







集成学习是一种对多个子学习器进行组合的策略。
在机器学习问题中,我们需要解决的一大问题是:偏差(bias)和方差(variance)之间的平衡(trade off),前者致力于解决模型的准确性,而后者致力于追求模型的稳定性。而集成学习能够在两方面均有所益处:
对于某些差异较大的子学习器,其能够起到降低方差、提高预测结果稳定性的作用;而对于某些单个功能较弱的子学习器,其又能提高总体学习器的预测正确性,从而改善偏差。因此,集成学习的合理、正确使用能够有效的提高整体模型的上限,在各类数据比赛中也广为使用。
设
g
1
,
g
2
,
.
.
.
g
m
,
.
.
.
g
M
g_1,g_2,...g_m,...g_M
g1,g2,...gm,...gM为一组子学习器,所谓的集成学习即通过某种组合方式合并成一个最终的学习器:
G
(
x
)
=
∑
m
=
1
M
α
m
g
m
(
x
)
G(x)=\sum\limits_{m=1}^M\alpha _mg_m(x)
G(x)=m=1∑Mαmgm(x)这是一种典型的加法模型,各子学习器前的系数(也可以理解为组合策略)可以是:
1)常数1,其效果类似于各子学习器结果的简单平均。在分类问题上,即为简单投票,票多者为最终结果;在回归问题上,即为简单的平均值。
2)不同的系数,其效果类似于子各学习器结果基础上的加权平均。在分类问题上,即为加权投票,加权结果最大者为最终结果;在回归问题上,为加权平均数。
3)与预测样本相关的某个函数
α
(
x
)
\alpha(x)
α(x),可以理解为各子学习器的选择与否以及选择程度是与样本特征存在某种映射关系,或者直接理解为某种条件概率模型(以样本特征为条件)。
按照各子学习器是否相同(同基),学习器可分为同质学习器和异质学习器。按照各学习器预测能力的强弱,又可分为强学习器和弱学习器。对于各种学习器,有不同的集成选择倾向:
1)同质强学习器。可采用投票、线性组合和函数加权等各种形式的集成方式。比如直接投票出结果、bagging策略,而决策树则是函数加权的一种典型应用。
2)同质弱学习器。通过线性组合模式,往往可以得到“三个臭皮匠,胜过一个诸葛亮”的奇效。而boosting框架的使用,更是可以将一个弱基学习器逐步提升为强学习器。
3)异质强学习器。可采用投票、线性组合等方式进行集成。
4)异质弱学习器。也可采用投票、线性组合等方式进行集成。
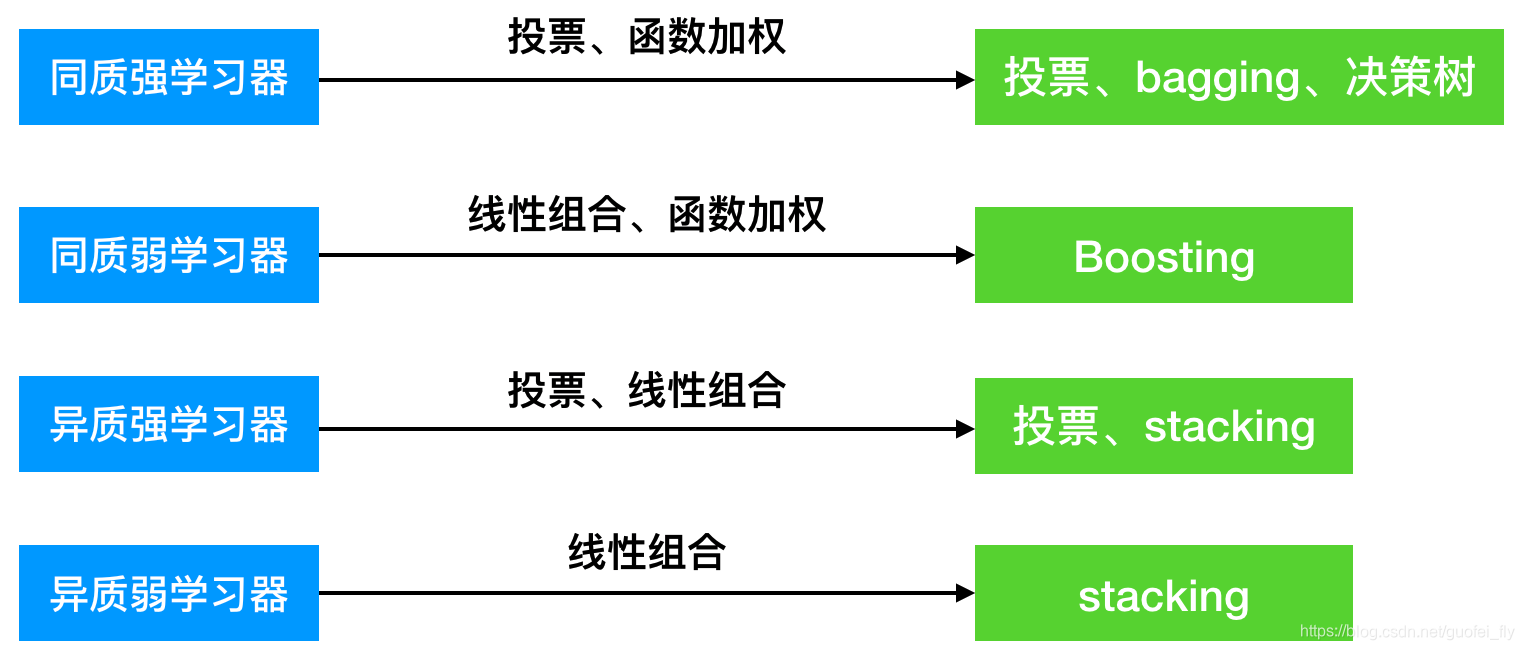
无论对于哪种子学习器,为了保证集成的效果,我们都希望其有一定的差异性。
从上可见,集成学习主要解决两个问题:
