






目标检测 pytorch复现RetinaNet目标检测项目
该论文的主要创新点与效果提升点在于采用的Focal Loss分类损失函数,有效的缓解了正负样本不均衡的问题
pytorch复现项目源代码:https://download.csdn.net/download/guoqingru0311/87734522
模型介绍

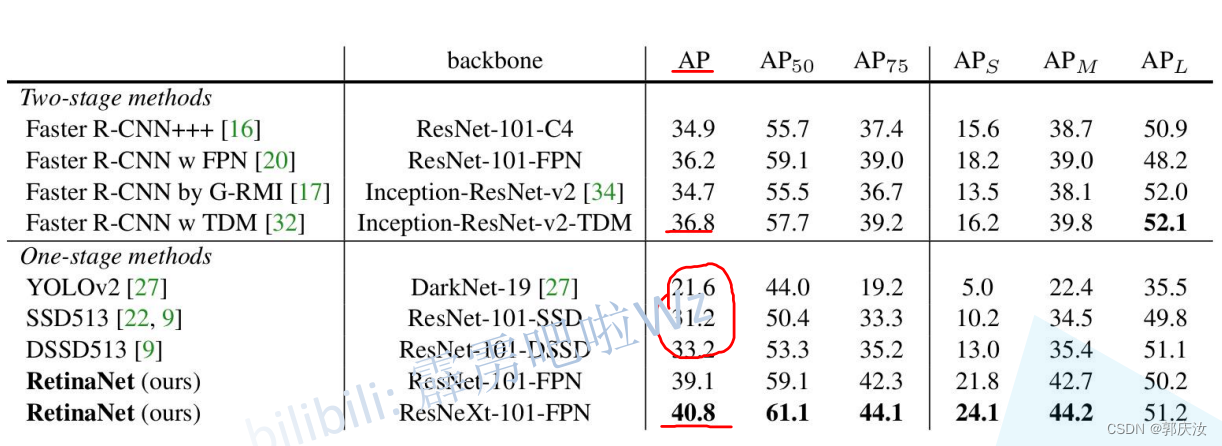
网络backbone使用ResNet【18, 34, 50, 101, 152】
FPN层介绍与anchor设定
首先输入的照片的大小为640x640, 然后经过一个池化层, 使用ResNet网络提取特征,得到四个不同尺度的特征图,layer1, layer2, layer3,layer4.源代码中的尺度融合是从layer2层开始。然后再经过尺度融合得到f3, f4, f5, f6, f7五个不同尺度的特征层。
model.py代码
import torch.nn as nn
import torch
import math
import torch.utils.model_zoo as model_zoo
from torchvision.ops import nms
from retinanet.utils import BasicBlock, Bottleneck, BBoxTransform, ClipBoxes
from retinanet.anchors import Anchors
from retinanet import losses
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
class PyramidFeatures(nn.Module):
def __init__(self, C3_size, C4_size, C5_size, feature_size=256):
super(PyramidFeatures, self).__init__()
# upsample C5 to get P5 from the FPN paper
self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P5 elementwise to C4
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P4 elementwise to C3
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1)
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)
def forward(self, inputs):
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
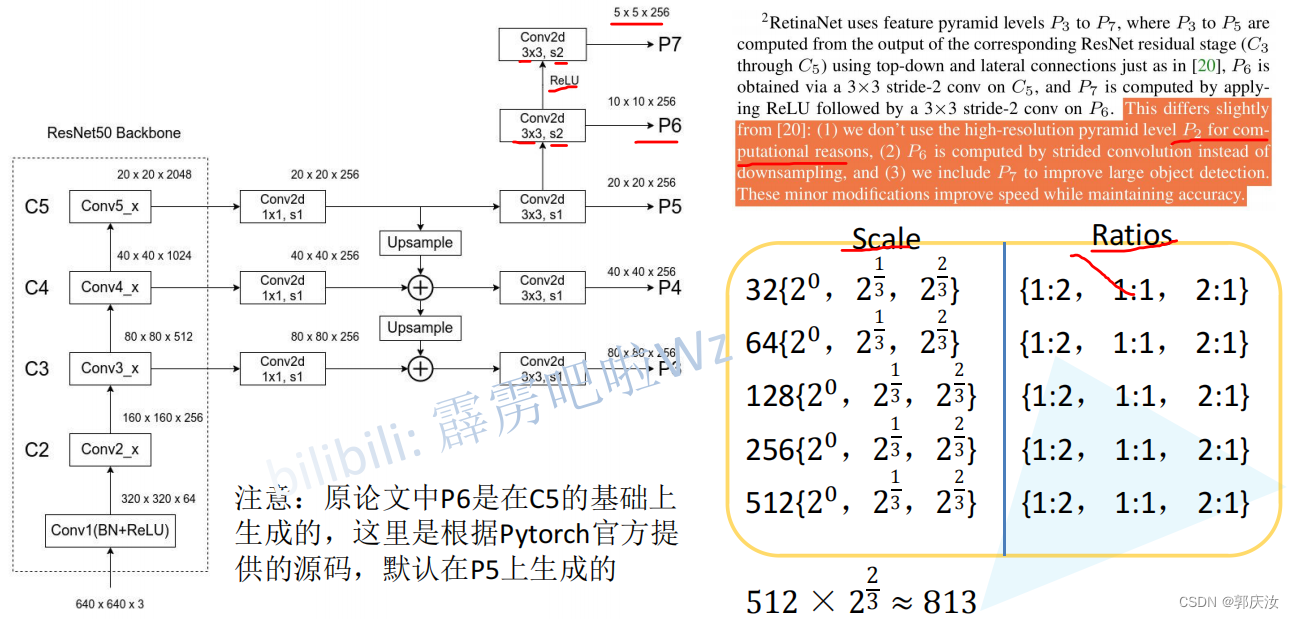
class RegressionModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, feature_size=256):
super(RegressionModel, self).__init__()
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
# out is B x C x W x H, with C = 4*num_anchors
out = out.permute(0, 2, 3, 1)
return out.contiguous().view(out.shape[0], -1, 4)
class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
super(ClassificationModel, self).__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
out = self.output_act(out)
# out is B x C x W x H, with C = n_classes + n_anchors
out1 = out.permute(0, 2, 3, 1)
batch_size, width, height, channels = out1.shape
out2 = out1.view(batch_size, width, height, self.num_anchors, self.num_classes)
return out2.contiguous().view(x.shape[0], -1, self.num_classes)
class ResNet(nn.Module):
def __init__(self, num_classes, block, layers):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2])
self.regressionModel = RegressionModel(256)
self.classificationModel = ClassificationModel(256, num_classes=num_classes)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.focalLoss = losses.FocalLoss()
