







一、综述
ResNet(Residual Networks,残差网络),论文——Deep Residual Learning for Image Recognition(下载地址:https://arxiv.org/pdf/1512.03385.pdf),是MSRA(微软亚洲研究院)的何凯明(http://kaiminghe.com/)团队设计的。在2015年ImageNet上大放异彩。在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且该论文也获得了CVPR2016的best paper,实在是实至名归。
ResNet最根本的动机就是所谓的退化(degradation)问题,即当模型的层次加深时,错误率却提高了,如下图:
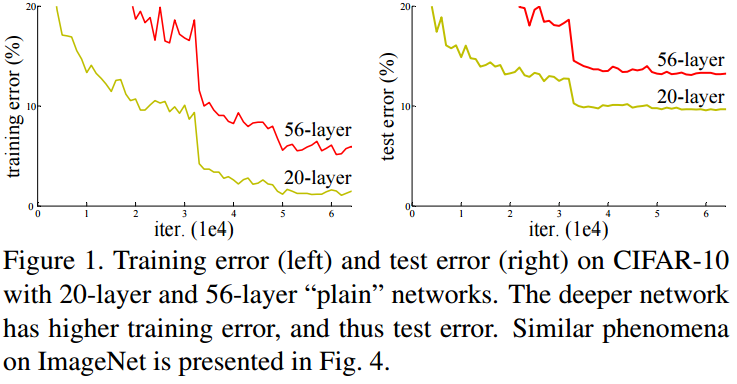
一般认为,随着模型的深度加深,学习能力增强,即更深的模型不应当产生比它更浅的模型更高的错误率。上图表面:常规的网络的堆叠(plain network)在网络很深的时候,效果却越来越差了。这里其中的原因之一即是网络越深,梯度消失的现象就越来越明显。
针对这个问题,作者提出了一个Residual的结构:
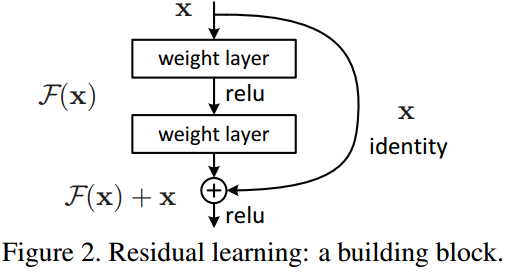
通过在输出个输入之间引入一个shortcut connection(可以翻译为越层链接),而不是简单的堆叠网络,这样可以解决网络由于很深出现梯度消失的问题,从而可可以把网络做的很深。ResNet其中一个网络结构如下图所示 :
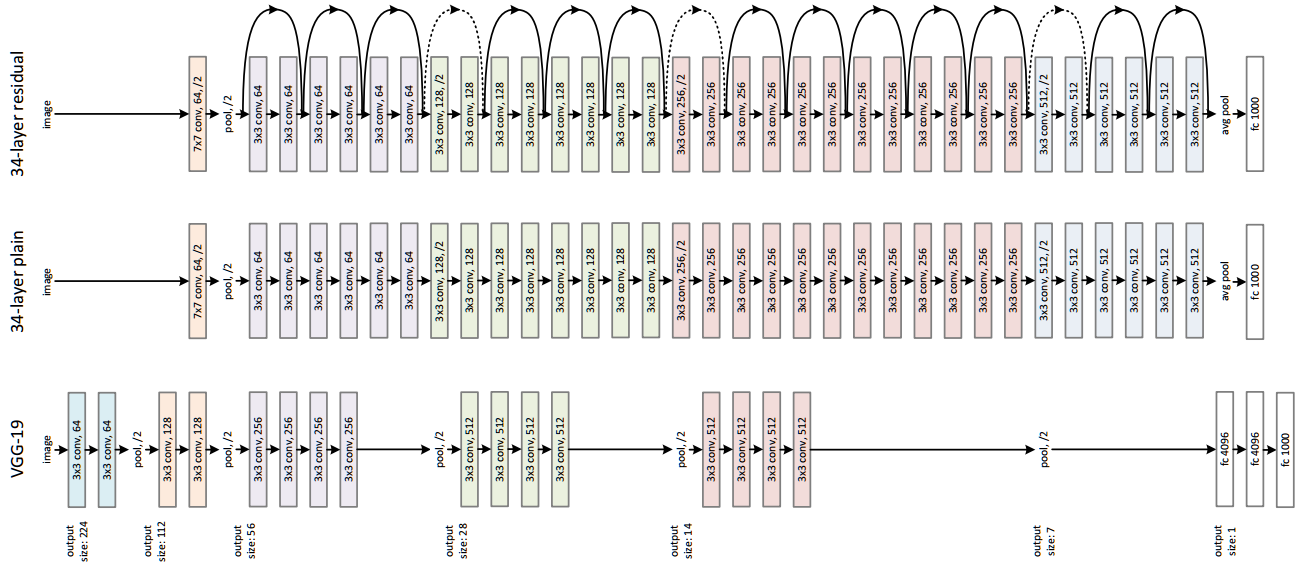
最下边的是VGG-19网络,中间为Plain Network,最上边的是基于Plain Network构建的ResNet网络。Plain Network 主要是受 VGG 网络启发,主要采用3*3滤波器,遵循两个设计原则:
- 对于相同输出特征图尺寸,卷积层有相同个数的滤波器
- 如果特征图尺寸缩小一半,滤波器个数加倍以保持每个层的计算复杂度。通过步长为2的卷积来进行降采样。一共34个权重层。
