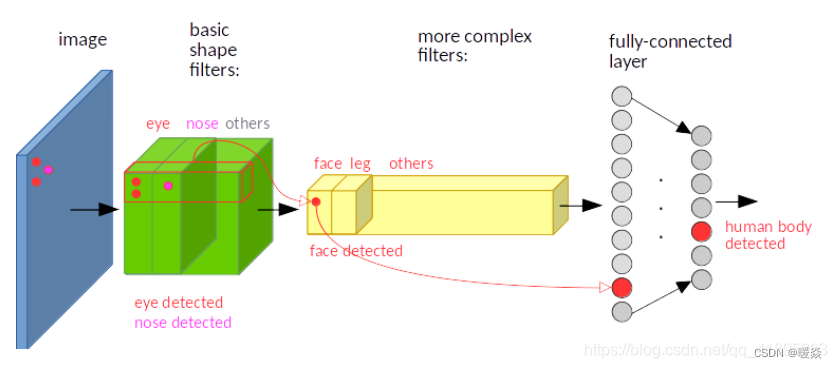
2 池化
比如最大池化,它返回感受野中的最大值,如果最大值被移动了,但是仍然在这个感受野中,那么池化层也仍然会输出相同的最大值。这就有点平移不变的意思了。
CNN并不是完全transition invariant
当目标小范围移动时,CNN才具有transition invariant,如果目标从左上角移动到了右下角,CNN没有平移不变性。
CNN 有不完全 transition invariant 无scaling invariant 无rotation invariant
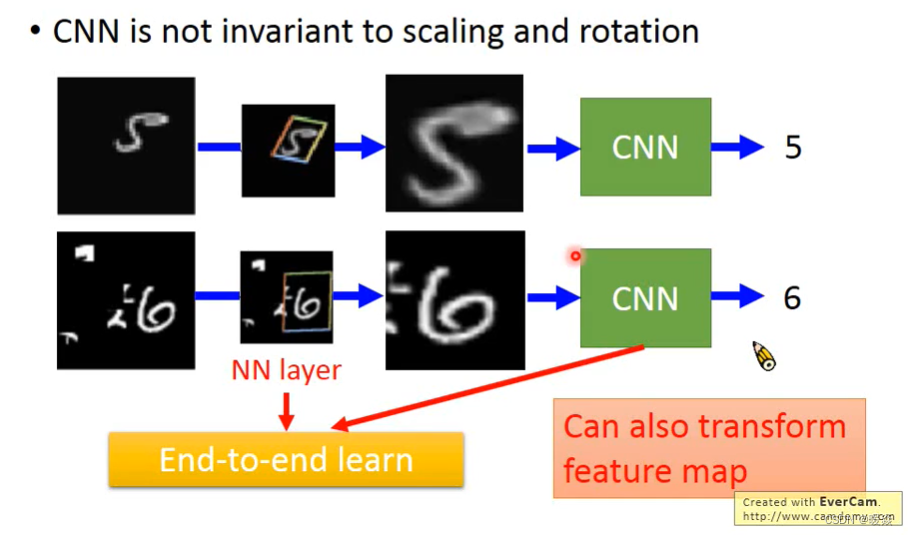
CNN的机理使得CNN在处理图像时可以做到部分平移不变性(transition invariant),却没法做到尺度不变性(scaling invariant)和旋转不变性(rotation invariant)。即使是现在火热的transformer搭建的图像模型(swin transformer, vision transformer),也没办法做到这两点。因为这些模型在处理时都会参考图像中物体的相对大小和位置方向。不同大小和不同方向的物体,对网络来说是不同的东西。这个问题在STL论文中统称为spatially invariant问题。甚至不同方向的物体,本身就真的是不同的东西,比如文字。
平移不变性(transition invariant):
例如:
尺度:模型可以预测大狗和小狗,不是因为模型尺度不变性,而是因为数据集中有大狗图片也有小狗图片。
旋转:数字3经过旋转可能被识别为m。
关于平移不变性 ,对于CNN来说,如果移动一张图片中的物体,那应该是不太一样的。假设物体在图像的左上角,做卷积操作,采样都不会改变特征的位置,糟糕的是若把特征平滑后后接入了全连接层,而全连接层本身并不具备 平移不变性 的特征。但是 CNN 有一个采样层,假设某个物体移动了很小的范围,经过采样后,它的输出可能和没有移动的时候是一样的,这是 CNN 可以有小范围的平移不变性 的原因。
其实pooling layer有一定程度上解决了这个问题,因为在做max pooling或者average pooling的时候,只要这个特征在,就可以提取出来,在什么位置,pooling layer是不关心的。但是pooling的kernel size通常都比较小,需要做到大物体的spatially invariant是很难的,除非网络特别深。
普通的CNN能够显示的学习平移不变性,以及隐式的学习旋转不变性,但 attention model 告诉我们,与其让网络隐式的学习到某种能力,不如为网络设计一个显式的处理模块,专门处理以上的各种变换。因此,DeepMind就设计了Spatial Transformer Layer,简称STL来完成这样的功能。