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
prior = 0.01
self.classificationModel.output.weight.data.fill_(0)
self.classificationModel.output.bias.data.fill_(-math.log((1.0 - prior) / prior))
self.regressionModel.output.weight.data.fill_(0)
self.regressionModel.output.bias.data.fill_(0)
self.freeze_bn()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()
def forward(self, inputs):
if self.training:
img_batch, annotations = inputs
else:
img_batch = inputs
x = self.conv1(img_batch)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
features = self.fpn([x2, x3, x4])
regression = torch.cat([self.regressionModel(feature) for feature in features], dim=1)
classification = torch.cat([self.classificationModel(feature) for feature in features], dim=1)
anchors = self.anchors(img_batch) # 生成anchor
if self.training:
return self.focalLoss(classification, regression, anchors, annotations)
else:
transformed_anchors = self.regressBoxes(anchors, regression)
transformed_anchors = self.clipBoxes(transformed_anchors, img_batch)
finalResult = [[], [], []]
finalScores = torch.Tensor([]) # 置信度
finalAnchorBoxesIndexes = torch.Tensor([]).long() # 框体对应的分类的序号
finalAnchorBoxesCoordinates = torch.Tensor([]) # 框体坐标
if torch.cuda.is_available():
finalScores = finalScores.cuda()
finalAnchorBoxesIndexes = finalAnchorBoxesIndexes.cuda()
finalAnchorBoxesCoordinates = finalAnchorBoxesCoordinates.cuda()
for i in range(classification.shape[2]):
scores = torch.squeeze(classification[:, :, i])
scores_over_thresh = (scores > 0.05)
if scores_over_thresh.sum() == 0:
# no boxes to NMS, just continue
continue
scores = scores[scores_over_thresh]
anchorBoxes = torch.squeeze(transformed_anchors)
anchorBoxes = anchorBoxes[scores_over_thresh]
anchors_nms_idx = nms(anchorBoxes, scores, 0.5)
finalResult[0].extend(scores[anchors_nms_idx])
finalResult[1].extend(torch.tensor([i] * anchors_nms_idx.shape[0]))
finalResult[2].extend(anchorBoxes[anchors_nms_idx])
finalScores = torch.cat((finalScores, scores[anchors_nms_idx]))
finalAnchorBoxesIndexesValue = torch.tensor([i] * anchors_nms_idx.shape[0])
if torch.cuda.is_available():
finalAnchorBoxesIndexesValue = finalAnchorBoxesIndexesValue.cuda()
finalAnchorBoxesIndexes = torch.cat((finalAnchorBoxesIndexes, finalAnchorBoxesIndexesValue))
finalAnchorBoxesCoordinates = torch.cat((finalAnchorBoxesCoordinates, anchorBoxes[anchors_nms_idx]))
