







 本文详细探讨了Transformer模型在训练和推理阶段的内存消耗,包括模型自身占用、activations(注意力和MLP块)、optimizer states。以Mixtral-8x22B为例,强调了activations在内存中的重要性,并指出优化器如AdamW在微调时增加的内存需求。推理和训练时的内存消耗与序列长度、批次大小和模型参数有关。对于大规模模型,内存管理至关重要。
本文详细探讨了Transformer模型在训练和推理阶段的内存消耗,包括模型自身占用、activations(注意力和MLP块)、optimizer states。以Mixtral-8x22B为例,强调了activations在内存中的重要性,并指出优化器如AdamW在微调时增加的内存需求。推理和训练时的内存消耗与序列长度、批次大小和模型参数有关。对于大规模模型,内存管理至关重要。
文章目录
上一篇文章提到了llama 3 8b 全量微调需要占用 Fine-tuning内存占用128.87GB的内存,主要包括三方面,分别是:
- loading the model
- optimizer states
- activations
本文以Mixtral-8x22B为例来介绍各个阶段的内存消耗以及推理和训练时的内存消耗。
各阶段内存消耗
model 自身占用内存
要想知道模型有多少个参数,直接查看模型卡片即可
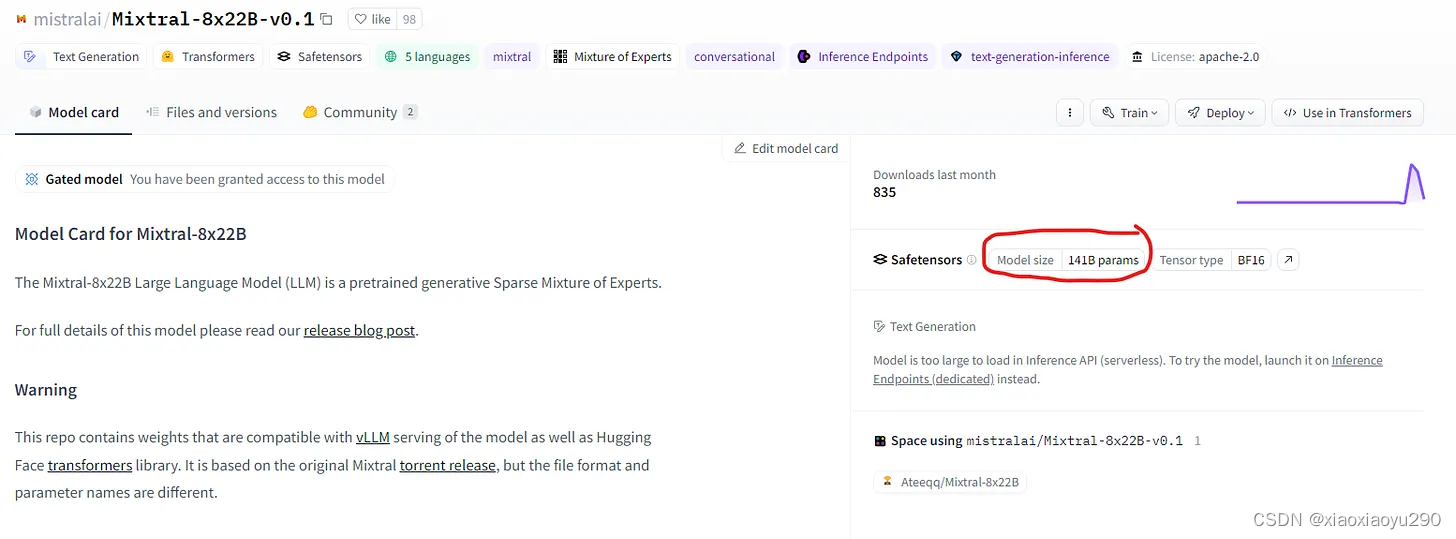
如果想在GPU上进行快速推理,就需要将模型完全加载到GPU内存中。对于“Command-R”需要193.72 GB的GPU显存;对于Mixtral-8x22B来说需要有262.63 GB的GPU内存;对于Llama 3 70B型号,其拥有131.5 GB的GPU内存(每个参数占用16 bit,即 2 bytes)
activations的内存消耗(重点)
首先需要知道以下信息:
- max_seq_len,记为s
- hidden_size,记为h
- attention head的数量,记为a
- layer number,记为l
标准的transformer block如下:
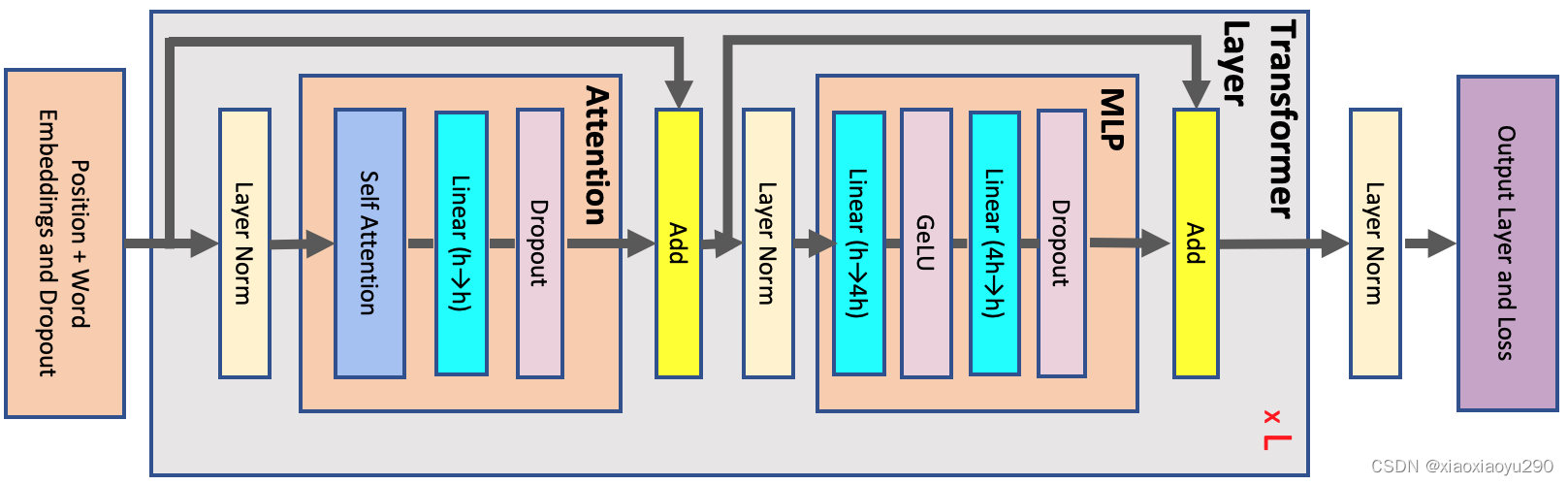
At the start of the network, the input tokens are fed into a word embedding table with size
v×h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