STN(spatial transformer network)的提出,就是为了解决spatially invariant问题。它的主要思想很简单,就是训练一个可以把物体线性变换到模型正常的大小和方向的前置网络。这个网络可以前置于任何的图像网络中,即插即用。同时也可以和整个网络一起训练。
Spatial Transformer Layer STL 概览
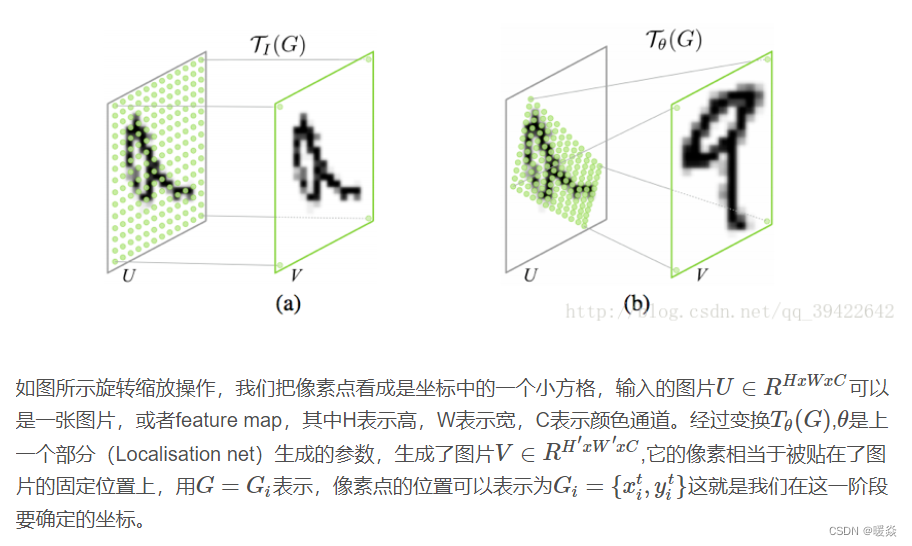
如图所示,如果是手写数字识别,图中只有一小块是数字,其他大部分地区都是黑色的,或者是小噪音。假如要识别,用Transformer Layer层来对图片数据进行旋转缩放,只取其中的一部分,放大之后然后经过CNN就能识别了。
STL 其实也是一个layer,放在了CNN前面,用来转换输入的图片数据,其实也可以转换feature map(一张特征图也可以看做一张图片),所以Transformer layer也可以放到CNN里面。
再说的直白一点,就是一个可以根据输入图片输出仿射变换参数的网络。
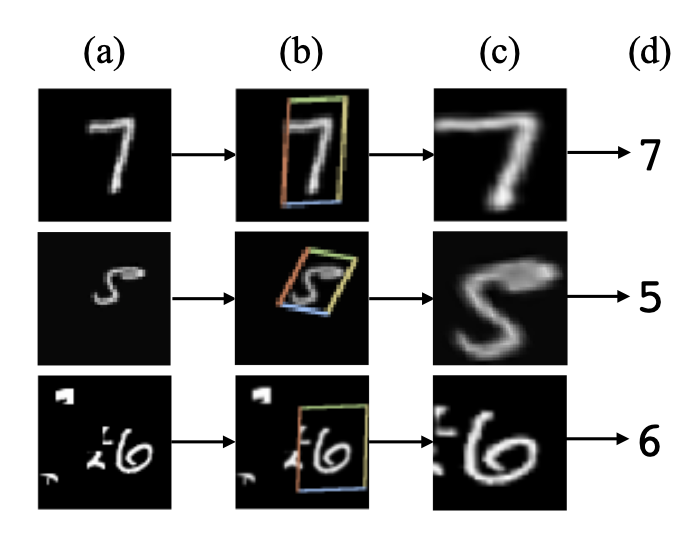
上图是STN网络的一个结果示意图,(a) 是输入图片,(b) 是STN中的localisation网络检测到的物体区域,(c) 是STN对检测到的区域进行线性变换后输出,(d) 是有STN的分类网络的最终输出。
STN如何实现Transform an image/feature map?- 引例:平移变换
如下图所示,平移功能,这其实就是Spatial Transformer Networks要做一个工作。
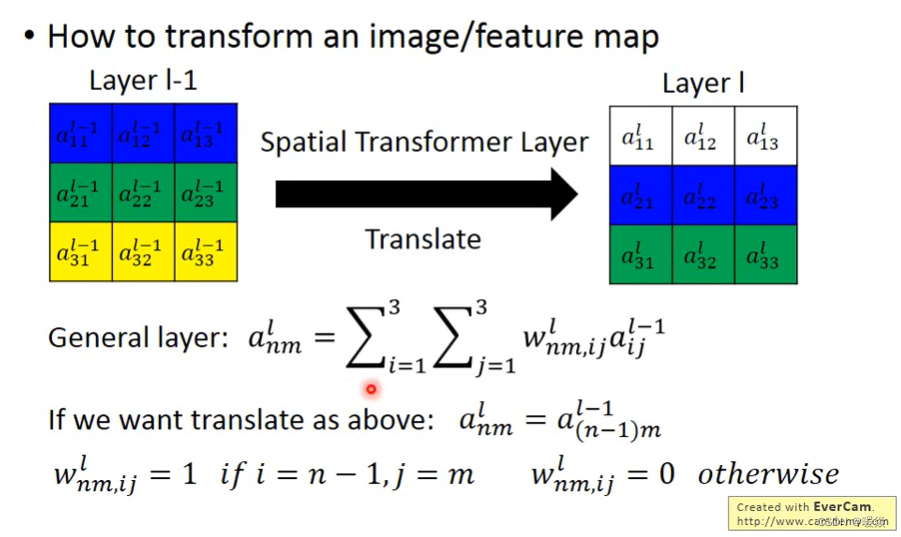
假设左边是 Layer l−1 的输出,也就是当前要做Transform的输入,最右边为Transform后的结果。这个过程是怎么得到的呢?
假设是一个全连接层,n,m代表输出的值在输出矩阵中的下标,输入的值通过权值w,做一个组合,完成这样的变换。
举个例子,假如要生成
a
11
l
a_{11}^l
a11l ,那就是将左边矩阵的九个输入元素,全部乘以一个权值,加权相加:
这仅仅是
a
11
l
a_{11}^l
a11l 的值,其他的结果也是这样算出来的,用公式表示称如下这样:
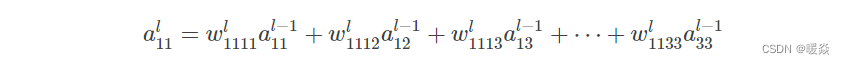
通过调整这些权值,达到缩放,平移的目的,其实这就是Transformer的思想。
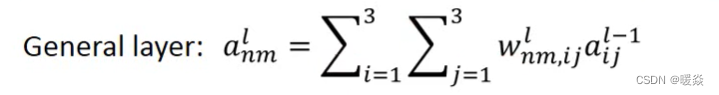
如何找到变换权重值?