可以看到,ResNet网络就是在传统的顺序堆叠网络上增加了shortcut connection。ResNet的shortcut connection可以这样理解:
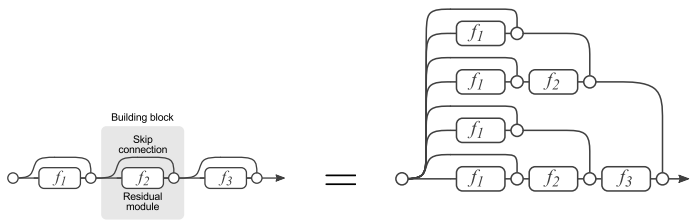
残差网络单元其中可以分解成右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。下面来说明为什么可以这样理解:
如果把残差网络理解成一个Ensambling系统,那么网络的一部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该适合删除的残差单元的个数成正比的,论文里的结论也印证了这个猜测。
ResNet残差学习模块现在也有很多种,甚至可以根据项目要求自己定义。下图显示的就是两层和三层对应的学习模块:

二、论文核心
ResNet的核心内容之一,即“Deeper Bottleneck Architectures”(以下简称DBA),论文里的原图是这样的:
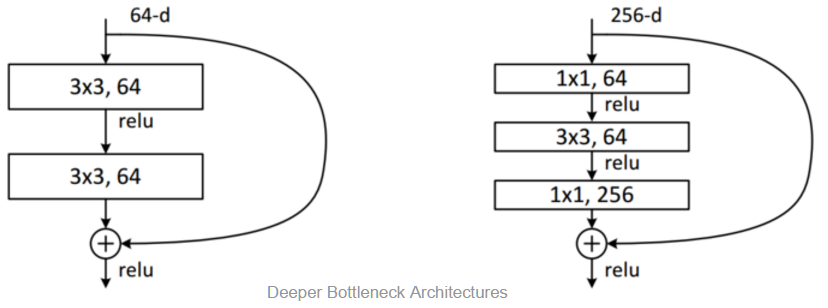
然后我们再看一下原作中的ResNet全貌:
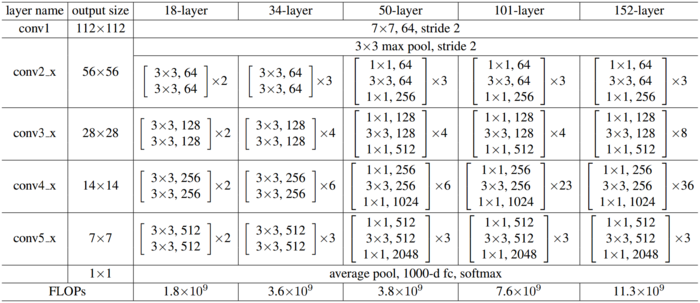
上图以50-layer为例:在进入DBA之前,比较简单:
①卷积层"7×7, 64, stride 2"、
②BN层、
③ReLU层、
④池化层"3×3 max pool, stride 2"
接下来有四个DBA,拿最上一个DBA为例,其内部具体结构如下图:

三、Tensorflow silm实现(前向)
#coding:utf-8
import collections
import tensorflow as tf
import time
import math
from datetime import datetime
slim = tf.contrib.slim
#定义了一个block类
class Block(collections.namedtuple('Bolck', ['scope', 'init_fn', 'args'])):
'A named tuple describing a ResNet block.'