return [finalScores, finalAnchorBoxesIndexes, finalAnchorBoxesCoordinates]
def resnet18(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18'], model_dir='.'), strict=False)
return model
def resnet34(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34'], model_dir='.'), strict=False)
return model
def resnet50(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50'], model_dir='.'), strict=False)
return model
def resnet101(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101'], model_dir='.'), strict=False)
return model
def resnet152(num_classes, pretrained=False, **kwargs):
"""Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(num_classes, Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152'], model_dir='.'), strict=False)
return model
anchor.py代码
import numpy as np
import torch
import torch.nn as nn
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels] # 表示在特征图上移动一个像素,在原图上就移动2**x个单位
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels] # 表示金字塔每层特征图的大小
if ratios is None:
self.ratios = np.array([0.5, 1, 2]) # 宽高比
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]) # 尺度比例
def forward(self, image):
image_shape = image.shape[2:] # 获取到原图的宽与高
image_shape = np.array(image_shape)
# 求得针对每一个level都获得一个image_shape
# 相当于向上取整操作 (10+2-1)/2
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in self.pyramid_levels]
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
all_anchors = np.expand_dims(all_anchors, axis=0)
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))
def generate_anchors(base_size=16, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
num_anchors = len(ratios) * len(scales) # 每个像素位置生成的anchor的个数
# initialize output anchors
anchors = np.zeros((num_anchors, 4))
# scale base_size x,y,w,h
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T # np.tile(scales, (2, len(ratios))):表示将数据scales在行上重复两次,在列上重复len(ratios)次
# compute areas of anchors 得到九个面积
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
# area / (w / h) = h * h ==> h = sqrt(area / (w / h))
# ratio=w/h ==> w= ratio * h
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales))) # 得到宽度
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales)) # 得到高度
# transform from (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
def compute_shape(image_shape, pyramid_levels):
"""Compute shapes based on pyramid levels.