问题一:如何学得这些子学习器,使得子学习器间有所差异?
问题二:如何将这些子学习器进行组合。
如果现在手头已经有一堆现成的子学习器,那么问题可以变得很简单:通过投票(其实也包括硬投票、概率投票等多种技巧)或取平均达到简单的集成效果。
但在实际情况中,往往只有一堆数据。那只能通过边学习、边集成的方式开展集成学习了。这也就是后面要介绍的bagging、boosting和stacking三种常用的集成学习策略。
一、bagging策略
bagging是Bootstrap Aggregation的缩写,亦即建立在Bootstrap采样方法基础上的模型混合方法。
1.1 Bootstrap
所谓的Bootstrap,即有放回的随机采样,即基本过程为:
- 选取总的样本集 D D D,其中总共有 N N N个样本
- 每次采样1个样本,并有放回的采样 m m m次,得到一个完整的子样本集 D 1 D_1 D1
- 重复步骤2抽样 M M M次,从而得到 M M M个组样本集
在每一组子样本集中,某个样本始终没有被抽中的概率为: ( 1 − 1 N ) m (1-\frac{1}{N})^m (1−N1)m易得,当样本量大(趋近于 + ∞ +\infin +∞),取样次数再多,也有近似 1 e ≈ 0.368 \frac{1}{e} \approx0.368 e1≈0.368的样本始终未被采样得到。这些数据被称为袋外数据(Out of bag)
对于每一组子样本集,分别训练模型。最终对各模型的预测结果进行某种平均或折中:对于分类问题,可选择各分类器预测分类次数最多的那个分类作为最终结果;而对于回归问题,可选择最终预测结果的平均值作为最终结果。
以上便是bagging策略的基本过程:(1)Bootstrap采集多组子数据集;(2)对每组子数据集分别训练一个子模型;(3)对每个子模型的结果进行平均。
1.2 OOB-score
在bagging策略中,由于存在未放入训练模型的部分OOB数据,所以往往无须单独划分验证集来进行模型超参数的validation,而使用OOB-score(模型在OOB数据上的表现)来对某个bagging后的整体模型进行评价。
上文提及,在理想状态下,每个样本有0.368的几率未被抽到。但实际的训练数据规模性,纵观整个 M M M组Bootstrap过程,可能未能被所有模型所采样的数据并不多。因此,往往对每个子模型的OOB进行分别评价,再取平均值,即: S c o r e o o b = ∑ i = 1 M S c o r e o o b _ i n _ m o d e l _ i Score_{oob}=\sum\limits_{i=1}^M Score_{oob\_in\_ model \_i} Scoreoob=i=1∑MScoreoob_in_model_i