#定义了一个下采样函数
def subsample(inputs, factor, scope = None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride = factor, scope = scope)
#定义conv2d_same函数创建卷积层
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope = None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, \
stride = 1, padding = 'SAME', \
scope = scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, \
stride = stride, padding = 'VALID', \
scope = scope)
#定义堆叠blocks的函数
#@这个符号用于装饰器中,用于修饰一个函数,把被修饰的函数作为参数传递给装饰器
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections = None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' %(i + 1), values = [net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net, depth = unit_depth,
unit_depth_bottleneck = unit_depth_bottleneck,
stride = unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
#创建ResNet通用的arg_scope
def resnet_arg_scope(is_training = True,
weight_decay = 0.0001,
batch_norm_decay = 0.997,
batch_norm_epsilon = 1e-5,
batch_norm_scale = True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer = slim.l2_regularizer(weight_decay),
weights_initializer = slim.variance_scaling_initializer(),
activation_fn = tf.nn.relu,
normalizer_fn = slim.batch_norm,
normalizer_params = batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding = 'SAME') as arg_sc:
return arg_sc
#定义bottleneck残差学习单元
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections = None, scope = None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank = 4)
preact = slim.batch_norm(inputs, activation_fn = tf.nn.relu, scope = 'preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact,
depth,
[1, 1],
stride = stride,
normalizer_fn = None,
activation_fn = None,
scope = 'shortcut')
residual = slim.conv2d(preact,
depth_bottleneck,
[1, 1],
stride = 1,
scope = 'conv1')
residual = conv2d_same(residual,
depth_bottleneck,
3,
stride,
scope = 'conv2')
residual = slim.conv2d(residual,
depth,
[1, 1],
stride = 1,
normalizer_fn = None,
activation_fn = None,
scope = 'conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
#定义生成ResNet V2主函数
def resnet_v2(inputs,
blocks,
num_classes = None,
global_pool = True,
include_root_block = True,
reuse = None,
scope = None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse = reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections = end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn = None, normalizer_fn = None):
net = conv2d_same(net, 64, 7, stride = 2, scope = 'conv1')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'pool1')
net = stack_blocks_dense(net, blocks)
net = slim.batch_norm(net, activation_fn = tf.nn.relu, scope = 'postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name = 'pool5', keep_dims = True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn = None, normalizer_fn = None, scope = 'logits')
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope = 'predictions')
return net, end_points
#定义50层的ResNet
def resnet_v2_50(inputs,
num_classes = None,
global_pool = True,
reuse = None,
scope = 'resnet_v2_50'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 1024, 1)] * 3)]
return resnet_v2(inputs,
blocks,
num_classes,
global_pool,
include_root_block = True,
reuse = reuse,
scope = scope)
#定义101层的ResNet
def resnet_v2_101(inputs,
num_classes = None,
global_pool = True,
reuse = None,
scope = 'resnet_v2_101'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs,
blocks,
num_classes,
global_pool,
include_root_block = True,
reuse = reuse,
scope = scope)
#定义152层的ResNet
def resnet_v2_152(inputs,
num_classes = None,
global_pool = True,
reuse = None,
scope = 'resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs,
blocks,
num_classes,
global_pool,
include_root_block = True,
reuse = reuse,
scope = scope)
#定义200层的ResNet
def resnet_v2_200(inputs,
num_classes = None,
global_pool = True,
reuse = None,
scope = 'resnet_v2_200'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs,
blocks,
num_classes,
global_pool,
include_root_block = True,
reuse = reuse,
scope = scope)
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(), info_string, num_batches, mn, sd))
