







引入本文件需要用到的包
参数直接填写请求对象
encode将携带的参数转换为bytes类型
import urllib
from urllib import request, parse, response
一.使用urllib发起请求
.read() 函数读取响应中的响应数据
decode() 将bytes类型的数据转换为str类型
rep = request.urlopen('http://www.baidu.com')
# .read() 函数读取响应中的响应数据
# print(rep.read())
result = rep.read()
# decode() 将bytes类型的数据转换为str类型
html = result.decode('utf-8')
# print(html)print(rep.getcode())print(rep.info())print(rep.geturl())二.携带请求头发送请求
1.获取百度的网页源代码
构建请求对象
req = request.Request('http://www.baidu.com', headers={
'User-Agent': 'python2.7',
'Host': 'www.baidu.com'
})参数直接填写请求对象
rep = request.urlopen(req)
print(rep.read().decode('utf-8'))2.发起post请求,携带参数
---------------------------------抽屉网-------------------
data = {"phone": "8615896901897", "password": "qweqweqwe1", "oneMonth": "1"}encode将携带的参数转换为bytes类型
data = parse.urlencode(data).encode('utf-8')headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"}req = request.Request(
url='http://dig.chouti.com/login',
data=data,
headers=headers
)rep = request.urlopen(req)
print(rep.read().decode('utf-8'))
完整代码
# -*- coding:utf-8 -*-
# urllib urllib2
import urllib
from urllib import request, parse, response
