







 Bloom Filter是一种高效的Bit-Map方法,用于判断元素是否在一个集合中,允许极小的误报率。它通过使用多个哈希函数将元素映射到位数组,降低碰撞概率。Python实现中,哈希函数族通常基于MD5并设置种子,插入元素时将哈希值映射到位数组,检测元素时,若所有映射位置都是1则可能属于集合。
Bloom Filter是一种高效的Bit-Map方法,用于判断元素是否在一个集合中,允许极小的误报率。它通过使用多个哈希函数将元素映射到位数组,降低碰撞概率。Python实现中,哈希函数族通常基于MD5并设置种子,插入元素时将哈希值映射到位数组,检测元素时,若所有映射位置都是1则可能属于集合。
在做与Web爬虫有关的任务时,经常这样需要做这样的判断:对于新爬到的URL,我们需要判断这个新的URL是否已经在已有的URL集合中存在了。但是当已经存在的URL集合的数据量极其庞大时,这个存在性的判断工作就变得很有挑战性。
把这个问题抽象出来,就是说:现在需要一种算法(工具),帮助我们实现一种高效而准确的,元素在集合中的存在性判断。
为了解决上面说的这一类问题,人们从简入难,想出了很多办法:
将元素全部存在一个数据库中。判断存在性时,对整个数据库做线性扫描。显然,这种方法永远不会出错,但是时空效率都不高,时间上讲,线性时间复杂度;空间上讲,存储元素的数据库也相当大。
进一步,很容易想到可以用一些抗碰撞性较强的安全的哈希函数先对每个元素求取哈希值,在将这些哈希值存储到数据库中。如果单个元素的size比较大(至少是大于固定长度的哈希值),就能节省数据库本身的空间。这也是典型的以时间(增加了哈希值的计算)换取空间的做法。
紧接着,人们又在想,上面的方法当中对于查找的过程还都是O(n)的,有没有更快的,接近O(1)的方法。那么好了,散列表(哈希表)就派上了用场,用哈希值来决定元素存储的位置,很快就能查到那个位置有没有元素。当然,为了更节省空间,可以先求取哈希值,再用哈希值构成的集合做散列表。
其实3中已经是把某个元素映射到了某个位置上,只不过这个位置上保存的是元素本身或者哈希值,而这种关系完全可以只用计算机科学中最简洁的符号0,1来表示某个位置是否被映射了。
我们把最后这种方法叫做Bit-Map方法。今天要讲的Bloom Filter就是一中典型的Bit-Map方法。
Bloom Filter 的构造
上面的方法4,无论从时间,还是从空间的角度已经很优了。但是还有一个问题,那就是碰撞的问题,单个哈希函数计算得到哈希值,再把这个哈希值映射到一个二进制数组的某个位置上,就很有可能发生碰撞。但是,换个角度思考,如果我们能通过某种方式,极大程度上降低碰撞的概率,那么,即便依然还有小概率的碰撞可能,在工程实际中也是可以接受的。
误报率(False positive)
这里先补充一个概念:误报率(False positive),又叫假阳性