batch_size = 32
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training = False)):
net, end_points = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, "Forward")四、原生TensorFlow实现
import skimage.io # bug. need to import this before tensorflow
import skimage.transform # bug. need to import this before tensorflow
import tensorflow as tf
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.training import moving_averages
from config import Config
import datetime
import numpy as np
import os
import time
MOVING_AVERAGE_DECAY = 0.9997
BN_DECAY = MOVING_AVERAGE_DECAY
BN_EPSILON = 0.001
CONV_WEIGHT_DECAY = 0.00004
CONV_WEIGHT_STDDEV = 0.1
FC_WEIGHT_DECAY = 0.00004
FC_WEIGHT_STDDEV = 0.01
RESNET_VARIABLES = 'resnet_variables'
UPDATE_OPS_COLLECTION = 'resnet_update_ops' # must be grouped with training op
IMAGENET_MEAN_BGR = [103.062623801, 115.902882574, 123.151630838, ]
tf.app.flags.DEFINE_integer('input_size', 224, "input image size")
activation = tf.nn.relu
def inference(x, is_training,
num_classes=1000,
num_blocks=[3, 4, 6, 3], # defaults to 50-layer network
use_bias=False, # defaults to using batch norm
bottleneck=True):
c = Config()
c['bottleneck'] = bottleneck
c['is_training'] = tf.convert_to_tensor(is_training,
dtype='bool',
name='is_training')
c['ksize'] = 3
c['stride'] = 1
c['use_bias'] = use_bias
c['fc_units_out'] = num_classes
c['num_blocks'] = num_blocks
c['stack_stride'] = 2
with tf.variable_scope('scale1'):
c['conv_filters_out'] = 64
c['ksize'] = 7
c['stride'] = 2
x = conv(x, c)
x = bn(x, c)
x = activation(x)
with tf.variable_scope('scale2'):
x = _max_pool(x, ksize=3, stride=2)
c['num_blocks'] = num_blocks[0]
c['stack_stride'] = 1
c['block_filters_internal'] = 64
x = stack(x, c)
with tf.variable_scope('scale3'):
c['num_blocks'] = num_blocks[1]
c['block_filters_internal'] = 128
assert c['stack_stride'] == 2
x = stack(x, c)
with tf.variable_scope('scale4'):
c['num_blocks'] = num_blocks[2]
c['block_filters_internal'] = 256
x = stack(x, c)
with tf.variable_scope('scale5'):
c['num_blocks'] = num_blocks[3]
c['block_filters_internal'] = 512
x = stack(x, c)
# post-net
x = tf.reduce_mean(x, reduction_indices=[1, 2], name="avg_pool")
if num_classes != None:
with tf.variable_scope('fc'):
x = fc(x, c)
return x
# This is what they use for CIFAR-10 and 100.
# See Section 4.2 in http://arxiv.org/abs/1512.03385
def inference_small(x,
is_training,
num_blocks=3, # 6n+2 total weight layers will be used.
use_bias=False, # defaults to using batch norm
num_classes=10):
c = Config()
c['is_training'] = tf.convert_to_tensor(is_training,
dtype='bool',
name='is_training')
c['use_bias'] = use_bias
c['fc_units_out'] = num_classes
c['num_blocks'] = num_blocks
c['num_classes'] = num_classes
inference_small_config(x, c)
def inference_small_config(x, c):
c['bottleneck'] = False
c['ksize'] = 3
c['stride'] = 1
with tf.variable_scope('scale1'):
c['conv_filters_out'] = 16
c['block_filters_internal'] = 16
c['stack_stride'] = 1
x = conv(x, c)
x = bn(x, c)
x = activation(x)
x = stack(x, c)
with tf.variable_scope('scale2'):
c['block_filters_internal'] = 32
c['stack_stride'] = 2
x = stack(x, c)
with tf.variable_scope('scale3'):
c['block_filters_internal'] = 64
c['stack_stride'] = 2
x = stack(x, c)
# post-net
x = tf.reduce_mean(x, reduction_indices=[1, 2], name="avg_pool")
if c['num_classes'] != None:
with tf.variable_scope('fc'):
x = fc(x, c)
return x
def _imagenet_preprocess(rgb):
"""Changes RGB [0,1] valued image to BGR [0,255] with mean subtracted."""
red, green, blue = tf.split(3, 3, rgb * 255.0)
bgr = tf.concat(3, [blue, green, red])
bgr -= IMAGENET_MEAN_BGR
return bgr
def loss(logits, labels):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss_ = tf.add_n([cross_entropy_mean] + regularization_losses)
tf.scalar_summary('loss', loss_)
return loss_
def stack(x, c):
for n in range(c['num_blocks']):
s = c['stack_stride'] if n == 0 else 1
c['block_stride'] = s
with tf.variable_scope('block%d' % (n + 1)):
x = block(x, c)
return x
# define a DBA(Deeper Bottleneck Architectures)
def block(x, c):
filters_in = x.get_shape()[-1]
