






VDSR(Accurate Image Super-Resolution Using Very Deep Convolutional Networks)阅读笔记
1、论文地址:https://arxiv.org/abs/1511.04587
2、github上tensorflow代码:https://github.com/Jongchan/tensorflow-vdsr
github上pytorch代码:https://github.com/twtygqyy/pytorch-vdsr
3、论文介绍
3.1、SRCNN的缺点
- 所依赖的图形上下文太小;
- 迭代收敛的太慢;
- 网络只能是指定的大小,当需要新的大小的时候还要重新去训练网络。
3.2、解决方法
- 通过使用深度卷积的方法,同时在卷积结束后将得到的结果扩展到原来图像的大小同时增加了感受野的大小,使得的所依赖的图像变大;
- 通过残差和较大的学习率(在训练过程中在不断改变)加快了迭代;
- 通过使用不同大小的数据进行训练,使得网络可以适应不同需求的scale,这部分是将原始数据通过多个不同的scale进行下采样,之后对下采样的数据在使用对应的scale进行上采样,得到低分辨率图像,比如首先将高分辨率图像分别使用[2,3,4]三个尺度使用双三次插值进行下采样,之后在使用[2,3,4]三个尺度上采样,得到相同的图像,这样在网络的输入的时候保证了输入图像的一致性,而不用考虑在网络中的针对不同尺度下采样的上采样过程。
3.3、VDSR网络
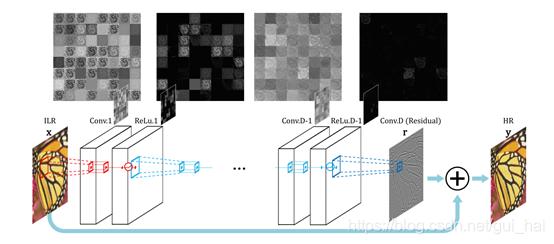
使用20层卷积,每次的卷积核都为3✖3乘以64,为了避免每次卷积结束后所得到的图片变小,使得在进行多次卷积之后图片太小,所以每次在卷积之前都会先将图片周围补0,使得该图片与原来的图片大小相同。实验证明这个方法对于实验结果始有帮助的。
3.4、残差学习
由于低分辨率的图片和高分辨率的图片在在很大程度上都是相似的,SRCNN像是在训练一个编码器啊,因此会消耗大量的时间,这个论文通过训练残差,减少了训练的时间。
Loss =1/2( y-x-f(x)) y表示高分辨率图片,x便是低分辨率图片 残差r = y-x 。
3.5学习率改变
使用较大的学习率,这样可以加快迭代所需的时间,但是会导致梯度爆炸,因此引入了可调整的梯度下滑,将梯度限制在一个范围之内。限制梯度在[-0/r,0/r]之间r便是当前的学习率。
3.6、多个scale
同时使用多个不同scale的图片进行训练,使得网络可以得到不同大小的图片。
3.7、代码介绍
未完待续。。。

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