拿最开始讲的网页爬虫的问题来说,在建立BitMap时,如果发生碰撞,那我们就会认为新爬到的这个URL是已经存在于已有集合中了,而事实上,却是不存在的。这个意思抽象出来,就是把本来不存在的事物(False)误报为已存在事物(Positive)的错误率。在一般的应用场景中,有极小的误报率是可以被接受的。比如爬虫时,少爬几个网页并没有什么太大关系;医疗检查时,一个健康的人被医生误判我们患了某种疾病(False Positive),总比一个有病的人没有被检查出来(False Negative)要强得多。我们把后面一种情况称为假阴性,也就是“漏报”。
好,回归正题,通过上面的分析可知,碰撞在元素针对集合的存在性判断问题中,会导致误报率的发生,而误报率如果不大的话,对这个问题的影响也就不大。所以,当然可以设计一种方法,在降低碰撞概率的前提下,生成相应的bit串。
怎么降低碰撞概率呢?2个途径:
- 使用多个哈希,替代之前的单个哈希;
- 增大bit数组的长度。
基本结构
按照这2个思路,Bloom Filter应运而生。生成步骤如下:
选取 k 个哈希函数,记为
{h1,h2,…,hk} . 至于参数 k 的选择问题,我后面再说。假设现在有
n 个元素需要被映射到bit数组中,bit数组的长度是 m . 初始时,将m 位的bit数组的每个位置的元素都置为0。一样地,关于参数 m 的选择我之后说。现在,把这个
n 个元素依次用第1步选取的 k 个哈希函数映射到bit数组的位置上,bit数组被映射到的位置的元素变为1。显然,一个元素能被映射到k 个位置上。过程如图Fig.1所示,现在把元素集合 { x,y,z} 通过3个哈希函数映射到一个二进制数组中。最后,需要检查一个元素是否在已有的集合中时,同样用这 k 个哈希函数把要判断的元素映射到bit数组的位置上,只要bit数组被映射到的位中有一个位不是1,那一定说明了这个元素不在已有的集合内。如图Fig.1所示,检查
w 是否在集合中时,有一个哈希函数将 w 映射到了bit数组的元素为0的位置。
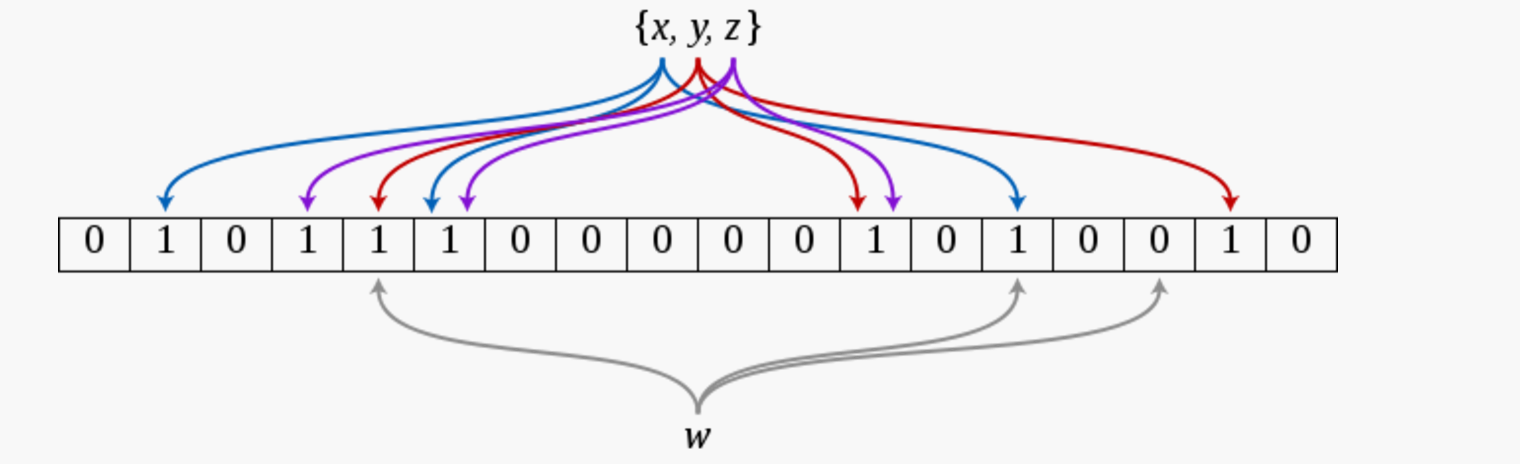
上面用的这张图是我盗的,感谢https://my.oschina.net/kiwivip/blog/133498这篇文章的作者。
参数选择
这一部分是整个Bloom Filter构造的核心内容,因为参数的选择直接决定了误报率的大小,从而直接影响准确性。
我们选择合适参数的目的,就是要降低误报率,所以先看看在什么情况下误报率最低:
- 假设bit数组
m 长,那么任意一个元素,被任意一个哈希函数映射到某一位的概率是平均的,都是 1m ,同理,没有被映射到的概率是 1−1m - 假设现在一共有 k 个不同的哈希函数,那么,bit数组的某一位能,经过这
k 个哈希函数还没有被这个元素映射到的概率是 (1−1m)k - 假设一共有 n 个元素需要被插入bit数组,那么插入
n 个元素后,对于bit数组的某一位来说,依然为0的概率是 (1−1m)nk ,换句话说,某一位为1的概率是: 1−(1−1m)nk - 假设现在对某个特定的元素存在误报,也就是说,这个元素经过 k 个哈希函数映射到的bit数组的
k 个位都是1,这个概率是: [1−(1−1m)nk]k ,换句话说,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