:param image_shape:
:param pyramid_levels:
:return:
"""
image_shape = np.array(image_shape[:2])
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in pyramid_levels]
return image_shapes
def anchors_for_shape(
image_shape,
pyramid_levels=None,
ratios=None,
scales=None,
strides=None,
sizes=None,
shapes_callback=None,
):
image_shapes = compute_shape(image_shape, pyramid_levels)
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4))
for idx, p in enumerate(pyramid_levels):
anchors = generate_anchors(base_size=sizes[idx], ratios=ratios, scales=scales)
shifted_anchors = shift(image_shapes[idx], strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
return all_anchors
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchors
特征预测层与回归层
正负样本的匹配问题

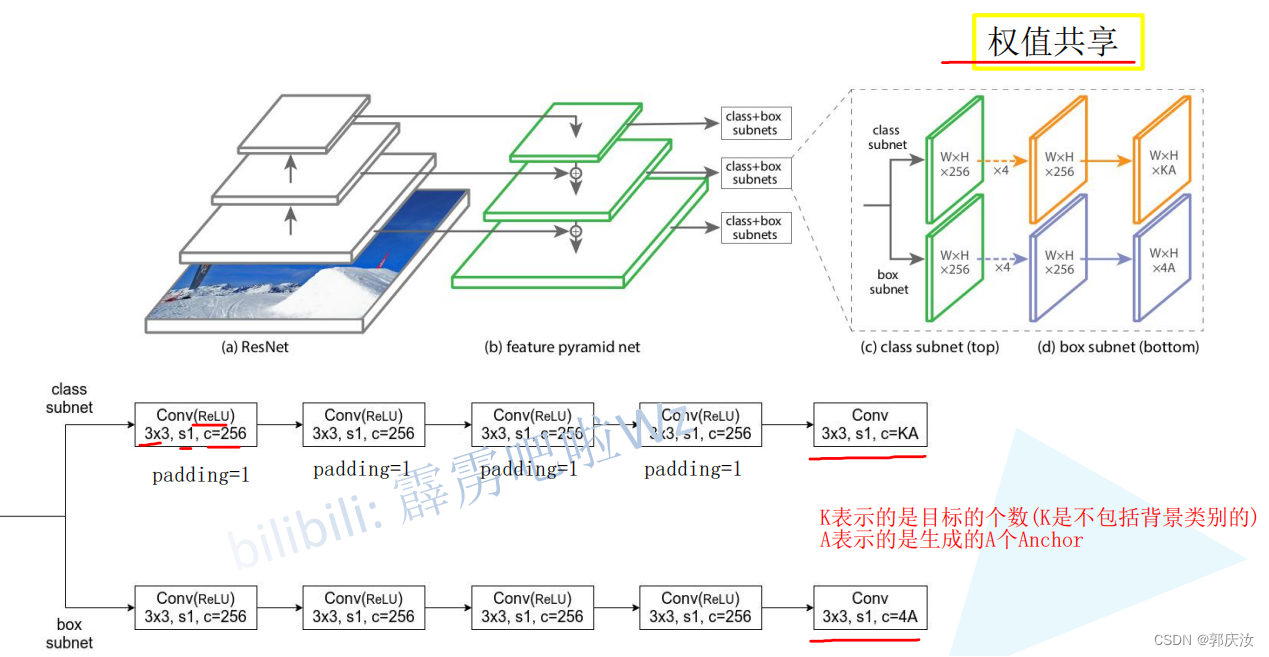
损失函数设定
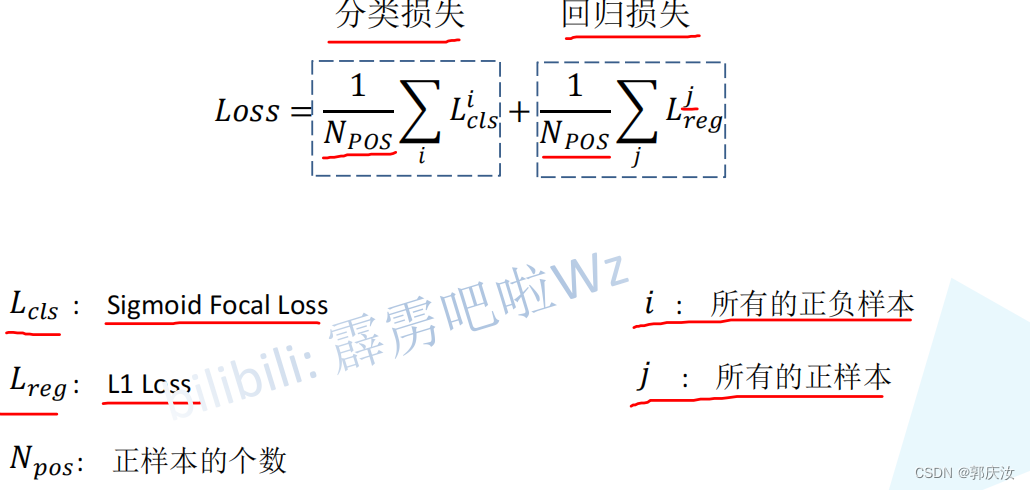
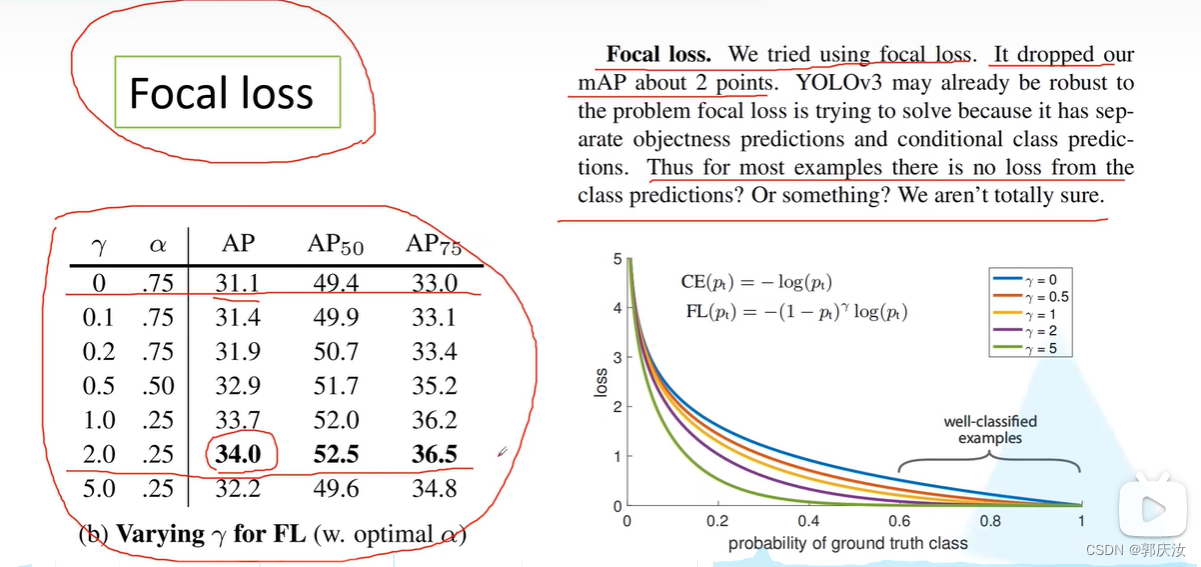
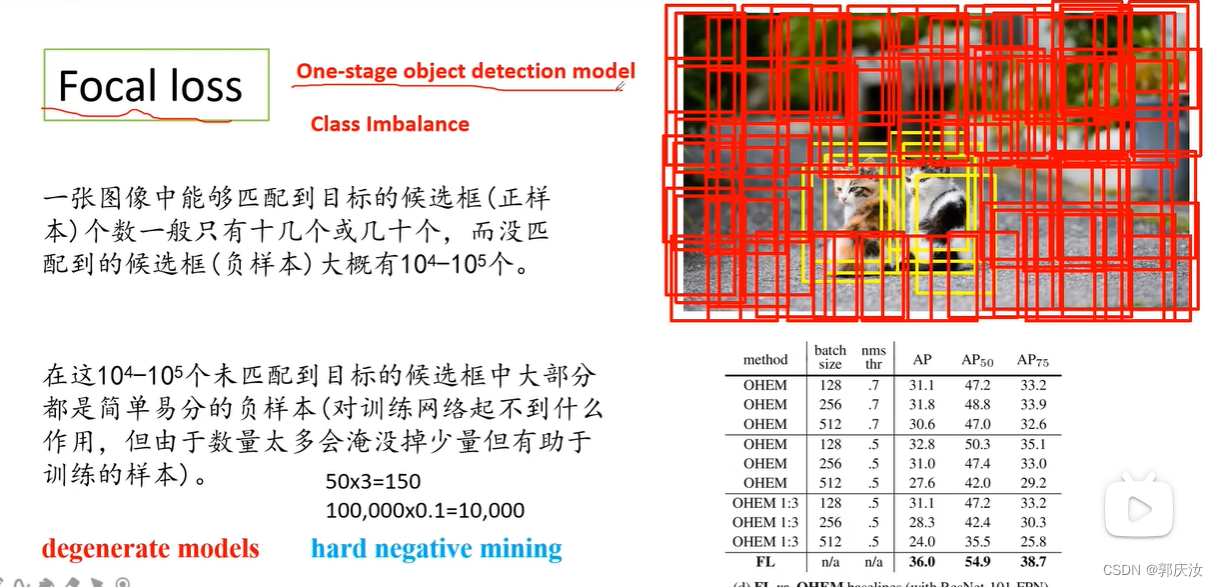
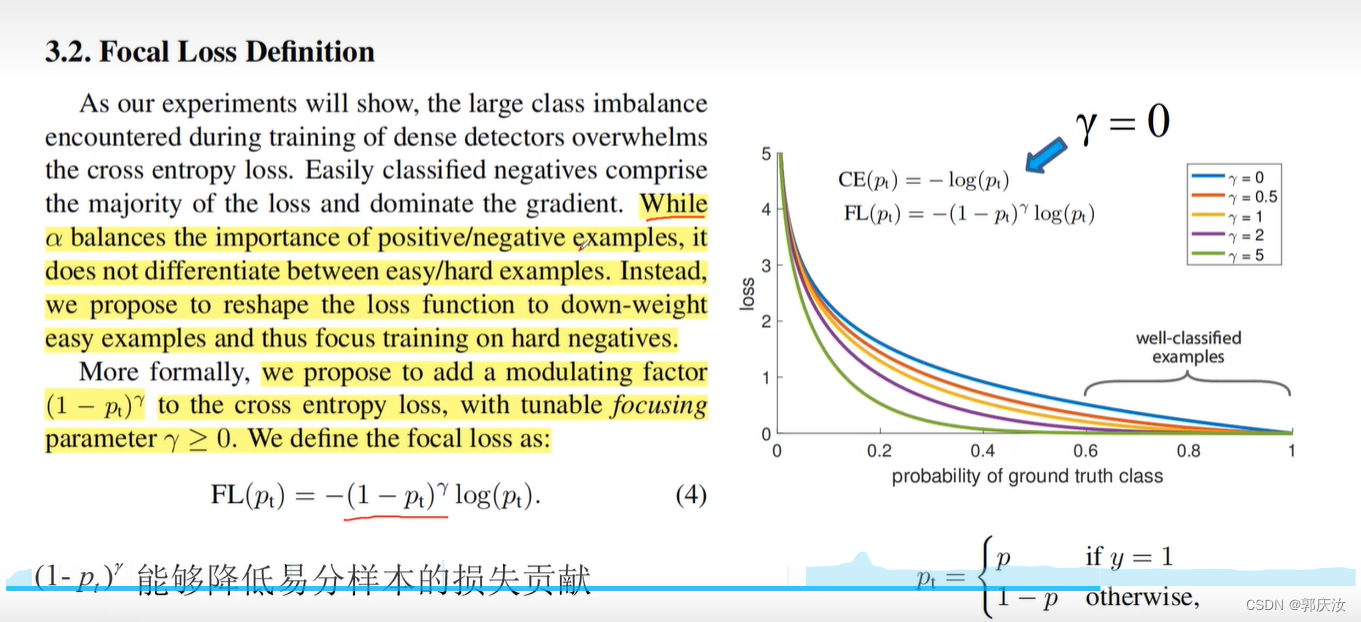
Focal Loss
公式表示:
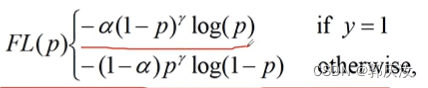



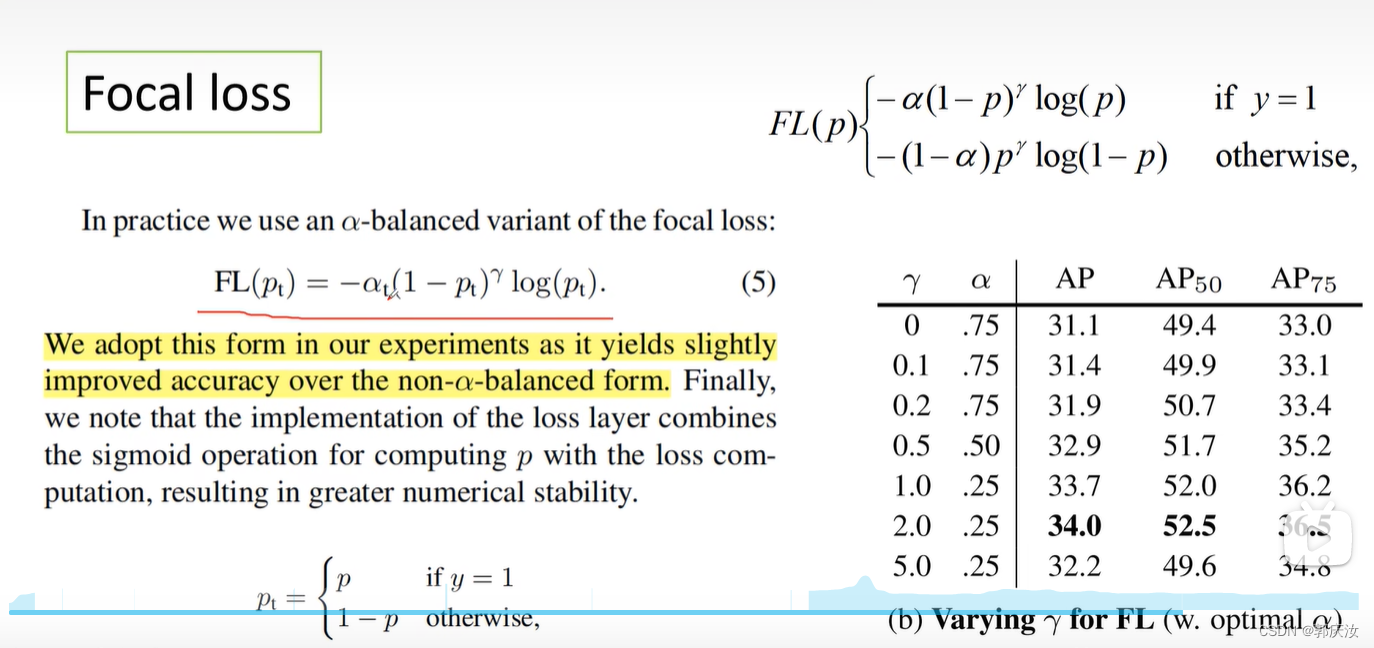
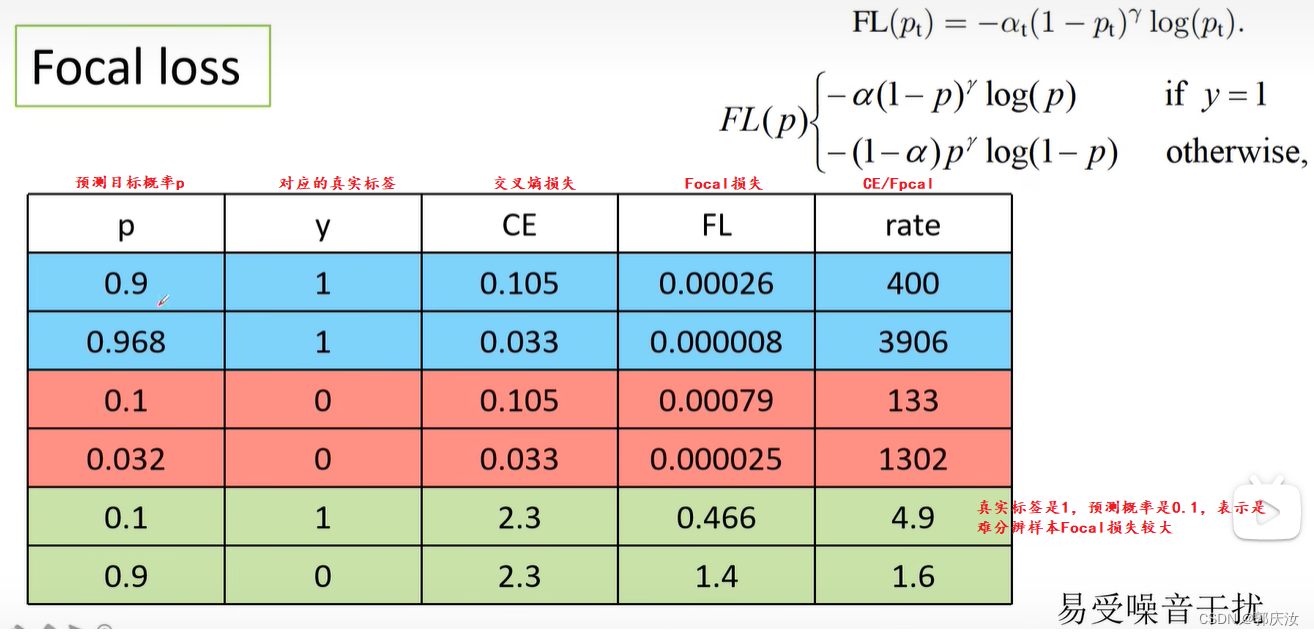


import numpy as np
import torch
import torch.nn as nn
def calc_iou(a, b):
