







这两天重新回顾了一下batch-normalization技术,主要参考了论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》与大牛张俊林的博客:http://blog.csdn.net/malefactor/article/details/51476961。不对的地方还望大家指正。
说白了,BN的提出还是为了克服深度神经网络难以训练的弊病,虽然论文里一直在强调他是为了解决“Internal Covariate Shift”这个问题,但是我觉得这只是论文为了显示包装自己而引入的概念。如果从算法本身的角度来分析原因的话,我觉得它真正起作用的原因是:1 防止“梯度弥散”;2 使用了scale和shift参数使新构建的网络拥有了更强的表征能力(至少新的解空间包含了之前的解空间); 3 消除了向量各个维度之间量纲的影响,可以适当的增加learing rate,加快了训练速度。从操作方式来看batch-normalization技术,其实就是把每一层的输入向量的每一维特征进行归一化(减去均值,除以标准差),是不能像论文说的那样保证不同batch中的数据满足同一分布的(只是均值同为0,方差同为1)。
首先我们来详细地讲解一下batch-normalization的工作机制。
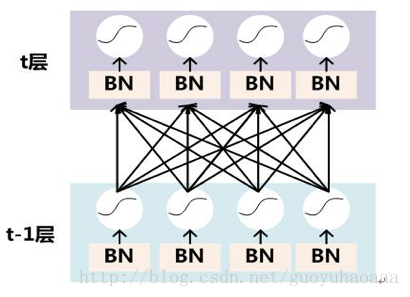
如上图所示,BN的使用位置是在每一层输出的激活函数之前。
y=WX+b
,
X
代表了每一层的输入,那么Y就是经过线性变换之后与激活函数之前的部分。
batch-normalization的训练流程如下:
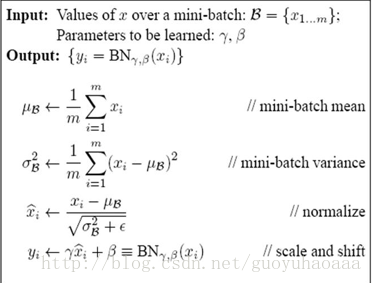
batch-normalization的推理流程如下:
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例。解决方案其实很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量。
在CNN结构中使用batch-normalization技术
论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》中给出了一种参考方式:由于在CNN网络结构中,同一个filter map共享权值,故在进行batch-normalization操作的时候也要延续这种思想,同一个filter map共享一组期望、方差、scale和shift。以二维卷积为例,对于batch size为m,卷积结果为p*q的filter来说,他的有效统计量为m*p*q。
其实batch-normalization从广义上来说更像是一种思想,可以用在任意的机器学习算法之中。基于其特征归一化的特性,一般可以用在像神经网络这样采用stacking方式组合在一起的算法结构。
batch-normalization作用分析
论文里作者用了一系列的实验来说明这种算法的优势,总结来说就是下面三点:
1 加快了模型的训练速度(可以使用更大的learing rate)
2 起到了部分正则化的效果
3 提高了分类的效果
论文中作者的实验都是在图像分类上,现在目前来看还没有人用在文本分析领域。我曾经在文本分类领域使用这种技术,我的发现是:如果在浅层次网络中使用这种技术,对最后的结果影响不大,会稍微加快了一点训练速度;而很深的网络还没有在文本分类领域中提出来,我自己曾经胡乱的根据图像处理的深层次卷积神经网络构造了文本处理网络(20层),如果不使用batch-normalization技术那么这个网络几乎无法收敛,而使用了该技术之后,网络的收敛速度大大加快了。至于说最后的效果嘛,呵呵,可能是我构造的方式不对,也可能是更深的网络压根就不适合在文本处理领域,反正最后的结果相对于浅层次的网络并没有明显的提升。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