# Note: filters_out isn't how many filters are outputed.
# That is the case when bottleneck=False but when bottleneck is
# True, filters_internal*4 filters are outputted. filters_internal is how many filters
# the 3x3 convs output internally.
m = 4 if c['vbottleneck'] else 1
filters_out = m * c['block_filters_internal']
shortcut = x # branch 1
c['conv_filters_out'] = c['block_filters_internal']
if c['bottleneck']:
with tf.variable_scope('a'):
c['ksize'] = 1
c['stride'] = c['block_stride']
x = conv(x, c)
x = bn(x, c)
x = activation(x)
with tf.variable_scope('b'):
x = conv(x, c)
x = bn(x, c)
x = activation(x)
with tf.variable_scope('c'):
c['conv_filters_out'] = filters_out
c['ksize'] = 1
assert c['stride'] == 1
x = conv(x, c)
x = bn(x, c)
else:
with tf.variable_scope('A'):
c['stride'] = c['block_stride']
assert c['ksize'] == 3
x = conv(x, c)
x = bn(x, c)
x = activation(x)
with tf.variable_scope('B'):
c['conv_filters_out'] = filters_out
assert c['ksize'] == 3
assert c['stride'] == 1
x = conv(x, c)
x = bn(x, c)
with tf.variable_scope('shortcut'):
if filters_out != filters_in or c['block_stride'] != 1:
c['ksize'] = 1
c['stride'] = c['block_stride']
c['conv_filters_out'] = filters_out
shortcut = conv(shortcut, c)
shortcut = bn(shortcut, c)
return activation(x + shortcut)
def bn(x, c):
x_shape = x.get_shape()
params_shape = x_shape[-1:]
if c['use_bias']:
bias = _get_variable('bias', params_shape,
initializer=tf.zeros_initializer)
return x + bias
axis = list(range(len(x_shape) - 1))
beta = _get_variable('beta',
params_shape,
initializer=tf.zeros_initializer)
gamma = _get_variable('gamma',
params_shape,
initializer=tf.ones_initializer)
moving_mean = _get_variable('moving_mean',
params_shape,
initializer=tf.zeros_initializer,
trainable=False)
moving_variance = _get_variable('moving_variance',
params_shape,
initializer=tf.ones_initializer,
trainable=False)
# These ops will only be preformed when training.
mean, variance = tf.nn.moments(x, axis)
update_moving_mean = moving_averages.assign_moving_average(moving_mean, mean, BN_DECAY)
update_moving_variance = moving_averages.assign_moving_average(moving_variance, variance, BN_DECAY)
tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_mean)
tf.add_to_collection(UPDATE_OPS_COLLECTION, update_moving_variance)
mean, variance = control_flow_ops.cond(c['is_training'], lambda: (mean, variance),
lambda: (moving_mean, moving_variance))
x = tf.nn.batch_normalization(x, mean, variance, beta, gamma, BN_EPSILON)
#x.set_shape(inputs.get_shape()) ??
return x
def fc(x, c):
num_units_in = x.get_shape()[1]
num_units_out = c['fc_units_out']
weights_initializer = tf.truncated_normal_initializer(
stddev=FC_WEIGHT_STDDEV)
weights = _get_variable('weights',
shape=[num_units_in, num_units_out],
initializer=weights_initializer,
weight_decay=FC_WEIGHT_STDDEV)
biases = _get_variable('biases',
shape=[num_units_out],
initializer=tf.zeros_initializer)
x = tf.nn.xw_plus_b(x, weights, biases)
return x
def _get_variable(name,
shape,
initializer,
weight_decay=0.0,
dtype='float',
trainable=True):
"A little wrapper around tf.get_variable to do weight decay and add to"
"resnet collection"
if weight_decay > 0:
regularizer = tf.contrib.layers.l2_regularizer(weight_decay)
else:
regularizer = None
collections = [tf.GraphKeys.VARIABLES, RESNET_VARIABLES]
# tf.get_variable()
# Gets an existing variable with these parameters or create a new one.
return tf.get_variable(name,
shape=shape,
initializer=initializer,
dtype=dtype,
regularizer=regularizer,
collections=collections,
trainable=trainable)
def conv(x, c):
ksize = c['ksize']
stride = c['stride']
filters_out = c['conv_filters_out']
filters_in = x.get_shape()[-1] # get_shape() return a tuple,tuple[-1] is the value of last element
shape = [ksize, ksize, filters_in, filters_out]
initializer = tf.truncated_normal_initializer(stddev=CONV_WEIGHT_STDDEV)
weights = _get_variable('weights',
shape=shape,
dtype='float',
initializer=initializer,
weight_decay=CONV_WEIGHT_DECAY)
return tf.nn.conv2d(x, weights, [1, stride, stride, 1], padding='SAME')
def _max_pool(x, ksize=3, stride=2):
return tf.nn.max_pool(x,
ksize=[1, ksize, ksize, 1],
strides=[1, stride, stride, 1],
padding='SAME')完整的Python代码GitHub:https://github.com/IreneLini94/tensorflow-resnet.git















 8117
8117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