area = (b[:, 2] - b[:, 0]) * (b[:, 3] - b[:, 1])
iw = torch.min(torch.unsqueeze(a[:, 2], dim=1), b[:, 2]) - torch.max(torch.unsqueeze(a[:, 0], 1), b[:, 0])
ih = torch.min(torch.unsqueeze(a[:, 3], dim=1), b[:, 3]) - torch.max(torch.unsqueeze(a[:, 1], 1), b[:, 1])
iw = torch.clamp(iw, min=0)
ih = torch.clamp(ih, min=0)
ua = torch.unsqueeze((a[:, 2] - a[:, 0]) * (a[:, 3] - a[:, 1]), dim=1) + area - iw * ih
ua = torch.clamp(ua, min=1e-8)
intersection = iw * ih
IoU = intersection / ua
return IoU
class FocalLoss(nn.Module):
#def __init__(self):
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
batch_size = classifications.shape[0]
classification_losses = [] # 分类loss
regression_losses = [] # 回归loss
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0]
anchor_heights = anchor[:, 3] - anchor[:, 1]
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights
for j in range(batch_size):
classification = classifications[j, :, :] # 获得针对某张图像的分类结果 二维[anchor个数,类别数]
regression = regressions[j, :, :] # 获得针对某张图像的回归结果
bbox_annotation = annotations[j, :, :]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1] # 把类别不为-1的box挑选出来
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0: # 如果这张图内没有ground truth目标框
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
IoU_max, IoU_argmax = torch.max(IoU, dim=1) # num_anchors x 1
#import pdb
#pdb.set_trace()
# compute the loss for classification
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
targets[torch.lt(IoU_max, 0.4), :] = 0 # 背景
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))
# compute the loss for regression
## 计算回归损失
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# clip widths to 1
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0, keepdim=True)


















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