将Layer l-1的输出值输入到NN中,NN输出Layer l-1 到 Layer1的权重。
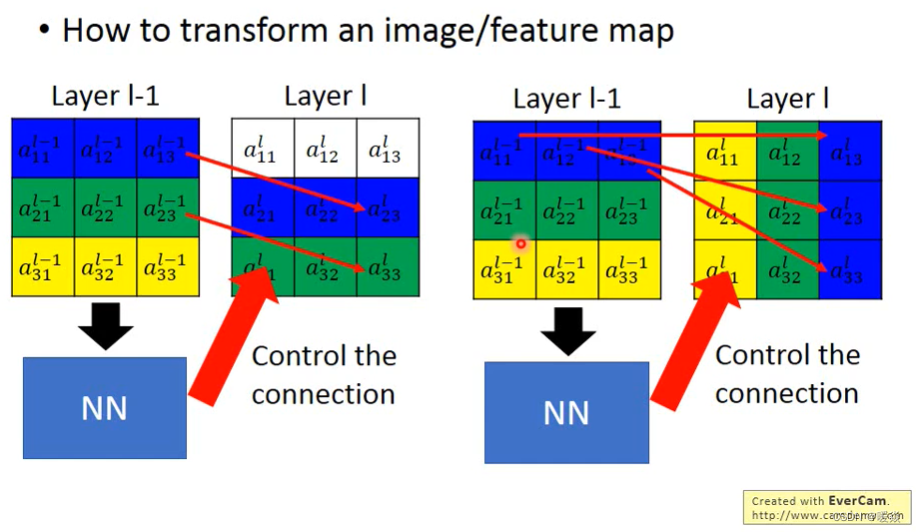
STN的基本架构
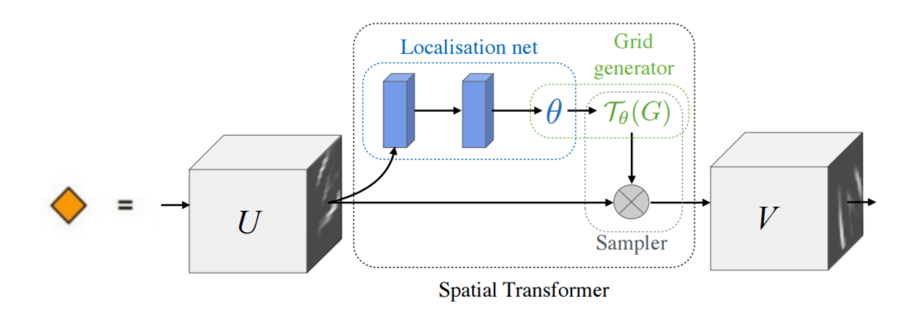
主要的部分一共有三个,它们的功能和名称如下:
参数预测:Localisation net
坐标映射:Grid generator
像素的采集:Sampler
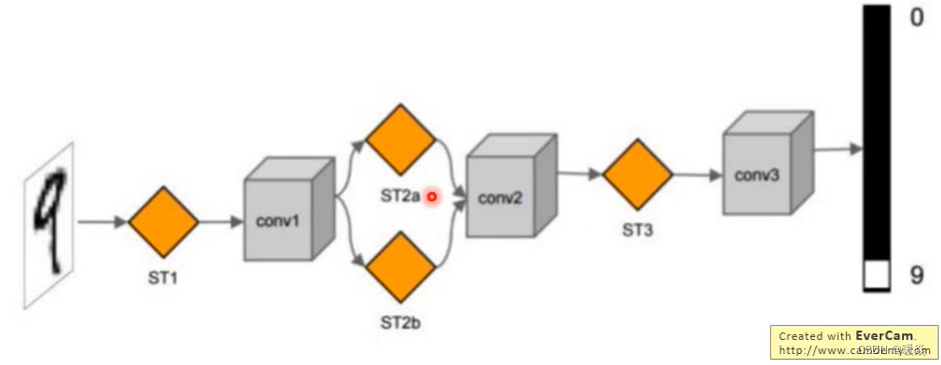
如上图,这个网络可以加入到CNN的任意位置,而且相应的计算量也很少。
将 spatial transformers 模块集成到 cnn 网络中,允许网络自动地学习如何进行 feature map 的转变,从而有助于降低网络训练中整体的代价。定位网络中输出的值,指明了如何对每个训练数据进行转化。
变换过程中,需要面对三个主要问题:
① 公式中参数应该怎么确定?
② 图片的像素点可以当成坐标,在平移过程中怎么实现原图片与平移后图片的坐标映射关系?
③ 参数调整过程中,权值一定不可能都是整数,那输出的坐标有可能是小数,但实际坐标都是整数的,如何实现小数与整数之间的连接?
其实定义的三个部分,就是专门为了解决这几个问题的,接下来我们一个一个看一下怎么解决。
如何实现参数选取?- Localisation net?
如果只是旋转、平移、缩放三种变换(都是 affine transformation),只需要确定6个参数。
线性变换从几何直观有三个要点:① 变换前是直线的,变换后依然是直线。② 直线比例保持不变。> ③ 变换前是原点的,变换后依然是原点。
仿射变换从几何直观只有两个要点(少了原点保持不变):① 变换前是直线的,变换后依然是直线。② 直线比例保持不变。
