







Tips:
本文章只是简单介绍了一下HiQA的三步走流程,对于具体的如果针对表格、图片做相应的处理,还需要深入原论文。
paper link: https://ar5iv.labs.arxiv.org/html/2402.01767
code: https://github.com/TebooNok/HiQA?tab=readme-ov-file
Motivation
The standard RAG struggles to address the massive indistinguishable documents problem.
标准的RAG流程无法解决大量具有相似结构的多文档问答问题。需要加入层级信息。
目标
解决 retrieval problem for multi-documents with similar structures.
核心方法(三步走)
- Markdown Formatter (MF)
- Hierarchical Contextual Augmentor (HCA)
- Multi-Route Retriever (MRR)

Markdown Formatter (MF)
The MF module processes the source document, converting it into a markdown file which is a sequence of segments. Rather than dividing the document into fixed-size chunks, each segment corresponds to a natural chapter within the document, comprising both chapter metadata and content. (这一步利用LLM实现) 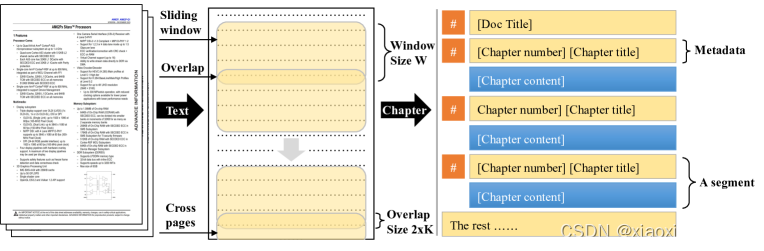
Hierarchical Contextual Augmentor (HCA)
HCA module extracts the hierarchical metadata from the markdown and combines it, forming cascading metadata, thereby augmenting the information of each segment.(级联元数据嵌入过程)
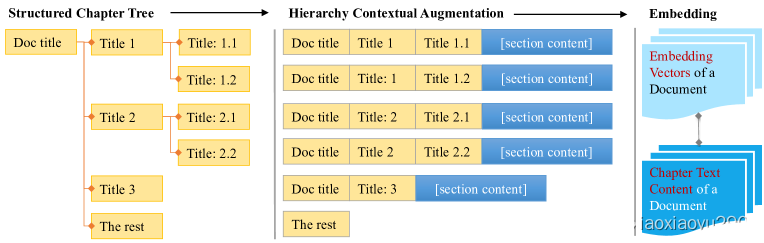
Multi-Route Retriever (MRR).
The MRR module employs a Multi-Route retrieval approach to find the most suitable segments, which are then provided as context inputs to the Language Model.
- Vector similarity matching
- Elastic search Elastic(Elasticsearch弥补了基于向量的匹配在单词级精度上的局限性)
- Keyword matching(关键字匹配则利用了文档语料库中固有的关键词,以解决Elasticsearch的局限性,Elasticsearch主要依赖于统计方法来控制单词权重,所以可能会忽略一些重要的keywors)
这三种方法在检索语义级信息时逐渐减弱,在检索字符级信息时逐渐增强,它们的功能互为补充,因此,我们把它们组合在一起使用:

|C|表示匹配到的关键词的数量- α \alpha α: balance the contribution of vector similarity
- β \beta β: balance the information retrieval scores
更多信息详见here















 4579
4579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