1.3 更一般的随机性
bagging的核心思想和成功之道在于采样阶段数据的随机性,可以使得基于数据的模型的多样性。我们可以将这种随机性在整个模型训练流程中进行推广:
1)数据的随机性:如给数据添加一些随机噪声
2)采样阶段的随机性:如bootstrap,或者有偏向性的选择某些数据(如后面的Adaboost算法)
3)特征选择的随机性:每个子模型训练所用特征也遵循一定的随机性
4)模型参数的随机性:随机确定一些模型的超参数
这些随机性增加了模型的多样性,可能会使得模型的泛化能力更强。
二、boosting策略
前面提及,集成算法的中心思想是想办法将若干组子学习器进行组合。 G ( x ) = ∑ m = 1 M α m g m ( x ) G(x)=\sum\limits_{m=1}^M\alpha _mg_m(x) G(x)=m=1∑Mαmgm(x)对于bagging框架而言,这是个并行的过程,即各子学习器之间是弱相关的,可以并行学习再组合。
而在boosting思想中,模型的组合可以视为一个串行的逐步学习提高的过程。即
G
t
(
x
)
=
G
t
−
1
(
x
)
+
α
t
g
m
(
x
)
G_t(x)=G_{t-1}(x)+\alpha_tg_m(x)
Gt(x)=Gt−1(x)+αtgm(x)每步在先前学习器的基础上,采用某种策略学习一个子学习器,而最终的决策模型就是这些学习器的线性叠加。因此,boosting框架中主要需要求解的就是:
1)如何根据前序学习器
g
t
−
1
(
x
)
g_{t-1}(x)
gt−1(x),学习一个有明显区分度的新的子学习器
g
t
(
x
)
g_t(x)
gt(x);
2)如何确定这些子学习器进行线性组合的线性系数
α
t
\alpha_t
αt
2.1 调整样本权重的boosting
一种思想是:在每轮子学习器的训练时,充分考虑前序自学习器在数据集上的表现,通过调整错误样本的权重,以保证该子学习器能够充分吸收错误样本的教训,并训练出区分度较大的模型。
其典型算法为Adaboost算法。
2.2 确定模型改善方向的boosting
另一种思想是:在每轮子学习器的训练时,通过求解模型损失函数在前序学习器上的误差在子模型方向上的导数,从而利用函数导数的性质找到能使得损失梯度下降最快的子学习器方向和学习率。
这也是梯度提升法(Gradient Boosting)的核心思想。