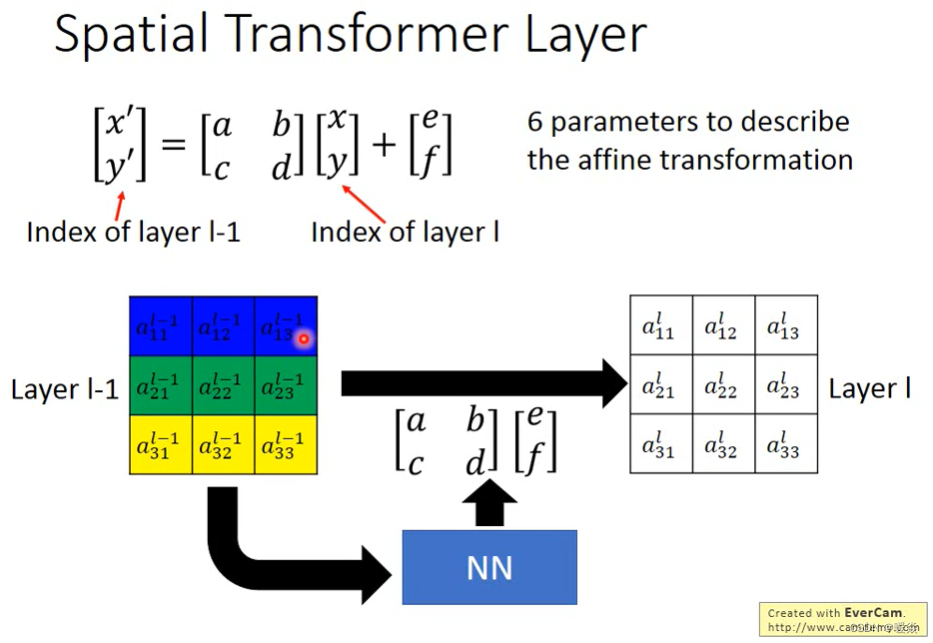
[x,y] 对应输出 layer l 中的索引,[x’,y’] 对应输入 layer l-1 中的索引。
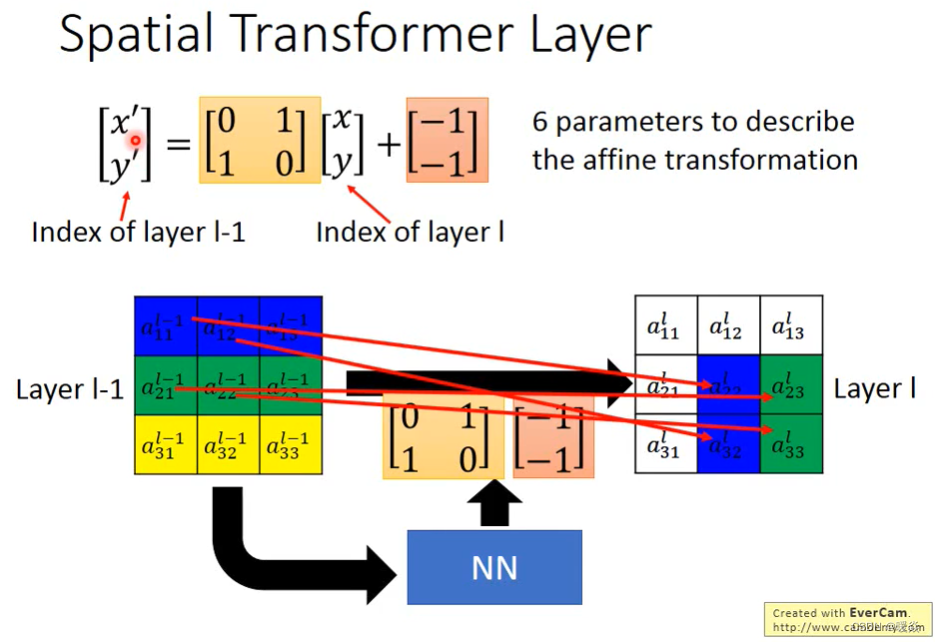
例如:
Layer l 中 a 22 l a_{22}^{l} a22l 的下标为(2, 2),则公式中x=2,y=2,代入公式得到 x ′ = 1 , y ′ = 1 x'=1,y'=1 x′=1,y′=1。则Layer l-1中 a 11 l − 1 a_{11}^{l-1} a11l−1 映射到 Layer l 中 a 22 l a_{22}^{l} a22l

实现平移

这就完成了平移了吗?其他的平移也可以用类似的方法来做到。
你可能会问了,那我该怎么得到这些权值呢?总不能人工去看吧!
当然不会,可以设置一个叫做NN这类的东西,把 Layer l−1 的输出放到NN里,然后生成一系列w。这样听起来好玄乎,但确实是可以这么做的。
实现缩放
其实缩放也不难,如图所示,如果要把图放大来看,在x→(X2)→x′,y→(X2)→y′将其同时乘以2,就达到了放大的效果了。
缩小也是同样的原理,如果把这张图放到坐标轴来看,就是如图所示,加上偏执值0.5表示向右,向上同时移动0.5的距离,这就完成了缩小。
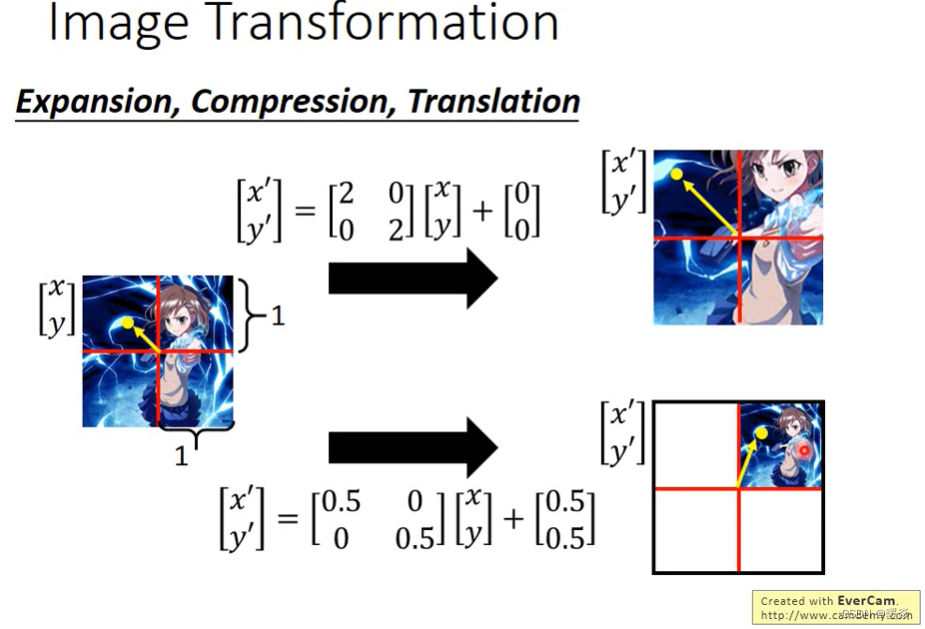
实现旋转
既然前面的平移和缩放都是通过权值来改的,那旋转其实也是。但是旋转应该用什么样的权值呢?
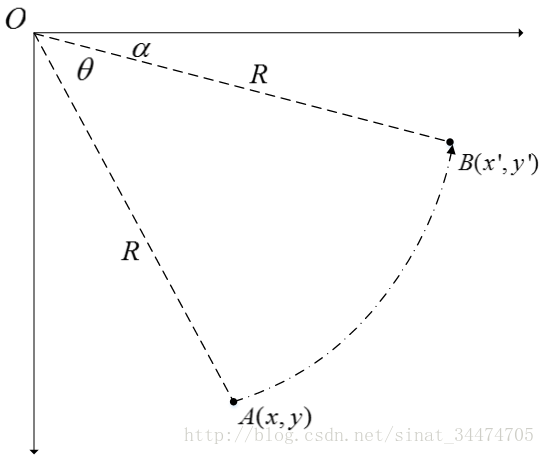
仔细思考,不难发现,旋转是跟角度有关系的,那什么跟角度有关系呢?- 正弦余弦
为什么正弦余弦能做旋转呢?
