







本博客主要参考了《How to Generate a Good Word Embedding?》。既然我的研究方向是使用深度模型来进行自然语言处理,那么了解一些典型的词向量生成策略还是十分有必要的。正好借着这篇论文,我把常见的词向量生成策略进行一个总结。
所有的词向量生成策略都基于这样的假设:语义上相近的词语具有相似的上下文语义环境,这也是所有神经网络语言模型构造的基础。( words that occur in similar contexts tend to have similar meanings )
影响word2vector训练效果的主要因素:
1 model
2 corpus (大小、领域)
3 training parameter
不同的model主要有两个方面的不用:
1 the relationship between the target word and its context
2 the representation of the context.
从大类来说,主要有以下几大类的词向量生成策略
1 神经网络模型,即建模
p(wi|wi−1,wi−2,wi−3)
,词向量是语言模型的附属产品。
首先是Bengio提出的NNLM(作为神经网络系列语言模型的开山鼻祖,所有后面大部分的语言模型都是根据其改造的)
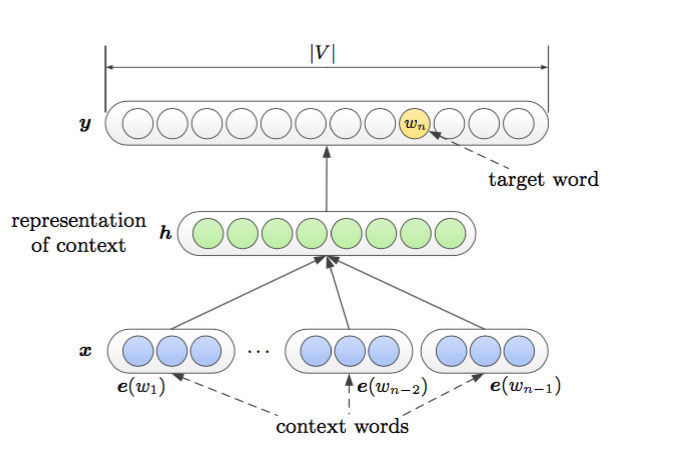
其中e(w1)是对于词语的特征向量映射
正如论文里所说的“A language model utilizes several previous words to predict the distribution of the next word. This model uses a concatenation of the previous words’ embeddings as the input:”
x=[e(w1),e(w2)...e(wn−1)]
h=tanh(d+Hx)
H∈Rh∗|e|∗(n−1)
e
是词向量的维度
y=b+Uh+Wx
W∈RV∗|e|∗(n−1)
U∈Rh∗|e|∗(n−1)
有时候为了简化上式,拿掉了输入到输出的边,即
y=b+Uh
把所有的词按照顺序contact起来构成该模型的输入向量,h作为非线性隐层,y是输出。这个模型参数比较多,模型比较复杂,特别是在非线性隐层部分。
其实最终来说,整个模型生成了两套词向量,一个是输入词向量,维度为|e|,代表了上下文信息;另一个是输出词向量,维度为|h|,代表了目标词语的信息。一般来说,我们默认使用的是输入词向量,其实完全可以把输出词向量的信息和输入词向量的结合起来,也许会有不错的效果。
Word2vector模型(Google 大牛Mikolov )提出的一种简单的语言模型,就是简单的把上面复杂模型中的非线性隐层去掉了,同时为了加快训练的速度忽略了上下文词语的出现顺序。
一般来说有两种训练策略,cbow和skip-gram。
cbow网络结构:
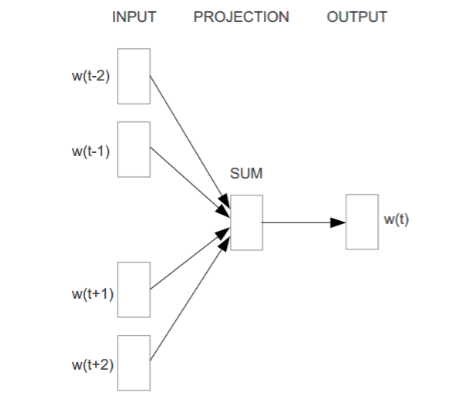
当前词语wi的上下文用wi周围的词语简单加起来代替。
skip-gram网络结构:
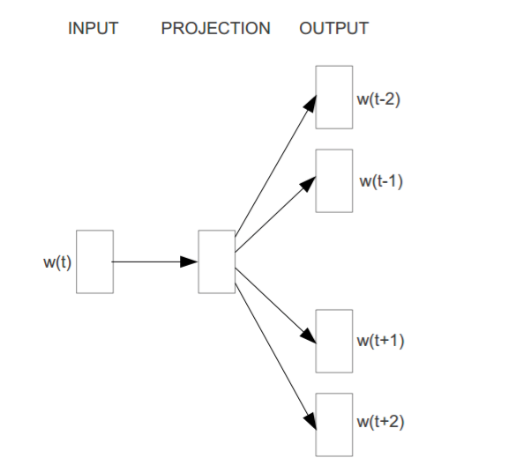
当前词语wi的上下文用wi周围的词语分别一个个抽出来代替。
在优化方面采用层次softmax或者负采样。
层次softmax就是首先把所有的词语用huffman进行编码,这样每一个词语都对应唯一的二进制01串。这样从根节点都当前的词语wi所在节点,就对应一个二进制串,即对应了很多二分类的问题。
负采样就是把当前wi作为是正样本,负样本随机从词库中抽取,只要不是当前的词语都是负样本。
循环神经网络语言模型(RNNLM)
其实我们在对上下文进行表示的时候,完全可以使用RNN,即每一个时刻的隐层状态
hi
代表了词语
i
之前的所有语义信息。剩下的部分可以参照前面的模型进行预测。
模型如下:

