






协同过滤(collaborative filtering)算法是一种入门级推荐算法,实现简单、可解释性强、效果尚可,有大量可调整的点。
问题定义
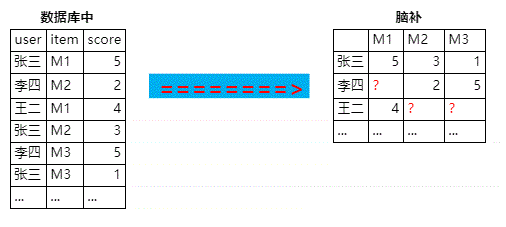
你的数据库里有一些打分记录了,你想算出更多的打分(红色的问号)
算法步骤
step1:确定基于user还是基于item。
一般基于数量少的那个。
- 例如,一个视频网站有上1万用户,50个视频,那么就基于item(视频)。
- 目的是计算出可信度高的相似矩阵,顺便减少计算量和存储量,这个案例中,只需要存储一个50×50的相似矩阵。
step2:计算相似矩阵
(使用余弦相似度,不是相关系数,想想为什么)
- 把图中的
?补0 - 然后计算余弦相似矩阵
得到类似这样的结果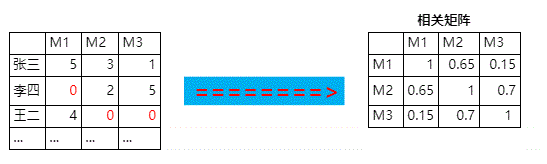
step3:把未知值填充起来。
例如,score(李四, M1) 是未知的,怎样计算这个数字呢?
横着看李四这一行,score(李四, M2)×rho(M1, M2)+score(李四, M3)×rho(M1, M3)=2×0.65+5×0.7=2.05
特点
- 一项可以很稀疏,另一项不可以稀疏。
- 逻辑简单,可解释性强。(上面step3计算时的每一项都可以拿出来做出解释)
- 与node2vec比起来,更准确,但覆盖不够(显然,模型也简单许多)
- 冷启动问题很难解决。(很多推荐算法都有这个问题)
- 换个视角看,这个模型实际上是基于图的(虽然从头到尾都没显性的构建 graph)
sql实现
做项目时发现,轻量级应用的探索过程中,用 Python 往往内存不够。
机智地想到用纯SQL去算,这样便可借助 Hive 等分布式计算能力。
step0:准备数据
create table table_origin_data(
user string,
item string,
score double
);
insert into table_origin_data values
('张三','M1',5),
('李四','M2',2),
('王二','M1',4),
('张三','M2',3),
('李四','M3',5),
('张三','M3',1);
SELECT * FROM table_origin_data;
step1:计算相关矩阵
--step1_1:计算分子(乘积)
CREATE TABLE table_cov AS
SELECT item1, item2,sum(score_prod) AS prod
FROM
(SELECT t1.item AS item1, t2.item AS item2, t1.score*t2.score as score_prod
FROM table_origin_data t1
INNER JOIN
table_origin_data t2
ON t1.user=t2.user)
GROUP BY item1, item2;
-- step1_2:计算余弦相似度