一个圆圈的角度是360度,可以通过控制水平和竖直两个方向,就能控制了,如图所示。

可以简单的理解为 cosθ,sinθ 就是控制这样的方向的,把它当成权值参数,写成矩阵形式,就完成了旋转操作。
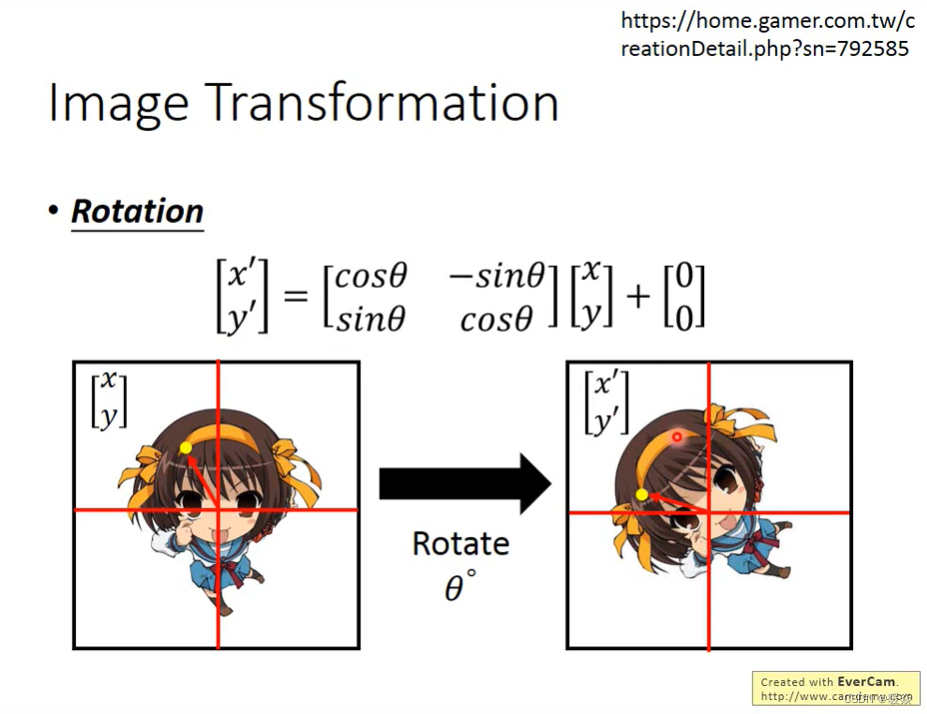
注:如果想了解正余弦控制方向是怎么导出的,可以参考计算机图形学的相关书籍,一般都有介绍和数学公式的推导。
实现剪切
剪切变换相当于将图片沿x和y两个方向拉伸,且x方向拉伸长度与y有关,y方向拉伸长度与x有关,用矩阵形式表示前切变换如下:
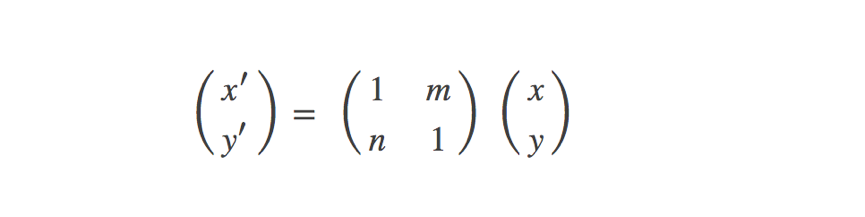
小结
由此,我们发现所有的这些操作,只需要六个参数[2X3]控制就可以了,所以我们可以把feature map U作为输入,过连续若干层计算(如卷积、FC等),回归出参数θ,在我们的例子中就是一个[2,3]大小的6维仿射变换参数,用于下一步计算;
如何实现像素点坐标的对应关系?- Grid generator
为什么会有坐标的问题?- 采样前后像素点坐标对应关系表示
由上面的公式,可以发现,无论如何做旋转,缩放,平移,只用到六个参数就可以了,这6个参数,就足以完成需要的几个功能了。
而缩放的本质,其实就是在原样本上采样,拿到对应的像素点,通俗点说,就是输出的图片(i,j)的位置上,要对应输入图片的哪个位置?
如何表示采样前后像素点坐标对应关系? - 仿射变换关系
STL论文中定义了如图的一个坐标矩阵变换关系:
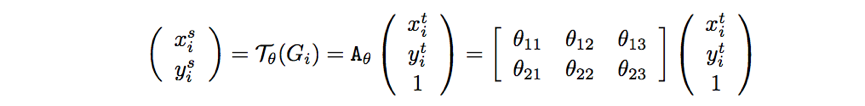
( x t i , y t i ) (x_t^i,y_t^i) (xti,yti)是输出的目标图片的坐标, ( x s i , y s i ) (x_s^i,y_s^i) (xsi,ysi)是原图片的坐标,Aθ表示仿射关系。
但仔细一点,这有一个非常重要的知识点,千万别混淆,坐标映射关系是:
从目标图片→原图片
也就是说,坐标的映射关系是从目标图片映射到输入图片上的,为什么这样呢?
作者在论文中写的比较模糊,比较满意的解释是坐标映射的作用,其实是让目标图片在原图片上采样,每次从原图片的不同坐标上采集像素到目标图片上,而且要把目标图片贴满,每次目标图片的坐标都要遍历一遍,是固定的,而采集的原图片的坐标是不固定的,因此用这样的映射。
举例说明。

如图所示,假设只有平移变换,这个过程就相当于一个拼图的过程,左图是一些像素点,右图是我们的目标,我们的目标是确定的,目标图的方框是确定的,图像也是确定的,这就是我们的目标,我们要从左边的小方块中拿一个小方块放在右边的空白方框上,因为一开始右边的方框是没有图的,只有坐标,为了确定拿过来的这个小方块应该放在哪里,我们需要遍历一遍右边这个方框的坐标,然后再决定应该放在哪个位置。所以每次从左边拿过来的方块是不固定的,而右边待填充的方框却是固定的,所以定义从目标图片→原图片的坐标映射关系更加合理,且方便。
如何解决小数坐标不可微?- Sampler 插值 Interpolation
为什么小数坐标不可微?- 微分为0无法梯度下降
前面举的例子中,权值都是整数,那得到的也必定是整数,如果不是整数呢?