# 使用urllib发起请求
rep = request.urlopen('http://www.baidu.com')
# .read() 函数读取响应中的响应数据
# print(rep.read())
result = rep.read()
# decode() 将bytes类型的数据转换为str类型
html = result.decode('utf-8')
# print(html)
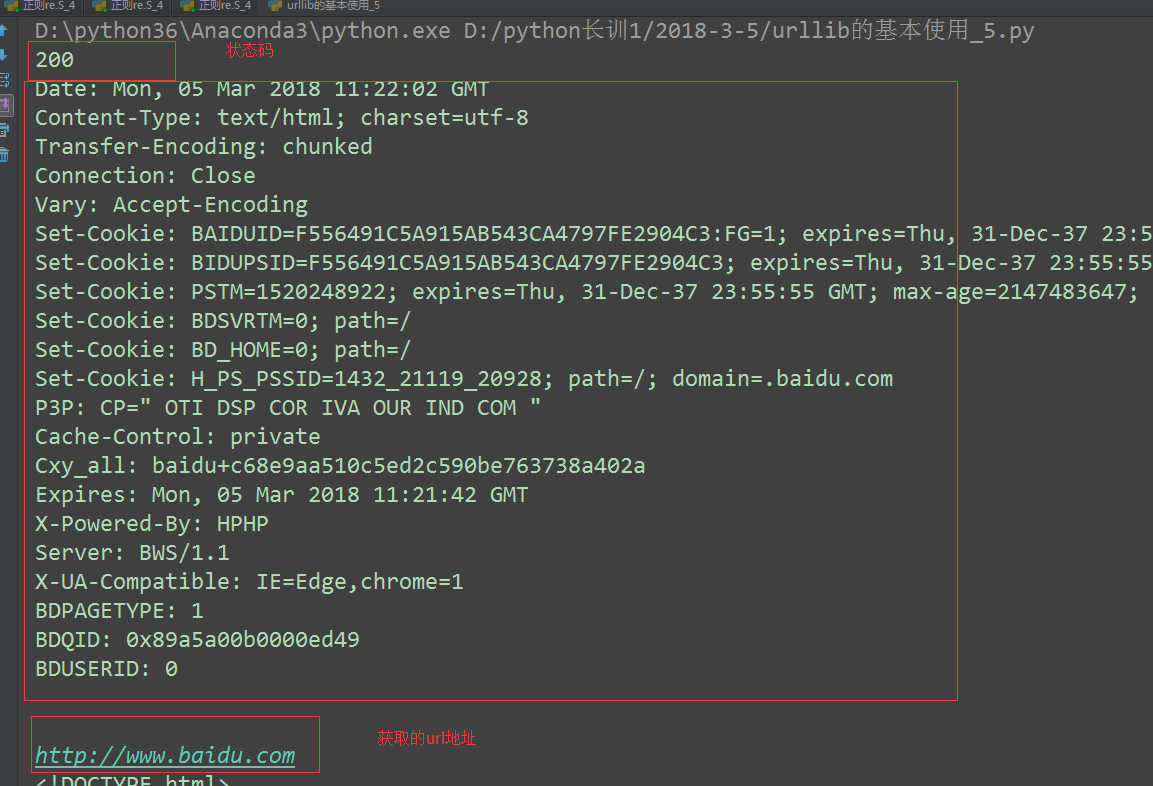
# 获取响应状态码
print(rep.getcode())
# 获取响应头信息
print(rep.info())
# 获取url地址
print(rep.geturl())
# 携带请求头发送请求
# 1.构建请求对象
req = request.Request('http://www.baidu.com', headers={
'User-Agent': 'python2.7',
'Host': 'www.baidu.com'
})
# 2.使用urlopen函数,发起请求
# 参数直接填写请求对象
rep = request.urlopen(req)
print(rep.read().decode('utf-8'))
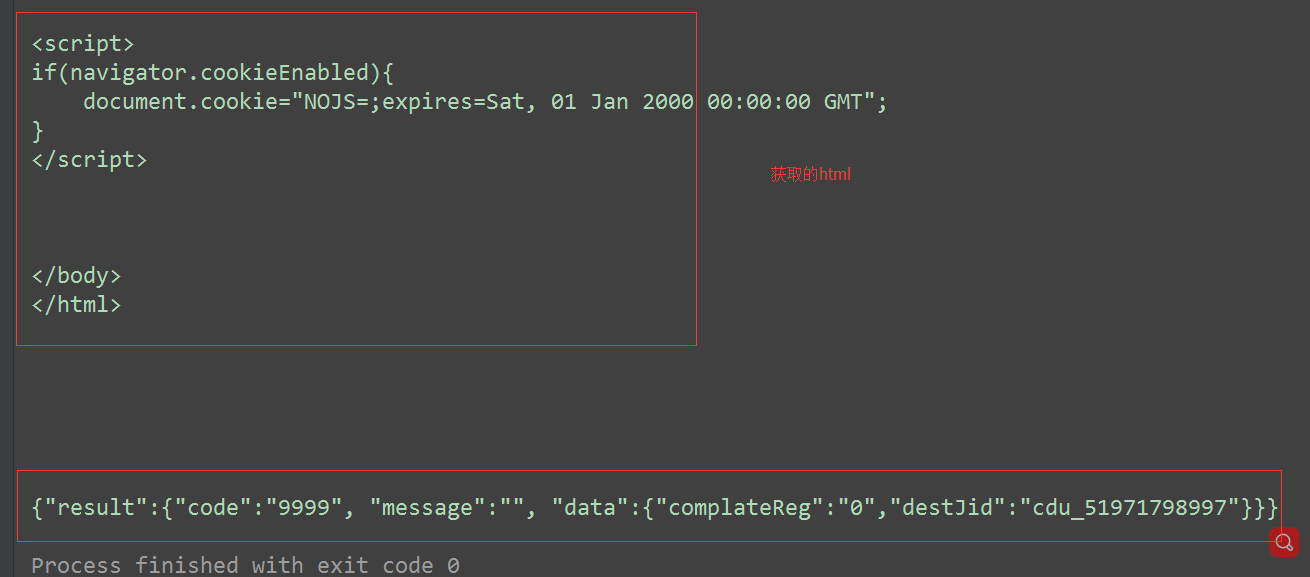
# ---------------------------------抽屉网----------
# 3.发起post请求,携带参数
# 携带的数据
data = {"phone": "8615896901897", "password": "qweqweqwe1", "oneMonth": "1"}
# 假如请求数据中有中文,需要对中文进行编码
# encode将携带的参数转换为bytes类型
data = parse.urlencode(data).encode('utf-8')
# 请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"}
# 构建请求对象
req = request.Request(
url='http://dig.chouti.com/login',
data=data,
headers=headers
)
# 发起请求
rep = request.urlopen(req)
print(rep.read().decode('utf-8'))
运行结果

















 4888
4888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