鉴于,这两种典型的Boosting算法都值得详细的数学推导和深刻的思想理解,所以会在后续文章中详细介绍。
三、stacking策略
将子学习器进行组合的过程视为一个新的线性模型的学习过程,这就是stacking策略的核心思想。
G
(
x
)
=
∑
m
=
1
M
α
m
g
m
(
x
)
=
M
o
d
e
l
(
g
m
(
x
)
;
α
m
)
G(x)=\sum\limits_{m=1}^M\alpha _mg_m(x)=Model(g_m(x);\alpha_m)
G(x)=m=1∑Mαmgm(x)=Model(gm(x);αm)
stacking是一个两层的学习模型。
第一层:选择区分度明显的模型,对原始数据进行学习,并同时将原始训练数据(通过cross-validation避免信息泄露)和测试集数据进行预测。在stacking的框架下,可将这些子学习器视为特征转换器(feature transformer),其目的就是提取从数据中提取出能反映数据潜在模式的特征信息;
第二层:在上述特征转换数据的基础上,再训练一层模型,作为最后的输出模型。
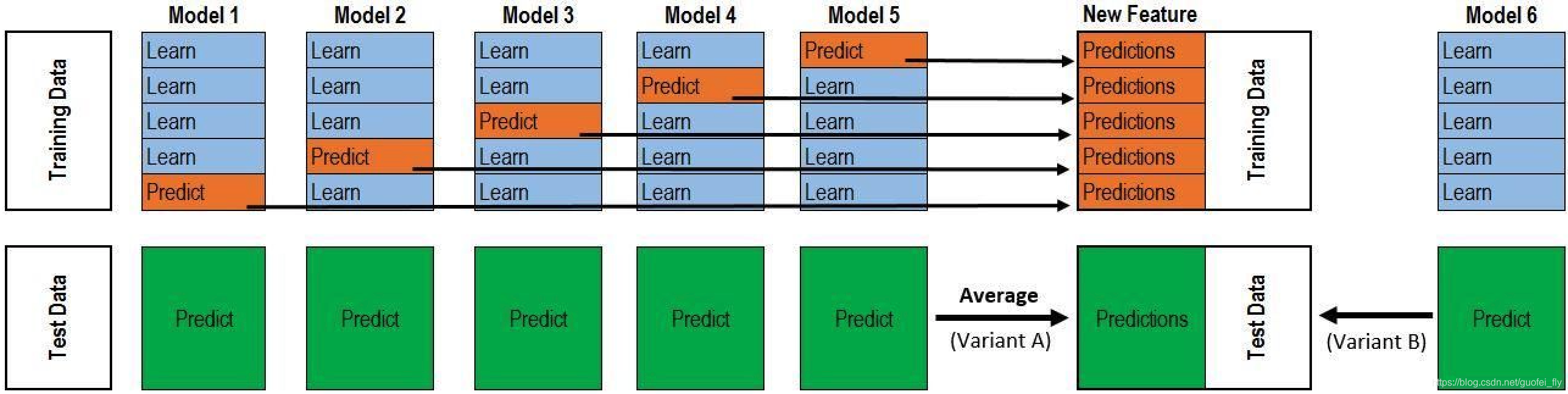
stacking框架的典型流程图如下图,其具体流程总结如下:
1)将数据集分为训练集和测试集。
2)在训练集上,对每个子学习器进行cross-validation学习,并根据每一折得到的最优模型在对应验证集上进行预测,从而可以得到全量训练集的预测值,作为后续模型的一维特征。以5折交叉验证为例,每次选出不重复的4份训练集,1份验证集,在4份训练集上训练出局部最优模型,并将此模型在1份验证集进行预测;这样交叉学习5次得到5个局部最优模型,就可以对应5份验证集(也就是全量训练集)上的全部预测值;
3)在测试集上,用这5个局部最优模型分别进行预测,然后取均值,就可以得到全量测试集上对应的1维预测值;
4)重复步骤2和步骤3学习
M
M
M个子学习器,将这些预测值进行组合,从而可以得到具有
M
M
M维度特征的训练集和测试集。
5)在新的数据集(预测标签
Y
Y
Y仍为原始标签)和测试集基础上,训练出第二层的学习器。
四、小结
针对模型集合的总体目标,bagging、boosting和stacking分别从并行学习、串行学习和层次学习的角度提出了不同的解决方案。各种组合框架的优劣和模型改善程度视不同的任务不同,需要进行尝试和对比得到更有解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