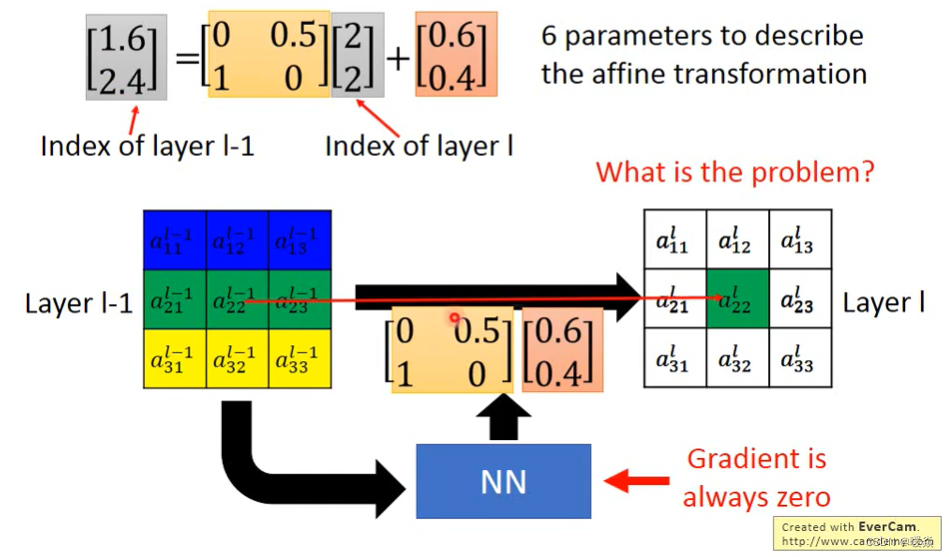
假如权值是小数,拿得到的值也一定是小数,1.6,2.4,但是没有元素的下标索引是小数呀。
有一种错误的思路:四舍五入,若结果为1.6,2.4,取2,2,也就是与 a 22 l − 1 a_{22}^{l-1} a22l−1对应了。
这种四舍五入的做法可能导致梯度不能更新。上例中:[2,2]计算结果为[1.6,2.4],对结果四舍五入后为[2,2]。
梯度下降是一步一步调整的,而且调整的数值都比较小,哪怕权值参数有小范围的变化,虽然最后的输出也会有小范围的变化,比如一步迭代后,结果有:1.6→1.64,2.4→2.38。但是即使有这样的改变,结果依然是 a 22 l − 1 → a 22 l a_{22}^{l-1}→a_{22}^{l} a22l−1→a22l 的对应关系,图像没有一点变化,所以output依然没有变,微分为0,也就是梯度为0,梯度为0就没有可学习的空间。
当6个参数
[
a
,
b
,
c
,
d
,
e
,
f
]
[a,b,c,d,e,f]
[a,b,c,d,e,f] 发生微小的变化之后,下一层的特征也发生变化,这样才可以保证可以梯度下降。所以需要做一个小小的调整,即插值Interpolation。
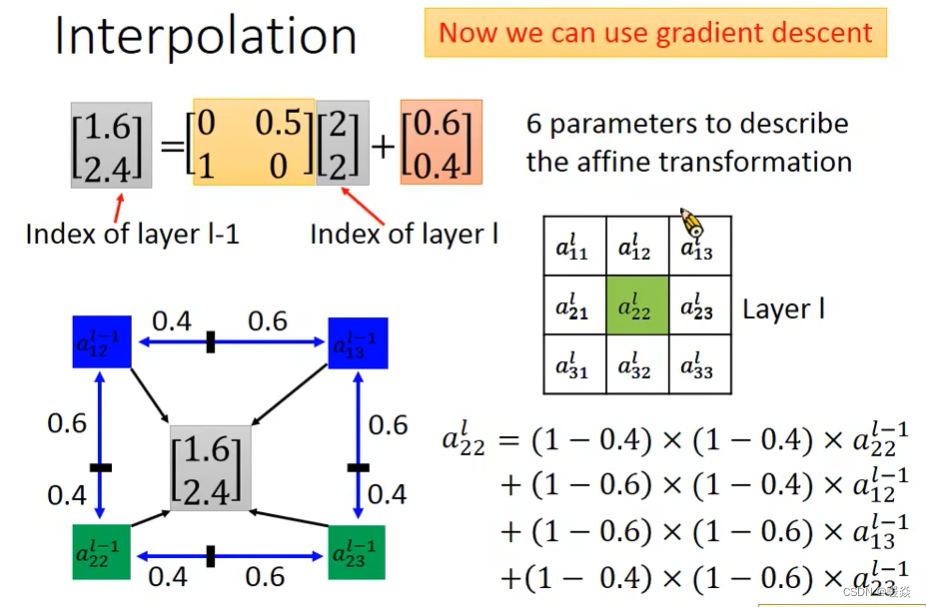
Sampler 如何插值?
这种梯度不能更新的问题,其实在推导SVM的时候,也遇到过相同的问题,如果只是记录那些出界的点的个数,好像也是不能求梯度的,当时是用了hing loss,来计算一下出界点到边界的距离,来优化那个距离的,这里也类似,可以计算一下到输出[1.6,2.4]附近的主要元素,如下所示,计算一下输出的结果与他们的下标的距离,可得:
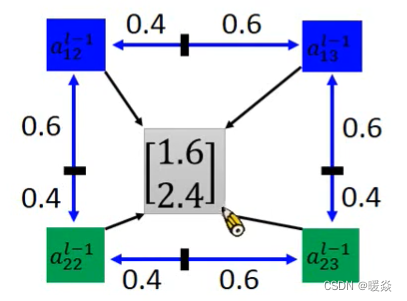
然后做如下更改:
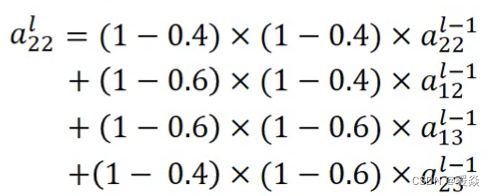
