







昨天在csdn上看到这样的帖子:http://topic.csdn.net/u/20090316/11/feb21d98-ef52-422c-a3eb-2de211963533.html?seed=1379459908
for(int i=1,n=tempUser.length;i <n;i++)与
for(int i=1,;i <tempUser.length;i++)相比较,性能有较大的区别吗,有必要采取这种写法吗,
习惯for(int i=1,;i <tempUser.length;i++),而且并没有发现两者的性能有较大差别,
我当即就测试了一下,发现果然性能比较起来差别很小,甚至后者更高效一点。
虽然得出这样的结果,但和自己心里想的确完全相反的。所有当然就回复说差不多。
今天又发现一位前辈的blog中正好有对这个帖子的回应。他做了测试,内容大致是前面的帖子的问题应该是差不多的,但是他又更深入的进行测试,得出:在有情况for(int i=0;i<a.b.c.length;i++)的情况的时候,使用for(int i=0,n=a.b.c.length;i<n;i++)更加高效。
所有我也做了一下测试:
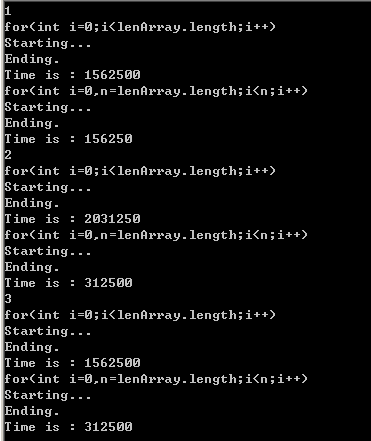
其中数据量越大,类越大,差别越明显。
结论:影响应该在,变量在每次循环都要访问下一级变量的原因。如果只是简单的a.length可能编译器对这样的循环操作有优化,将a.length保存到了内存或一个比内存更块的地方,而多级就没有这么幸运了。
我们都知道for(int i=0;i<a.length;i++)语句,i=0是运行一次,而i<a.length和i++是每次循环都要做的工作。所有应该尽量将访问变量耗时间的操作放在第一个;号前。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