CREATE TABLE table_corr AS
SELECT t1.item1, t1.item2, t1.prod/SQRT(t2.prod*t3.prod) AS corr FROM
table_cov t1
INNER JOIN table_cov t2
ON t1.item1=t2.item1 AND t1.item1=t2.item2
INNER JOIN table_cov t3
ON t1.item2=t3.item1 AND t1.item2=t3.item2;
原理其实不难想。还是画图解释一下,下面是第一个SQL:  这就得到了两两乘积。
这就得到了两两乘积。
然后,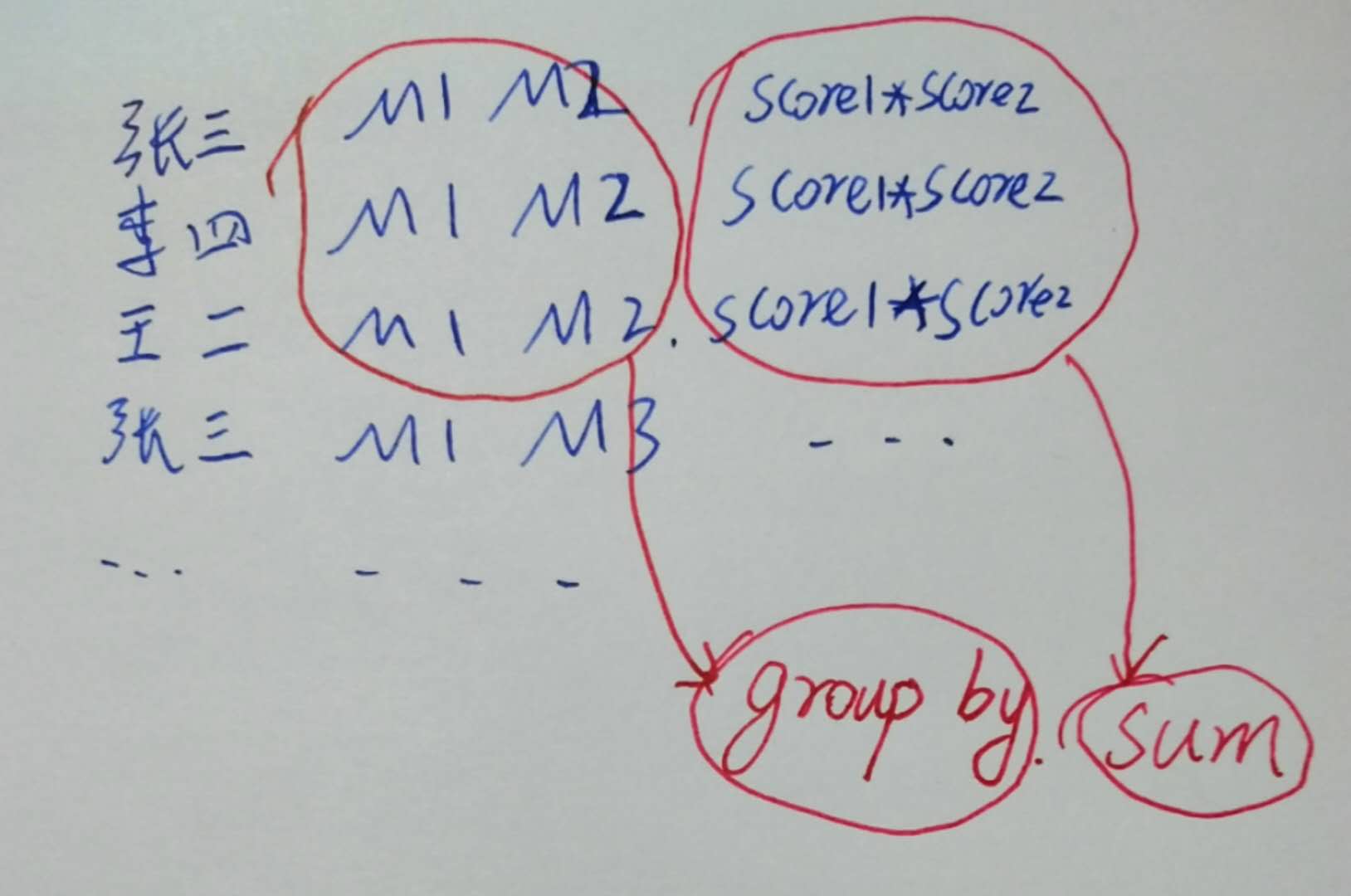
如此,第一个SQL就算出了余弦相似度的分子。
然后观察到分母其实也是某种分子,
$\cos(A, B)=\dfrac{a_1b_1+a_2b_2+…+a_nb_n}{\sqrt{(a_1a_1+a_2a_2+…+a_na_n)(b_1b_1+b_2b_2+…+b_n*b_n)}}$
所以第二个SQL也很好理解了。
step3:协同过滤
-- step3_1:先做一个待预测的列表(笛卡尔积,然后减去已有的)
CREATE TABLE table_unkown AS
SELECT t1.user, t2.item
FROM
(SELECT DISTINCT user, 1 AS joiner
FROM table_origin_data) t1
INNER JOIN
(SELECT DISTINCT item, 1 AS joiner
FROM table_origin_data) t2
ON t1.joiner=t2.joiner
LEFT ANTI JOIN
table_origin_data t3
ON t1.user=t3.user AND t2.item=t3.item
;
-- step3_2:最终结果
SELECT user, item, SUM(score) AS score
FROM (
SELECT t1.user, t1.item, t2.score*t3.corr AS score
FROM table_unkown t1
INNER JOIN table_origin_data t2
ON t1.user=t2.user
INNER JOIN table_corr t3
ON t1.item=t3.item1 AND t2.item=t3.item2
)
GROUP BY user, item;
进一步改进
对于 step1 计算相关性的过程,我们发现可以分布计算和增量计算 table_cov 这个表
对于 step2:
- 计算完相关性后,可以对于每个 item,只保留 TOP K,这样可以大大简化计算。
- 计算时,可以设定user和item的分数固定为1,进一步大大简化计算















 732
732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