采用了插值的方法来进行采样。比如当坐标为 [ 1.6 , 2.4 ] [1.6,2.4] [1.6,2.4]时,就用 [ a 12 l − 1 , a 13 l − 1 , a 22 l − 1 , a 23 l − 1 ] [a_{12}^{l-1}, a_{13}^{l-1}, a_{22}^{l-1}, a_{23}^{l-1}] [a12l−1,a13l−1,a22l−1,a23l−1]这几个值进行插值。这样一来 [ a , b , c , d , e , f ] [a,b,c,d,e,f] [a,b,c,d,e,f]发生微小的变化之后, [ x , y ] [x,y] [x,y]位置采样得到的值也会有变化了,就可以使用梯度下降优化网络。(之前四舍五入的方案不会产生变化所以不能使用梯度下降优化网络)。这也使得spatial transformer可以放到任何层,跟整个网络一起训练。
对应的权值都是与结果对应的距离相关的,当6个参数发生变化时,这个式子也是可以捕捉到这样的变化的,就可以算出非0梯度,这样就能用梯度下降法来优化了。
Sampler 数学原理
STL论文作者对前面的过程给出了非常严密的证明过程,以下是对论文的转述。
每次变换,相当于从原图片(xsi,ysi)(xis,yis)中,经过仿射变换,确定目标图片的像素点坐标(xti,yti)的过程,这个过程可以用公式表示为:
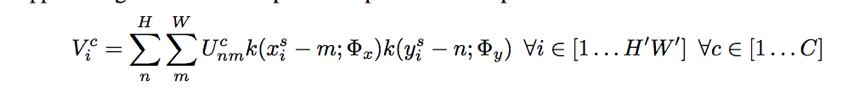
注:把一张图片展开,相当于把矩阵变成坐标向量。
kernel k表示一种线性插值方法,比如双线性插值,更详细的请参考:(线性插值,双线性插值Bilinear Interpolation算法),ϕx,ϕy 表示插值函数的参数; U n m c U^c_{nm} Unmc表示位于颜色通道C中坐标为(n,m)的值。
如果使用双线性插值,可以有:
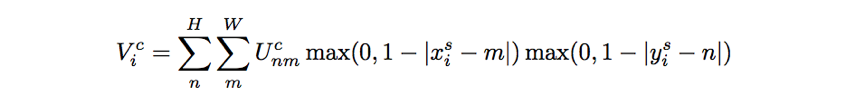
为了允许反向传播回传损失,可以对该函数求偏导:
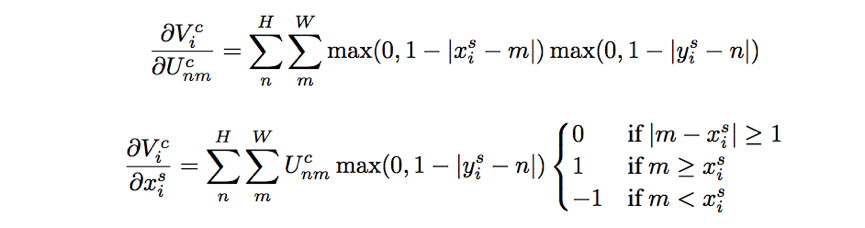
对于 ∂ y i s / ∂ θ ∂y_i^s/∂θ ∂yis/∂θ也类似。
如果就能实现这一步的梯度计算,而对于 ∂ x i s / ∂ θ , ∂ y i s / ∂ θ ∂x_i^s/∂θ, ∂y_i^s/∂θ ∂xis/∂θ,∂yis/∂θ的求解也很简单,所以整个过程Localisation net←Grid generator←Sampler的梯度回转就能走通了。