2 不再借助语言模型模型,直接生成词向量
C&W模型
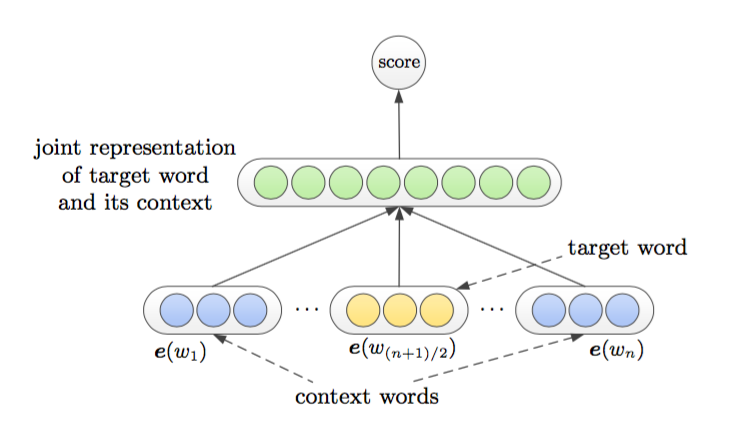
这种模型是把目标词语和上下文直接结合在了一起,然后score它们。这种结合模型中使用的把它们的词向量直接concat在一起,那么模型的目标函数就最大化正确序列的分数,最小化错误序列的分数(所谓的错误序列就是把正确序列中的target word随机的替换成一个词语),那么综合来看它们就是在最小化下面的式子:
它们构成一个pair进行训练。
3 基于矩阵的分布模型
GLOVE模型
We propose a specific weighted least squares model that trains on global word-word co-occurrence counts and thus makes efficient use of statistics.
不同于上面的模型,上面的模型都只是使用了局部的信息,而glove模型则是先统计所有词语的共现概率即
Let the matrix of word-word co-occurrence counts be denoted by X, whose entries Xij tabulate the number of times word j occurs in the context of word i.
即j在含有i的文本中,且距离i的距离在预先设定的共现窗口内,则认为j在含有i的文本中出现了。
其目标函数是从全局角度出发的,一共能生成两套词向量分别是wi和wj(上面有波浪线的),其实最后真正应用的时候是把这两类向量加起来,效果会比单一的好。(个人感觉如果word2vector也使用了这种方法,说不定性能还能提升)
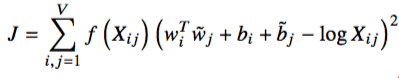
f(xi,j)
函数是权值函数,衡量后面误差的重要性
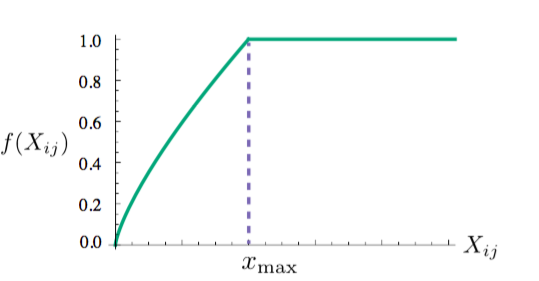
从本质上来说,这种模型也没有考虑到词之间的顺序关系,(因为只要是在共现窗口内的词,不管距离多远都认为是共现的)。
他吹自己比word2vector强的原因在于利用了全文本词语的统计信息。
但是我感觉word2vector采用多次扫描文本统计窗口内的词语的方式其实和glove先统计词语的共现概率是很相似的,(如果使用glove统计出两个词语共现概率很高,那么当word2vector去扫描全文的时候,这两个词将会比其他词更多的被扫描到),因此这种方法不应该比word2vector强太多,之所以在论文《GloVe: Global Vectors for Word Representation 》他们的实验得glove优于word2vector的结论,是因为他们的实验上glove采用多次迭代,而word2vector采用1次迭代,(只不过每次选用的负采样的个数不同),即对比实验有问题。















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