STL 效果
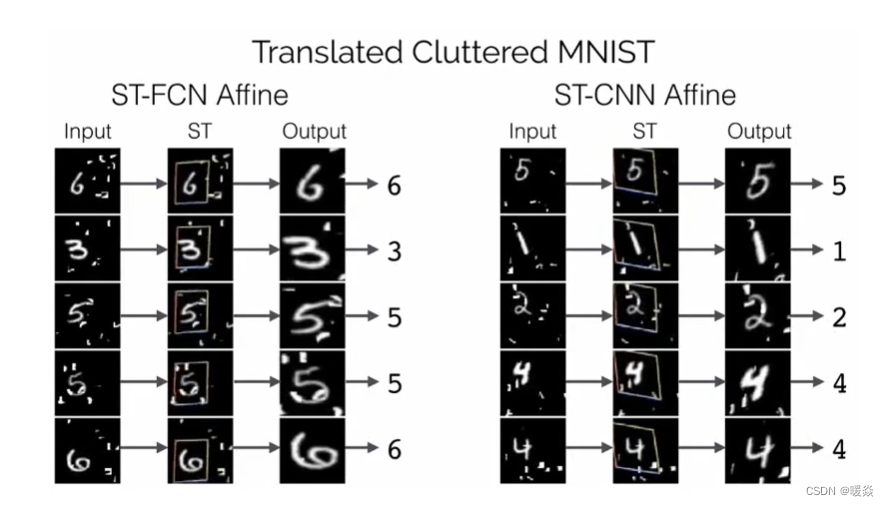
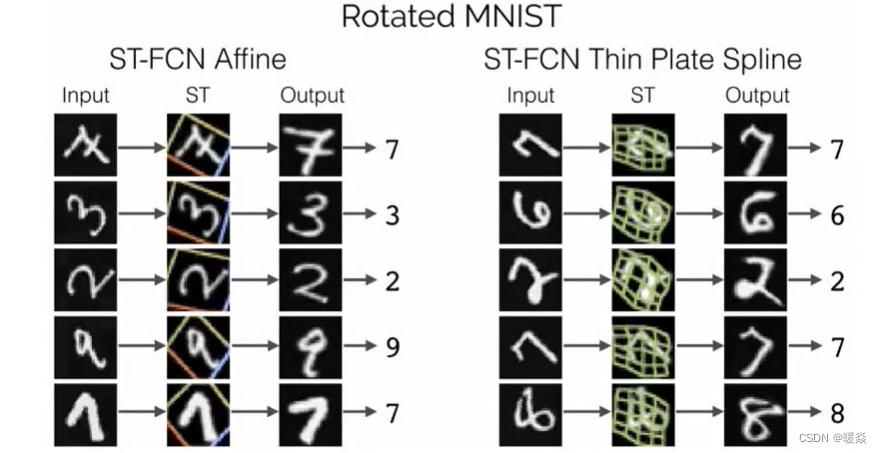
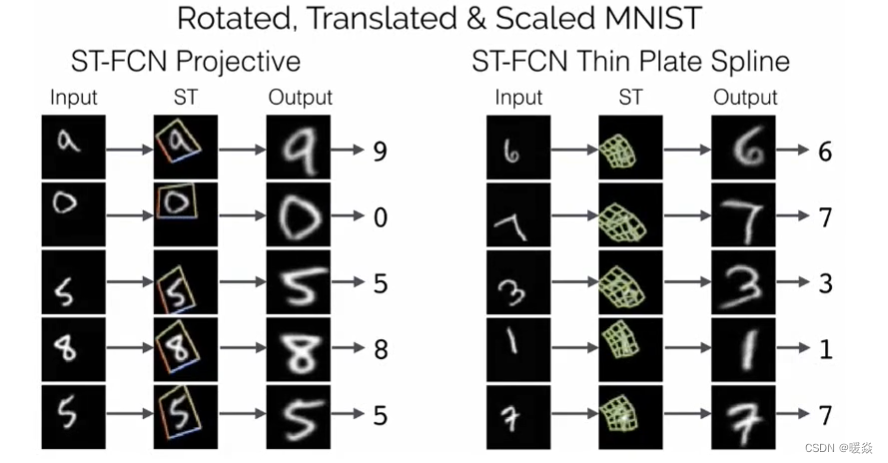
文字识别任务
下图表示了STN加入到文字识别任务时带来的效果提升,下图左侧是不同模型在SVHN数据集上的错误率。这相当于是一个只有数字的文字识别任务。
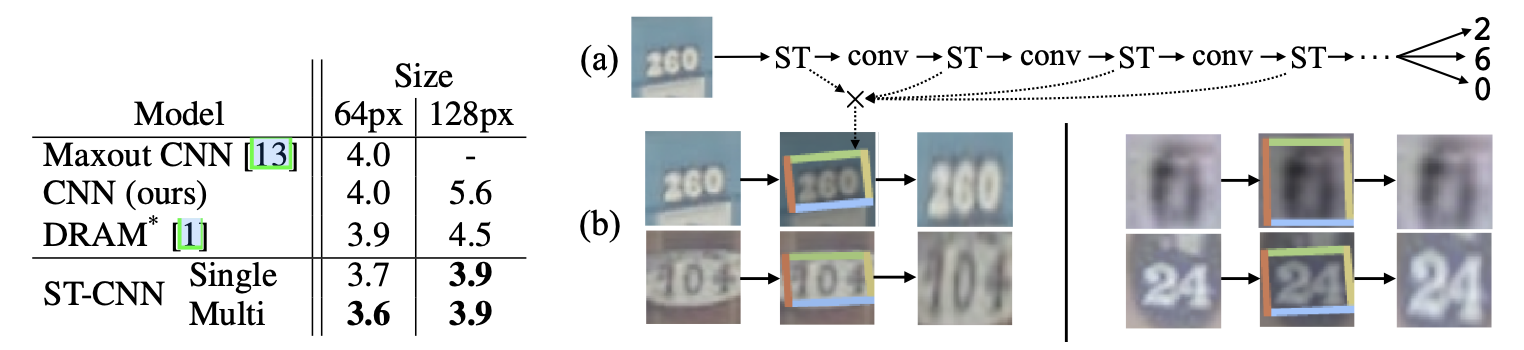
不过用在OCR任务中,STN其实有点鸡肋。OCR有文字检测和文字识别两个部分,一般文字检测部分会带有检测框四个顶点的坐标,我们直接把文字检测的结果进行仿射变换再去文字识别就可以了,不需要在文字识别时再加一个STN。一个是难训练,再就是推理性能下降。
图像分类任务
下图表示了STN在图像识别任务的效果,左下角表格表示了不同模型在Caltech-UCSD Birds-200-2011数据集上的准确率。
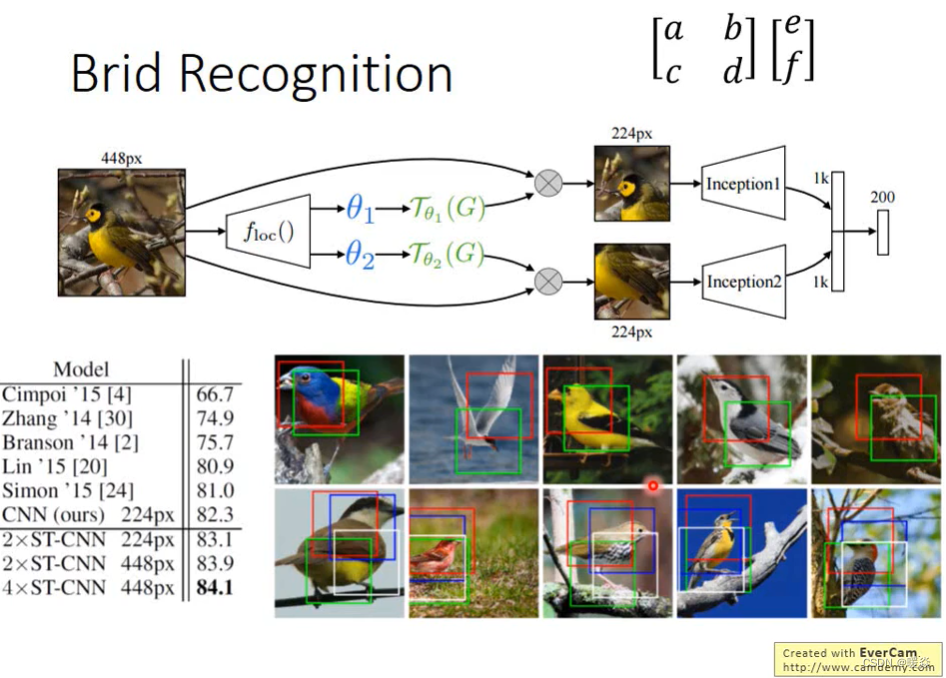
2×ST−CNN表示在同一层是用了两个不同的STL,4 × ST − CNN 表示在同一层是用了四个不同的STL。图3-2右侧中的方框表示了不同STL要进行放射变换的位置。
可以看到不同的STL关注的鸟的部位也是不一样的,一个一直关注头部,一个一直关注身子。这就相当于是一个attention,把感兴趣的区域提取出来了。
还有一个地方是,这里的方框都是正的,这其实是因为作者把仿射变换中的参数 [ b , c ] [b,c] [b,c]人为置0了,变成了
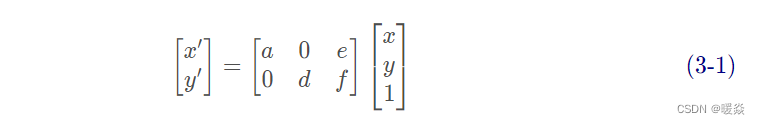
可见STN是一个可以融入到很多图像模型,且可拓展性高的模块。
参考
详细解读Spatial Transformer Networks(STN)-一篇文章让你完全理解STN了
论文阅读:Spatial Transformer Networks















 5978
5978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









